【@deprecated】Hadoop3,IDEA远程访问集群进行调试,Scala+Java混合开发
文章目录
- 一、Hadoop3部分变化
- 1-1、擦除编码
- 1-2、Hadoop 3 端口号的改变
- 1-3、支持2个以上的NameNode
- 1-4、内部数据节点平衡器
- 二、IDEA远程访问控制集群
- 2-1 创建Maven项目,添加hadoop-client依赖
- 2-2 加入集群上的配置文件,准备本地环境
- 2-3、查看文件/目录
- 2-4、创建目录
- 2-5、上传本地文件
- 2-6、人生苦短,远离远程调试
- 三、混合开发、完整pom文件
- 3-1、直接安装scala sdk(推荐,省事)
- 3-2、 不安装scala sdk
- 3-3、pom
- 四、错误记录
- 参考
一、Hadoop3部分变化
标记下,找时间消化
1-1、擦除编码
https://hadoop.apache.org/docs/r3.0.3/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
1-2、Hadoop 3 端口号的改变
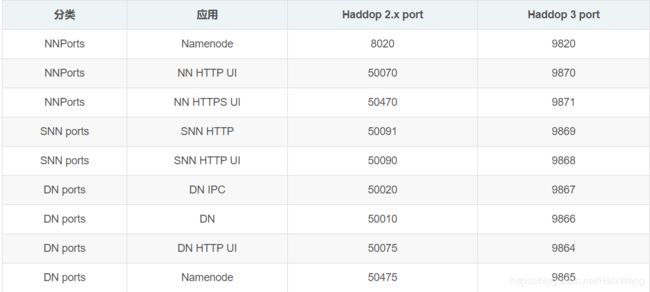
1-3、支持2个以上的NameNode
https://hadoop.apache.org/docs/r3.0.3/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
1-4、内部数据节点平衡器
添加或替换磁盘可能会导致DataNode中的数据倾斜,See the disk balancer section in the HDFS Commands Guide for more information
二、IDEA远程访问控制集群
2-1 创建Maven项目,添加hadoop-client依赖
问题:Dependency 'org.apache.hadoop:hadoop-client:3.0.0-cdh6.2.0' not found
解决:添加仓库
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
2-2 加入集群上的配置文件,准备本地环境
- 注意,配置文件中如果设置的是hostname,远程提交代码的机器,host中需要设置对应的ip
补充:
一直排斥在本地安装Hadoop环境,以前确实这样做过,行得通。但是一直难以理解。我为什么需要在本地也安装Hadoop(严格说不是安装,只是有相关文件),本地的又不会执行。
但是事实证明,本地没有相关文件,会有很多操作执行不了,比如下载文件到本地。
稍微可信一点的解释: 本地需要缓存一些东西
Hadoop存档下载: https://archive.apache.org/dist/hadoop/core/ - bin下放置winutils.exe: 各版本的Hadoop dll以及 winutils
2-3、查看文件/目录
public static void ls(FileSystem fs, String path) throws IOException {
FileStatus[] fileStatus = fs.listStatus(new Path(path));
for(FileStatus status : fileStatus){
System.out.println(status.getPath().toString());
}
}
2-4、创建目录
exists()总是返回true,暂未解决
/**
* TODO: 文件或目录存在的情况
* @param fs
* @param path
* @return
*/
public static boolean mkdir(FileSystem fs, String path) {
Preconditions.checkNotNull(path);
if (!isValidHdfsPath(path)) return false;
try {
fs.mkdirs(new Path(path));
return true;
} catch (IOException e) {
e.printStackTrace();
LOG.error(e.getMessage());
return false;
}
}
public static boolean isValidHdfsPath(String fileName) {
return fileName.startsWith(HDFS_SCHEME);
}
2-5、上传本地文件
public static void localToHdfs(FileSystem fs, String srcFile, String destPath) throws IOException {
fs.copyFromLocalFile(new Path(srcFile),new Path(HDFS_SCHEME + destPath));
}
2-6、人生苦短,远离远程调试
还是在centos机器上直接开发吧
- teamciewer
- 向日葵
- vncviewer
https://blog.csdn.net/changzehai/article/details/78826354
https://blog.csdn.net/tpaijojo/article/details/79115095
三、混合开发、完整pom文件
3-1、直接安装scala sdk(推荐,省事)
- 安装后直接解压,设置SCALA_HOME以及PATH
- 配置global libraries
这种方式不用在maven中设置依赖以及编译插件 - 安装Scala插件(语法检查、高亮、格式化等特性),重启IDEA
3-2、 不安装scala sdk
- pom中引入scala相关库,配置scala相关的plugin
2.安装Scala插件(语法检查、高亮、格式化等特性),重启IDEA - 然后工程中main和test下自建相应的目录
- 创建scala文件
没安装Scala SDk的情况下,至少需要:
scala-library
scala-maven-plugin
3-3、pom
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
<groupId>whgroupId>
<artifactId>env.testartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<scala.version>2.11.11scala.version>
<spark.version>2.4.0-cdh6.2.0spark.version>
<hadoop.version>3.0.0-cdh6.2.0hadoop.version>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
dependencies>
<build>
<finalName>${project.artifactId}finalName>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>4.0.1version>
<executions>
<execution>
<id>scala-compile-firstid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
<execution>
<id>scala-test-compileid>
<phase>process-test-resourcesphase>
<goals>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.8.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.1.0version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>ScalaRunnermainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
四、错误记录
- 问题:
Dependency 'org.apache.hadoop:hadoop-client:3.0.0-cdh6.2.0' not found
解决:添加仓库
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
-
问题:
HADOOP_HOME and hadoop.home.dir are unset
解决: 本地Hadoop环境以及winutils.exe等,见2-2 -
问题:
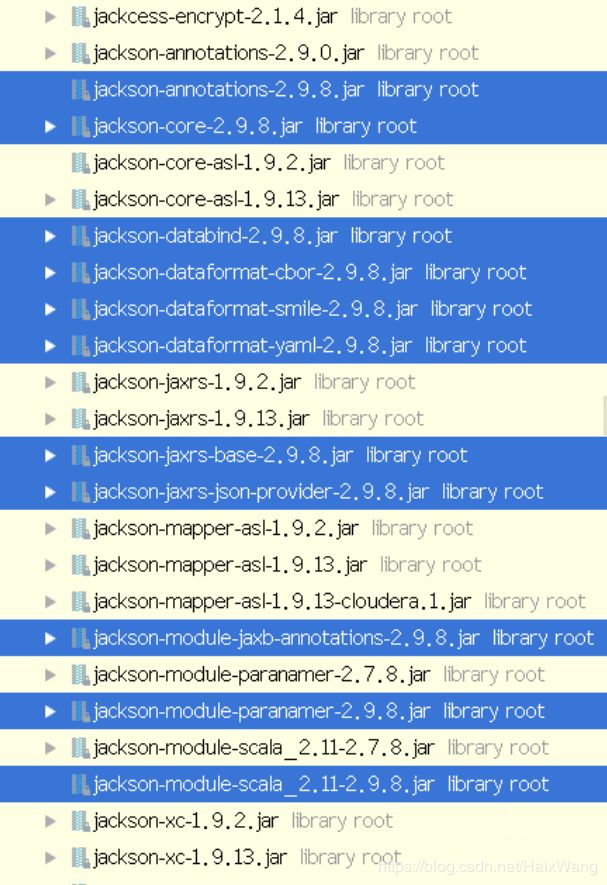
Caused by: com.fasterxml.jackson.databind.JsonMappingException: Incompatible Jackson version: 2.9.8
提示jackson.databind版本与 jackson.module版本不匹配
解决:
起初为了省事,我把cdh下的jars都加进来了,起了些冲突。
- 问题:
[org.apache.hadoop.ipc.Client] Retrying connect to server: node6.com/some ip:8020. Already tried 6 time(s); maxRetries=45
解决: 奇怪的是node6.com以及ip的值,我并没有设置过这些值
netstat -an | grep 8020,发现多个TIME_WAIT,0.0.0.0:*正在监听8020端口- 将信将疑注释了namenode的/etc/hosts/中的127.0.0.1
参考
- CDH 权限探索
- HDFS 客户端权限
- 各版本的Hadoop dll以及 winutils](https://github.com/steveloughran/winutils)
- Discover Intellij IDEA for Scala