深度学习实践经验:用Faster R-CNN训练Caltech数据集——训练检测
前言
前面已经介绍了如何准备数据集,以及如何修改数据集读写接口来操作数据集,接下来我来说明一下怎么来训练网络和之后的检测过程。
修改模型文件
faster rcnn有两种各种训练方式:
- Alternative training(alt-opt)
- Approximate joint training(end-to-end)
两种方法有什么不同,可以参考我这篇博客,推荐使用第二种,因为第二种使用的显存更小,而且训练会更快,同时准确率差不多,两种方式需要修改的代码是不一样的,同时faster rcnn提供了三种训练模型,小型的ZF model,中型的VGG_CNN_M_1024和大型的VGG16,论文中说VGG16效果比其他两个好,但是同时占用更大的GPU显存(~11GB)
我使用的是VGG model + alternative training,需要检测的类别只有一类,加上背景所以总共是两类(background + person)。
下面修改模型文件:
py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/stage1_fast_rcnn_train.pt
layer { name: 'data' type: 'Python' top: 'data' top: 'rois' top: 'labels' top: 'bbox_targets' top: 'bbox_inside_weights' top: 'bbox_outside_weights' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 2" #按训练集类别改,该值为类别数+1 } }layer { name: "cls_score" type: "InnerProduct" bottom: "fc7" top: "cls_score" param { lr_mult: 1.0 } param { lr_mult: 2.0 } inner_product_param { num_output: 2 #按训练集类别改,该值为类别数+1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } }layer { name: "bbox_pred" type: "InnerProduct" bottom: "fc7" top: "bbox_pred" param { lr_mult: 1.0 } param { lr_mult: 2.0 } inner_product_param { num_output: 8 #按训练集类别改,该值为(类别数+1)*4,四个顶点坐标 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } }py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/stage1_rpn_train.pt
layer { name: 'input-data' type: 'Python' top: 'data' top: 'im_info' top: 'gt_boxes' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 2" #按训练集类别改,该值为类别数+1 } }py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/stage2_fast_rcnn_train.pt
layer { name: 'data' type: 'Python' top: 'data' top: 'rois' top: 'labels' top: 'bbox_targets' top: 'bbox_inside_weights' top: 'bbox_outside_weights' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 2" #按训练集类别改,该值为类别数+1 } }layer { name: "cls_score" type: "InnerProduct" bottom: "fc7" top: "cls_score" param { lr_mult: 1.0 } param { lr_mult: 2.0 } inner_product_param { num_output: 2 #按训练集类别改,该值为类别数+1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } }layer { name: "bbox_pred" type: "InnerProduct" bottom: "fc7" top: "bbox_pred" param { lr_mult: 1.0 } param { lr_mult: 2.0 } inner_product_param { num_output: 8 #按训练集类别改,该值为(类别数+1)*4,四个顶点坐标 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } }py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/stage2_rpn_train.pt
layer { name: 'input-data' type: 'Python' top: 'data' top: 'im_info' top: 'gt_boxes' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 2" #按训练集类别改,该值为类别数+1 } }py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt
layer { name: "cls_score" type: "InnerProduct" bottom: "fc7" top: "cls_score" inner_product_param { num_output: 2 #按训练集类别改,该值为类别数+1 } } layer { name: "bbox_pred" type: "InnerProduct" bottom: "fc7" top: "bbox_pred" inner_product_param { num_output: 84 #按训练集类别改,该值为(类别数+1)*4,四个顶点坐标 } }
训练测试
训练前还需要注意几个地方:
cache问题:
假如你之前训练了官方的VOC2007的数据集或其他的数据集,是会产生cache的问题的,建议在重新训练新的数据之前将其删除。
py-faster-rcnn/outputpy-faster-rcnn/data/cache
训练参数
参数放在如下文件:
py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_alt_opt/stage_fast_rcnn_solver*.ptbase_lr: 0.001 lr_policy: 'step' step_size: 30000 display: 20 ....迭代次数在文件py-faster-rcnn/tools/train_faster_rcnn_alt_opt.py中进行修改:
max_iters = [80000, 40000, 80000, 40000]分别对应rpn第1阶段,fast rcnn第1阶段,rpn第2阶段,fast rcnn第2阶段的迭代次数,自己修改即可,不过注意这里的值不要小于上面的solver里面的step_size的大小,大家自己修改吧
开始训练
首先修改experiments/scripts/faster_rcnn_alt_opt.sh成如下,修改地方已标注:
#!/bin/bash
# Usage:
# ./experiments/scripts/faster_rcnn_alt_opt.sh GPU NET DATASET [options args to {train,test}_net.py]
# DATASET is only pascal_voc for now
#
# Example:
# ./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG_CNN_M_1024 pascal_voc \
# --set EXP_DIR foobar RNG_SEED 42 TRAIN.SCALES "[400, 500, 600, 700]"
set -x
set -e
export PYTHONUNBUFFERED="True"
GPU_ID=$1
NET=$2
NET_lc=${NET,,}
DATASET=$3
array=( $@ )
len=${#array[@]}
EXTRA_ARGS=${array[@]:3:$len}
EXTRA_ARGS_SLUG=${EXTRA_ARGS// /_}
case $DATASET in
caltech) # 这里将pascal_voc改为caltech
TRAIN_IMDB="caltech_train" # 改为与factor.py中命名的name格式相同,为caltech_train
TEST_IMDB="caltech_test" # 改为与factor.py中命名的name格式相同,为caltech_test
PT_DIR="caltech" # 这里将pascal_voc改为caltech
ITERS=40000
;;
coco)
echo "Not implemented: use experiments/scripts/faster_rcnn_end2end.sh for coco"
exit
;;
*)
echo "No dataset given"
exit
;;
esac
LOG="experiments/logs/faster_rcnn_alt_opt_${NET}_${EXTRA_ARGS_SLUG}.txt.`date +'%Y-%m-%d_%H-%M-%S'`"
exec &> >(tee -a "$LOG")
echo Logging output to "$LOG"
time ./tools/train_faster_rcnn_alt_opt.py --gpu ${GPU_ID} \
--net_name ${NET} \
--weights data/imagenet_models/${NET}.v2.caffemodel \
--imdb ${TRAIN_IMDB} \
--cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
${EXTRA_ARGS}
set +x
NET_FINAL=`grep "Final model:" ${LOG} | awk '{print $3}'`
set -x
time ./tools/test_net.py --gpu ${GPU_ID} \
--def models/${PT_DIR}/${NET}/faster_rcnn_alt_opt/faster_rcnn_test.pt \
--net ${NET_FINAL} \
#--net output/faster_rcnn_alt_opt/train/ZF_faster_rcnn_final.caffemodel \
--imdb ${TEST_IMDB} \
--cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
${EXTRA_ARGS}
调用如下命令进行训练及测试,从上面代码可以看出,该shell文件在训练完后会接着进行测试,但是我的测试集没有标注,所以测试的时候会报错,但是由于Caltech数据集的测试结果有专门的评估代码,所以我不用faster r-cnn提供的代码进行测试,而是直接进行检测生成坐标,用专门的评估代码进行检测。
cd py-faster-rcnn
./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG16 caltech - 参数1:指定gpu_id。
- 参数2:指定网络模型参数。
- 参数3:数据集名称,目前只能为
pascal_voc。
在训练过程中,会调用py_faster_rcnn/tools/train_faster_rcnn_alt_opt.py文件开始训练网络。
可能会出现的Bugs
AssertionError: assert (boxes[:, 2] >= boxes[:, 0]).all()
问题重现
在训练过程中可能会出现如下报错:
File "/py-faster-rcnn/tools/../lib/datasets/imdb.py", line 108, in
append_flipped_images
assert (boxes[:, 2] >= boxes[:, 0]).all()
AssertionError问题分析
检查自己数据发现,左上角坐标 (x, y) 可能为0,或标定区域溢出图片(即坐标为负数),而faster rcnn会对Xmin,Ymin,Xmax,Ymax进行减一操作,如果Xmin为0,减一后变为65535,从而在左右翻转图片时导致如上错误发生。
问题解决
修改
lib/datasets/imdb.py中的append_flipped_images()函数:数据整理,在一行代码为
boxes[:, 2] = widths[i] - oldx1 - 1下加入代码:for b in range(len(boxes)): if boxes[b][2]< boxes[b][0]: boxes[b][0] = 0修改
lib/datasets/caltech.py,_load_pascal_annotation()函数,将对Xmin,Ymin,Xmax,Ymax减一去掉,变为:# Load object bounding boxes into a data frame. for ix, obj in enumerate(objs): bbox = obj.find('bndbox') # Make pixel indexes 0-based # 这里我把‘-1’全部删除掉了,防止有的数据是0开始,然后‘-1’导致变为负数,产生AssertError错误 x1 = float(bbox.find('xmin').text) y1 = float(bbox.find('ymin').text) x2 = float(bbox.find('xmax').text) y2 = float(bbox.find('ymax').text) cls = self._class_to_ind[obj.find('name').text.lower().strip()] boxes[ix, :] = [x1, y1, x2, y2] gt_classes[ix] = cls overlaps[ix, cls] = 1.0 seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)(可选)如果1和2可以解决问题,就没必要用方法3。修改
lib/fast_rcnn/config.py,不使图片实现翻转,如下改为:# Use horizontally-flipped images during training? __C.TRAIN.USE_FLIPPED = False
如果如上三种方法都无法解决该问题,那么肯定是你的数据集坐标出现小于等于0的数,你应该一一排查。
训练fast rcnn时出现loss=nan的情况。
问题重现
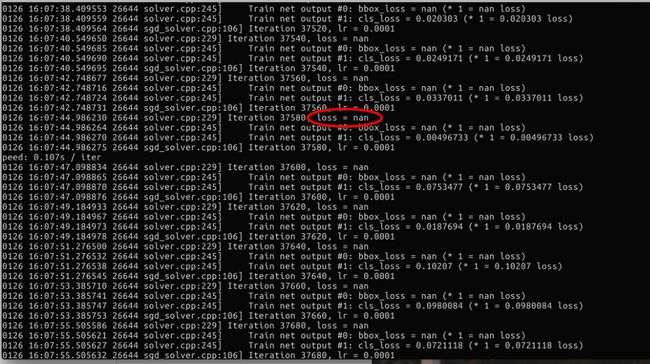
问题分析
这是由于模型不收敛,导致loss迅速增长。
而我出现以上现象的原因主要是因为我在出现AssertionError的时候直接使用了第三种方法导致的。也就是禁用图片翻转。
问题解决
启用图片翻转。
训练结果
训练后的模型放在output/faster_rcnn_alt_opt/train/VGG16_faster_rcnn_final.caffemodel,该模型可以用于之后的检测。
检测
检测步骤
经过以上训练后,就可以用得到的模型来进行检测了。检测所参考的代码是tools/demo.py,具体步骤如下:
- 将
output/faster_rcnn_alt_opt/train/VGG16_faster_rcnn_final.caffemodel,拷贝到data/faster_rcnn_models下,命名为VGG16_Caltech_faster_rcnn__final.caffemodel - 进入
tools/文件夹中,拷贝demo.py为demo_caltech.py。 - 修改demo_caltech.py代码如下:
#!/usr/bin/env python
# --------------------------------------------------------
# Faster R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import matplotlib
matplotlib.use('Agg');
"""
Demo script showing detections in sample images.
See README.md for installation instructions before running.
"""
import _init_paths
from fast_rcnn.config import cfg
from fast_rcnn.test import im_detect
from fast_rcnn.nms_wrapper import nms
from utils.timer import Timer
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
import caffe, os, sys, cv2
import argparse
CLASSES = ('__background__', # 这里改为自己的类别
'person')
NETS = {'vgg16': ('VGG16',
'VGG16_Caltech_faster_rcnn_final.caffemodel'), #这里需要修改为训练后得到的模型的名称
'zf': ('ZF',
'ZF_Caltech_faster_rcnn_final.caffemodel')} #这里需要修改为训练后得到的模型的名称
def vis_detections(im, image_name, class_name, dets, thresh=0.5):
"""Draw detected bounding boxes."""
inds = np.where(dets[:, -1] >= thresh)[0]
if len(inds) == 0:
return
im = im[:, :, (2, 1, 0)]
fig, ax = plt.subplots(figsize=(12, 12))
ax.imshow(im, aspect='equal')
for i in inds:
bbox = dets[i, :4]
score = dets[i, -1]
ax.add_patch(
plt.Rectangle((bbox[0], bbox[1]),
bbox[2] - bbox[0],
bbox[3] - bbox[1], fill=False,
edgecolor='red', linewidth=3.5)
)
ax.text(bbox[0], bbox[1] - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=14, color='white')
ax.set_title(('{} detections with '
'p({} | box) >= {:.1f}').format(class_name, class_name,
thresh),
fontsize=14)
plt.axis('off')
plt.tight_layout()
plt.draw()
plt.savefig('/home/jk/py-faster-rcnn/output/faster_rcnn_alt_opt/test/'+image_name) #将检测后的图片保存到相应的路径
def demo(net, image_name):
"""Detect object classes in an image using pre-computed object proposals."""
# Load the demo image
im_file = os.path.join(cfg.DATA_DIR, 'VOCdevkit/Caltech/JPEGImages', image_name)
im = cv2.imread(im_file)
# Detect all object classes and regress object bounds
timer = Timer()
timer.tic()
scores, boxes = im_detect(net, im)
timer.toc()
print ('Detection took {:.3f}s for '
'{:d} object proposals').format(timer.total_time, boxes.shape[0])
# Visualize detections for each class
CONF_THRESH = 0.85 # 设置权值,越低检测出的框越多
NMS_THRESH = 0.3
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # because we skipped background
cls_boxes = boxes[:, 4*cls_ind:4*(cls_ind + 1)]
cls_scores = scores[:, cls_ind]
dets = np.hstack((cls_boxes,
cls_scores[:, np.newaxis])).astype(np.float32)
keep = nms(dets, NMS_THRESH)
dets = dets[keep, :]
vis_detections(im, image_name, cls, dets, thresh=CONF_THRESH)
def parse_args():
"""Parse input arguments."""
parser = argparse.ArgumentParser(description='Faster R-CNN demo')
parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]',
default=0, type=int)
parser.add_argument('--cpu', dest='cpu_mode',
help='Use CPU mode (overrides --gpu)',
action='store_true')
parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16]',
choices=NETS.keys(), default='vgg16')
args = parser.parse_args()
return args
if __name__ == '__main__':
cfg.TEST.HAS_RPN = True # Use RPN for proposals
args = parse_args()
prototxt = os.path.join(cfg.MODELS_DIR, NETS[args.demo_net][0],
'faster_rcnn_alt_opt', 'faster_rcnn_test.pt')
caffemodel = os.path.join(cfg.DATA_DIR, 'faster_rcnn_models',
NETS[args.demo_net][1])
if not os.path.isfile(caffemodel):
raise IOError(('{:s} not found.\nDid you run ./data/script/'
'fetch_faster_rcnn_models.sh?').format(caffemodel))
if args.cpu_mode:
caffe.set_mode_cpu()
else:
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
cfg.GPU_ID = args.gpu_id
net = caffe.Net(prototxt, caffemodel, caffe.TEST)
print '\n\nLoaded network {:s}'.format(caffemodel)
# Warmup on a dummy image
im = 128 * np.ones((300, 500, 3), dtype=np.uint8)
for i in xrange(2):
_, _= im_detect(net, im)
testfile_path = '/home/jk/py-faster-rcnn/data/VOCdevkit/Caltech/ImageSets/Main/test.txt'
with open(testfile_path) as f:
im_names = [x.strip()+'.jpg' for x in f.readlines()] # 从test.txt文件中读取图片文件名,找到相应的图片进行检测。也可以使用如下的方法,把项检测的图片存到tools/demo/文件夹下进行读取检测
#im_names = ['set06_V002_I00023.jpg', 'set06_V002_I00072.jpg', 'set06_V002_I00097.jpg',
# 'set06_V002_I00151.jpg', 'set07_V010_I00247.jpg']
for im_name in im_names:
print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
print 'Demo for data/demo/{}'.format(im_name)
demo(net, im_name)
plt.show()
在命令行中输入一下命令进行检测:
python tools/demo_caltech.py检测结果
放几张检测后的结果图,感觉检测效果并不是很好,很多把背景当成行人的错误:




参考博客
- 使用Faster-Rcnn进行目标检测(实践篇)
- Train Fast-RCNN on Another Dataset