SLAM——ORB特征提取、对极约束(E\F)、单应矩阵和三角测量(一)
1.特征点法
视觉SLAM主要分为视觉前端和优化后端。前端也称为视觉里程计(VO),根据相邻图像的信息估计处粗略的相机运动,给够后端提供较好的初始值。 VO的实现方法,按是否需要提取特征,可分为特征点的前端和不提特征点的直接法前端。
VO的主要问题是如何根据图像估计相机的运动:从图像选取有代表性的点(路标),在相机发生微笑变化时会保持不变,接着从各个图片找到相同的点,进而讨论相机位姿估计问题。其中,一种直观的提取特征方式就是在不同图像间辨认角点,确定其关系。
特征点由关键点和描述子俩部分组成。“提取关键点,计算描述子。关键点是指该特征点在图像里的位置,有些具有朝向、大小等。描述子为向量,描述了该关键点周围像素的信息,“外观相似的特征应有相似的描述子”。
特征提取:SIFT,考虑了图像变换过程中出现的光照等变化,但是计算量大,需要经过GPU加速后才能满足实时要求。FAST关键点,没有描述子。ORB特征提取,改进了FAST不具方向的问题,运用了BRIEF描述子,较好的选择。
1.1 ORB特征
俩个步骤:
1.FAST角点提取:找出角点,计算特征点主方向,为后面的描述子增加了旋转不变性。
2.对前一步提出特征点的周围图像区域进行描述。
A. 原始FAST关键点:
主要检测局部像素灰度变化明显的地方,速度快。主要思想是:如果一个像素与领域像素差别较大,则很有可能是角点。
1.在图像中选取像素p,假设它的亮度为 Ip I p 。
2.设置一个阈值 T T (比如, Ip I p 的 30% 30 % )
3.以像素为中心,选取半径为3的圆上的16个像素点。
4.假如圆上有连续的N个点的亮度大于 Ip+T I p + T 或小于 Ip−T I p − T ,那么像素 p p 可以被认为是特征点( N N 通常取12,FAST-12,其他取值为9和11)
5.对每个像素执行此操作。
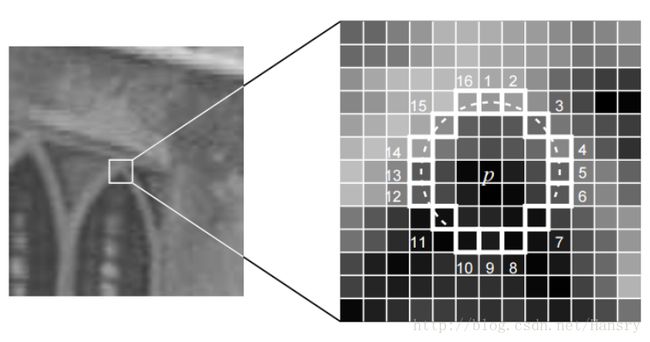
虽然速度快,但是经常会出现角点“扎堆”,FAST特征点数量很大但是不确定,而我们往往希望提取固定数量的特征点。
B. ORB改进后的FAST关键点(Oriented FAST):
在满足上述方法的前提下,对角点进行Harris响应值计算,然后选取前N个具有最大响应值的角点作为最终角点集合。同时添加了尺度和旋转的描述,尺度不变性:由构建图像金字塔,并在金字塔的每一层上检测角点来实现。特征的旋转:由灰度质心法实现。
灰度质心法:质心是指以图像块灰度值作为权重的中心。
1.在图像块B中,定义图像块的矩为
mpq=∑x,y∈BxpyqI(x,y) m p q = ∑ x , y ∈ B x p y q I ( x , y ) , p,q=0,1 p , q = 0 , 1 , I(x,y) I ( x , y ) 为灰度值,即所谓的亮度
2.通过矩可以找到图像块的质心: C=(m10m00,m01m00) C = ( m 10 m 00 , m 01 m 00 )
3.连接图像块的几何中心O(类似于原点那种)与质心,得到方向向量 OC−→− O C → ,于是特征点的方向可以定义为:
θ=arctan(m01/m10) θ = a r c t a n ( m 01 / m 10 )
C. BRIEF描述子(Steer BRIEF)
BRIEF是一种二进制描述子,有许多0,1组成,这里的0,1编码了关键点附近俩个像素(比如p和q的大小)关系:如果p比q大,那么取1,反之取0。 p p 和 q q 是按照某种概率分布随机选点的比较。如果个我们选择了128个这样的 p,q p , q ,最 后就得到128维由0,1组成的向量。
俩个特征点的描述子在向量空间上的距离相近,就可以认为他们是同样的特征点。
1.2 特征匹配
特征匹配是视觉SLAM中的数据关联问题,即确定当前看到路标和之前看到的路标之间的对应关系。通过图像与图像或图像与地图之间的描述子进行准确匹配,可以为后续的姿态估计减轻负担,但是误匹配广泛存在,是限制SLAM的一大瓶颈。
图像 It I t 特征点有 xmt x t m , m=1,2,...,M m = 1 , 2 , . . . , M
图像 It+1 I t + 1 有 xnt+1 x t + 1 n , n=1,2,...,N n = 1 , 2 , . . . , N 如何匹配呢?
暴力匹配:对![]() 图像上的所有特征点历遍求与跟
图像上的所有特征点历遍求与跟![]() 描述子的距离,进行比较,求出最小值那个。
描述子的距离,进行比较,求出最小值那个。
汉明距离:俩个二进制串之间的汉明距离,指的是其不同位数的个数。
2. 2D-2D:对极约束
假如从俩张图片中得到了一对配对好的特征点,如果有若干对这样的匹配点,那么可以通过这些二维图像点的对应关系,恢复俩帧之间摄像机的运动。
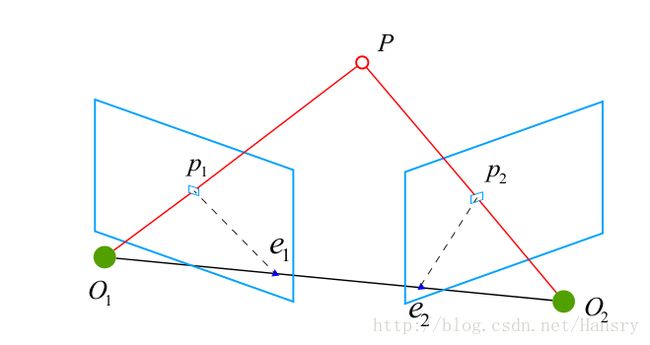
以上示意图中, O1,O2,P O 1 , O 2 , P 三个点可以确定一个平面,称为极平面。 O1,O2 O 1 , O 2 连线与像平面的交点分别为 e1,e2。e1,e2 e 1 , e 2 。 e 1 , e 2 ,称为极点, O1,O2 O 1 , O 2 被称为基线。称极平面与两个像平面 I1,I2 I 1 , I 2 之间的相交线 I1I2 I 1 I 2 为极线。
通过推导,我们可以定义本质矩阵 E=t∧R E = t ∧ R ,定义基础矩阵 F=K−TEK−1 F = K − T E K − 1 ,且有 xT2Ex1=pT2Fp1=0 x 2 T E x 1 = p 2 T F p 1 = 0 ,其中 p p 点为像素点, x x 点为像素点 p p 转换到归一化平面上的点。
于是,相机估计问题变为了以下俩步:
1.根据配对点的像素位置求出本质矩阵E和基础矩阵F
2.根据E和F求出R和t
2.1 本质矩阵
本质矩阵的特点:
1.本质矩阵是对极约束的,由于对极约束是等式为0的约束,所以对E乘以任何非零常数后,对极约束依然满足,极E在不同尺度下依然是满足的。
2.奇异值为 [γ,γ,0]T [ γ , γ , 0 ] T 形式的。
3.由于平移和旋转各有3个自由度, t∧R t ∧ R 有6个自由度,由于尺度不变性原因,E有5个自由度。
至于本质矩阵的求解,可以利用8点法, xT2Ex1=pT2Fp1=0 x 2 T E x 1 = p 2 T F p 1 = 0 的性质,利用本质矩阵的线性性质,构成线性方程组。

如上图所示,左边8x9矩阵为8对匹配点组成的矩阵,e为9x1矩阵即本质矩阵的元素。其中e位于该矩阵的零空间(矩阵A的零空间是指方程组 AX=0 A X = 0 的解向量构成的空间)。如果系数矩阵是满秩的(即秩为8),有唯一解e,构成一条线。
求出E这个本质矩阵后,怎么通过 E=t∧R E = t ∧ R 旋转矩阵R和平移矩阵t ??????
这个过程是通过奇异值分解(SVD)得到的 E=UAVT E = U A V T ,其中 U U , V V 为正交阵,A为奇异值矩阵, A=[γ,γ,0]T A = [ γ , γ , 0 ] T , 则可能出现四种情况的t,R。即从本质矩阵求出t,R的时候,会有四种解,但是只有一种具有正的深度值。
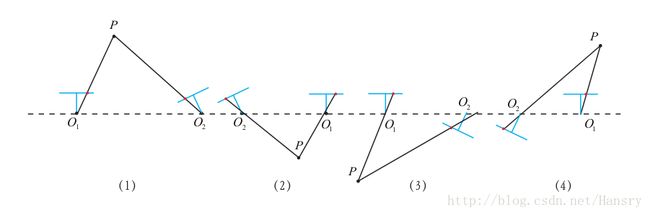
检验办法:将任意一点代入4种解中,检验该点在俩相机下的深度,均为正即为正解。
2.2 单应矩阵
单应矩阵 H,描述了俩个平面的映射关系,若场景中的特征点都落在同一平面上,则可以通过单应性来进行运动估计。单应矩阵通常描述处于共同平面上的一些点在俩张图像之间的变换关系。
1.考虑在图像 I1,I2 I 1 , I 2 中,有一对匹配好的特征点 p1,p2 p 1 , p 2 。这些特征点(三维空间)落在平面P上,这个平面满足方程: aX+bY+cZ+d=0 a X + b Y + c Z + d = 0 ,其法向量为 n^=[a,b,c]T n ^ = [ a , b , c ] T 。
2.从而可以化简得到方程 nTP+d=0 n T P + d = 0 ,进而满足方程: −nTPd=1 − n T P d = 1 ,得到
P2=RP1+t=RP1+t(−nTP1d)=(R−tnTd)P1 P 2 = R P 1 + t = R P 1 + t ( − n T P 1 d ) = ( R − t n T d ) P 1 ……(1)
3.将空间点 P1,P2 P 1 , P 2 投影到像素平面得到 p1,p2 p 1 , p 2 ,可得 s1p1=KP1 s 1 p 1 = K P 1 , s2p1=KP2 s 2 p 1 = K P 2
把 P1和P2 P 1 和 P 2 写成齐次坐标后可以得到: p1=KP1 p 1 = K P 1 , p2=KP2.........(2) p 2 = K P 2 . . . . . . . . . ( 2 )
4.把 (2) 式代到 (1) 式后,最后可得 p2=K(R−tnTd)K−1p1 p 2 = K ( R − t n T d ) K − 1 p 1
5.上述方程中,我们又可以得到 p2=Hp1 p 2 = H p 1 ,即有方程矩阵:
(u2v21)=(h1h4h7h2h5h8h3h6h9)(u1v11) ( u 2 v 2 1 ) = ( h 1 h 2 h 3 h 4 h 5 h 6 h 7 h 8 h 9 ) ( u 1 v 1 1 )
上述方程在非零因子下成立的,在实际处理问题中经常乘以一个非零因子使得 h9 h 9 等于1.经过推导,得到下面这一矩阵:
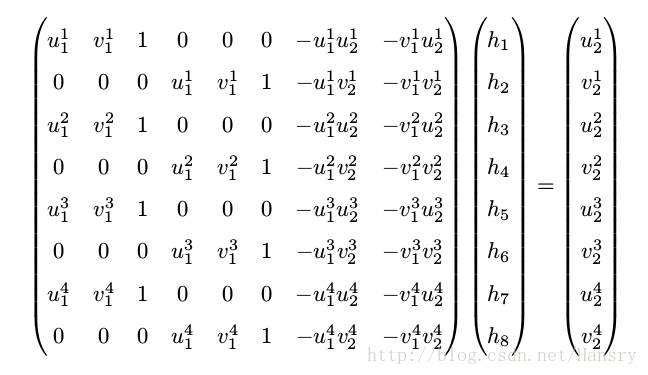
与本质矩阵相似,需要对其奇异值分解才能得到R和t。当特征点共面,或者相机发生纯旋转时,基础矩阵自由度下降,出现退化。为了能够避免退化现象造成的影响,通常我们会同时估计基础矩阵 F 和单应矩阵 H,选择重投影误差比较小的那个作为最终的运动估计矩阵。
2.3小结
从E,F和H中都可以分解出运动,不过H需要假设特征点都在平面上。
由于E本身具有尺度等价性,它分解得到的t,R也有一个尺度等价性。而R属于正交旋转群,具有一定约束,而t具有一个尺度,在分解中,对t乘以任意非零常数,都是成立的。通常把t归一化。
A.尺度不确定性:
因为尺度不确定性的问题,对t长度归一化后,导致了t的单位问题,不知道其输出的数值单位是多少,虽然不知道它的实际长度为多少,但我们这时以t为单位1,计算相机运动和特征点的3D位置,称为单目SLAM初始化。
在初始化之后,可以用3D-2D来计算运动, 初始化后的轨迹和地图的单位,就是初始化时固定的尺度。初始化化后的轨迹和地图的单位,就是初始化时固定的尺度。单目SLAM一定要初始化,初始化的俩张图像必须有一定程度的平移,而后的轨迹和地图都以此步的平移为单位。
B.初始化的纯旋转问题:
E分解到R,t的过程中,如果相机是纯旋转,导致t为零,那么E为0,无法求R。单目相机初始化时不能只有旋转,必须要有一定程度的平移。
C.多于8对点的情况:
上述求解本质矩阵的时候,用到了8对点,如果大于8对点呢???
该方程构成了超定方程,通过最小二乘法来求: mine||Ae||22=mineeTATAe m i n e | | A e | | 2 2 = m i n e e T A T A e ,求出在最小二乘意义下的E矩阵,但是当存在太多误匹配的情况下,更倾向于使用随机采样一致性(RANSAC)。
2.4 三角测量
使用对极约束估计了相机的运动,在得到运动之后,我们需要用相机的运动估计特征点的空间位置。在单目SLAM中,仅仅通过单张图像无法获得像素深度信息,需要通过三角测量来估计其深度。

上图中, O1P O 1 P 和 O2P O 2 P 理论上交与P点,但是由于噪声的存在,往往无法相交。可以通过最小二乘求解。设 x1,x2 x 1 , x 2 为俩个特征点的归一化坐标,那他们满足:
s2x2=s1Rx1+t s 2 x 2 = s 1 R x 1 + t
由于我们已经知道R和t,想要求解的是俩个特征点的深度 s1,s2 s 1 , s 2 。当然这俩个深度可以分开求,若要求 s1 s 1 ,则左乘 x∧ x ∧ ,得到
s2x∧2x2=0=s1x∧2Rx1+x∧2t s 2 x 2 ∧ x 2 = 0 = s 1 x 2 ∧ R x 1 + x 2 ∧ t
以上方程中,只需要对右边求方程即可,求出 s1 s 1 ,但是考虑到噪声的问题,估计的 R,t R , t 不一定为精确值,所以更常见的是求最小二乘,而不是求零解。
以上过程,可以通过代码来实现,以下只是主函数里面的代码,显示了主要流程:
int main ( int argc, char** argv )
{
//-- 读取图像
Mat img_1 = imread ( "/home/hansry/Slam_Book/src/Test_trian/data/1.png", CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( "/home/hansry/Slam_Book/src/Test_trian/data/2.png", CV_LOAD_IMAGE_COLOR );
vector"组匹配点"<//-- 通过匹配点,估计两张图像间运动,通过对极约束,计算基础矩阵、本质矩阵和单应矩阵,从而求出R,t
Mat R,t;
pose_estimation_2d2d ( keypoints_1, keypoints_2, matches, R, t );
//-- 三角化测量,通过匹配点求出基于相机坐标系的空间点
vector//通过第一张图片像素点和内参转化的归一化平面上的点
Point2d pt1_cam = pixel2cam( keypoints_1[ matches[i].queryIdx ].pt, K );
//通过三角化测量求出来的点然后归一化平面
Point2d pt1_cam_3d(
points[i].x/points[i].z,
points[i].y/points[i].z
);
cout<<"point in the first camera frame: "<cout<<"point projected from 3D "<", d="<// 第二个图同样的,通过在第二张图匹配点像素点进行转化得到的归一化平面上的点
Point2f pt2_cam = pixel2cam( keypoints_2[ matches[i].trainIdx ].pt, K );
//通过R,t求出三角化测量求出P点在第二个相机坐标系下的三维坐标值
Mat pt2_trans = R*( Mat_<double>(3,1) << points[i].x, points[i].y, points[i].z ) + t;
//三维点归一化平面上的点
pt2_trans /= pt2_trans.at<double>(2,0);
cout<<"point in the second camera frame: "<cout<<"point reprojected from second frame: "<cout<return 0;
} 通过三角测量及像素上的匹配点,我们可以求出路标即P点基于第一个相机坐标系的三维坐标点,然后通过对极约束求出的R,t可以求出在第二个相机坐标系上路标P点的三维坐标值。
讨论:三角平移是由平移得到的,有平移才会有对极几何约束的三角形。因此,纯旋转是无法使用三角测量的,对极约束将永远满足。在平移时,三角测量有不确定性,会引出三角测量的矛盾。
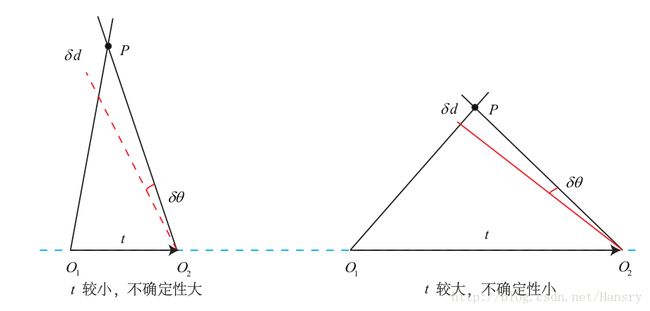
如上图所示,当平移很小时,像素上的不确定性将导致较大的深度不确定性,平移较大时,在相同的相机分辨率下,三角化测量将更精确。三角化测量的矛盾:平移增大,会导致匹配失效,平移太小,三角化精度不够。