NLP基础实验⑦:FastText
一、介绍
Word2Vec作者Mikolov在预印本(Bag of Tricks for Efficient Text Classification:https://arxiv.org/pdf/1607.01759v2.pdf)中提出了fastText文本分类方法,可以在普通CPU上快速训练,结果与深度学习训练出来的模型类似。
论文翻译:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650716942&idx=3&sn=0d48c0218131de502ac5e2ef9b700967
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,模型简单,训练速度非常快,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。
fastText简而言之,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。fastText和ACL-15上的deep averaging network [1] (DAN,如下图)非常相似,区别就是去掉了中间的隐层。两篇文章的结论也比较类似,也是指出对一些简单的分类任务,没有必要使用太复杂的网络结构就可以取得差不多的结果。
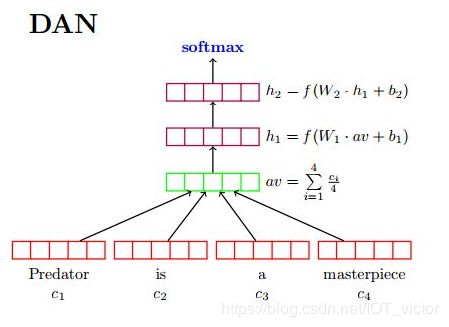
文中实验选取的都是对句子词序不是很敏感的数据集,所以得到文中的实验结果完全不奇怪。但是比如对下面的三个例子来说:
- The movie is not very good , but i still like it . [2]
- The movie is very good , but i still do not like it .
- I do not like it , but the movie is still very good .
其中第1、3句整体极性是positive,但第2句整体极性就是negative。如果只是通过简单的取平均来作为sentence representation进行分类的话,可能就会很难学出词序对句子语义的影响。
从另一个角度来说,fastText可以看作是用window-size=1 + average pooling的CNN [3]对句子进行建模。
总结一下:对简单的任务来说,用简单的网络结构进行处理基本就够了,但是对比较复杂的任务,还是依然需要更复杂的网络结构来学习sentence representation的。
另外,fastText文中还提到的两个tricks分别是:
- hierarchical softmax
- 类别数较多时,通过构建一个霍夫曼编码树来加速softmax layer的计算,和之前word2vec中的trick相同
- N-gram features
- 只用unigram的话会丢掉word order信息,所以通过加入N-gram features进行补充
- 用hashing来减少N-gram的存储
参考
达观数据:fastText原理及实践:从softmax、ngram等,然后简单介绍word2vec原理,之后来讲解fastText的原理,并着手使用keras搭建一个简单的fastText分类器
二、gensim中models.fasttext
https://radimrehurek.com/gensim/models/fasttext.html
三、官方手册
GitHub
https://github.com/facebookresearch/fastText#building-fasttext-for-python
https://github.com/salestock/fastText.py
博客
基于fasttext的情感极性判断模型实现:https://blog.csdn.net/sinat_33741547/article/details/78803766
Text classification:https://fasttext.cc/docs/en/supervised-tutorial.html
Word representations:https://fasttext.cc/docs/en/unsupervised-tutorial.html
fastText源码分析以及使用:https://jepsonwong.github.io/2018/05/02/fastText/