CVPR2018 | 细粒度分类 : Learning a Discriminative Filter Bank within a CNN(DFL-CNN) 及tensorflow实现
论文题目:
Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition
tensorfow代码地址:
https://github.com/mengrang/DFL-CNN-tensorflow
文章亮点:
端到端弱监督地增强mid-level 学习能力:
1.取特征图聚类中心来初始化的1 * 1 * C卷积核检测判别性区域
2.非对称多分支网络结构同时利用局部信息和全局信息。
3.多尺度-结合检测中的pyramid方法
方法
1.不对称多分支结构
对于细粒度分类,全局信息也是至关重要的。所以需要一条分支解码全局信息。即普通conv+fc层。然后选取适当的一个较高层卷积,分出另外一条分支进行mid-level能力加强,关注局部信息。

2. DFL模块
2.1 显著区域检测
我们把1* 1 * C conv当作判别性区域检测器。如下图

输入图像经过一系列卷积和池化获得H * W * C 的特征图,然后设计一个1 * 1 * C * MK卷积核,输出通道为MK,每个通道是一张热力图,响应强度最大的区域即显著性区域。后接全局最大池化(stride=1)(GMP)来获取最大响应块。这样可以获得MK个最大响应块。
一般细粒度分类需要较小,且较密集的显著性区域,对这个1 * 1 * C * MK卷积核之前的网络感受野、stride与属于图像尺寸的搭配具有一些要求。
2.2 基于特征图聚类中心的卷积核初始化
事实上,如果任务是显著性检测,由于G-stream的分类loss.可以直接对所取特征图进行全局最大池化。但是我们希望显著性隐式地表示类别信息(下面会降到类别监督信息),所以加入1 * 1卷积进行学习。这样如果其初始化是随机的,可能会破坏原来的显著性,无法收敛到较好的极值点。
为了让卷积核可以兼顾显著性和类别信息,进行基于特征图聚类中心的卷积核非随机初始化。这是文章中end-to-end之外的一部分准备工作。
1)以VGG16做basenet,取出Imagenet预训练模型在数据集上第10层conv4_3卷积核的输出H * W * C特征图。特征图上的1 * 1 * C向量代表输入图像响应的一个个区域。对于448 * 448输入,VGG16的conv4_3特征图输出的一个向量表示输入图像的92 * 92区域,向量向量stride在输入图像是为8。
2)对特征图进行跨通道L2正则化,获得H * W的能量图。

3)对此能量图非最大值抑制挑选预处理之后,取K个聚类中心进行k-means聚类。获得H * W * C特征图的K个“质心”。将上文提及的卷积核分为M组,每组K个。每个聚类中心是一个1 * 1 * C的向量。然后用这K个向量来分别初始化每组的显著性区域检测器。
2.3 判别性监督
以上是在获取显著区域,我们需要加入监督信息,让显著性代表判别性。
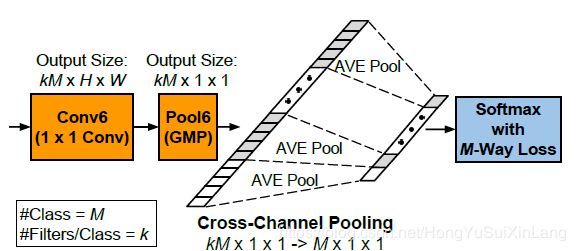
如图,对于GMP之后的KM维向量,我们后接cross-channel-pooling+softmax+crossentropy来加入监督信息。将KM维向量分成M组,M是类别数目。对每个组中的最显著区域利用跨通道平均池化(cross-channel-pooling)取平均,得到结果代表了每一类中最显著区域的效果,后接softmax loss加入监督信息,隐式地赋予其类别判定。至此,通过学习,以上提到的1 * 1 * C * MK卷积核达到判别性区域检测效果。
核心代码块如下:
fc_part = slim.conv2d(part_feature,
M * k,
[1, 1],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=tf.contrib.layers.l2_regularizer(weight_decay),
biases_regularizer=tf.contrib.layers.l2_regularizer(weight_decay)
)
fc_part_h = fc_part.get_shape().as_list()[1]
fc_part_w = fc_part.get_shape().as_list()[2]
fc_part = slim.max_pool2d(fc_part, (fc_part_h, fc_part_w), scope="GMP2")
ft_list = tf.split(fc_part,
num_or_size_splits=M,
axis=-1)
cls_list = []
for i in range(M):
ft = tf.transpose(ft_list[i], [0, 1, 3, 2])
cls = layers_lib.pool(ft,
[1, k],
"AVG")
cls = layers.flatten(cls)
cls_list.append(cls)
fc_ccp = tf.concat(cls_list, axis=-1) #cross_channel_pooling (N, M)
关于的卷积层选取,文章提到可以参考pyramid方法,选取几个较高层卷积层输出,取得多尺度效果。