DataX-Migration数据库迁移,数据库同步实现解决方案
DataX-Migration
DataX-Migration is Yxt (Yunxuetang) Full Database Migration Tool based on Alibaba DataX 3.0. Support Database Migration among Mysql, Oracle, SqlServer, PostgreSql. And support where condition when migration.
DataX-Migration 是云学堂开源的基于阿里巴巴DataX 3.0的数据库迁移工具。支持对Mysql,Oracle,SqlServer, PostgreSql之间的相互迁移, 支持迁移时带where查询条件,并生成迁移数据报表。
DataX是什么?
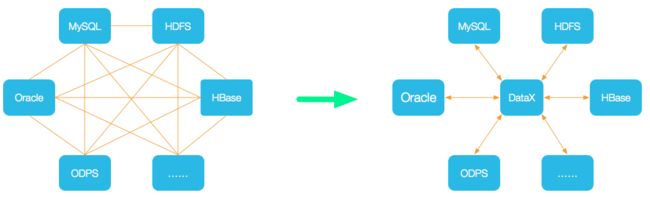
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX 在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
关于更详细的介绍请看这里:https://github.com/alibaba/DataX/wiki/DataX-Introduction
为什么还需要DataX-Migration
DataX专注于对数据的同步,它使用脚本以及可配置的方式,以一个个独立的脚本任务,非常方便地对单表的数据进行同步操作。但我们需要更加智能或自动的方式同步整个数据库,所以我们对DataX进行了包装,以更方便地进行整个数据库的迁移工作。
DataX-Migration的功能
DataX-Migration 能根据用户配置数据库表tables的查询条件,生成这些数据库表的单独的DataX json配置,然后启动DataX的脚本来开始这些表的数据迁移,并生成相应的cvs报表。当表的数量过多时,可以配置切分策略来划分出多个线程来同时做迁移已加快迁移数据。

Support Data Channels
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
Datax-Migration目前对关系型数据库的直接使用是基本没有问题,至于非关系型数据库还需验证。
Quick Start
1. download [DataX可以运行的bin下载地址](http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz)
2. git clone https://github.com/Jawf/datax-migration.git (也可从下面的链接直接下载)
3. mvn clean install
4. copy target/datax-migration.jar and target/datax-migration_lib to datax/ home directory.
5. open the datax-migration.jar, edit the config.properties, config migration db information source/target url, dbname, user, password, etc.
6. open the datax-migration.jar, edit the job/jobtemplate.json accordingly, default it migration from mysqlreader->mysqlwriter
7. java -jar datax-migration.jar
DataX-Migration可以运行的bin下载地址
DataX可以运行的bin下载地址
Special Function
java -jar datax-migration.jar json #Only generate json files config for all tables.
java -jar datax-migration.jar report #Only generate cvs report to view migration status.
java -jar datax-migration.jar run #Only run the migration and generate the cvs reports. Before run this, need generate json config files for all tables first.
Config.properties Detail Properties
| Properties Name | Mandatory Config | Value Sample | Remark |
|---|---|---|---|
| source.db.url | * | jdbc:mysql://192.168.0.188:3306/sourcedbname?useUnicode=true&characterEncoding=UTF-8 | 迁移源数据库连接url |
| source.db.name | * | sourcedbname | 源数据库名 |
| source.db.username | * | username | 源数据库连接用户名 |
| source.db.password | * | password | 源数据库连接密码 |
| target.db.url | * | jdbc:mysql://192.168.0.189:3306/targetdbname?useUnicode=true&characterEncoding=UTF-8 | 迁移目标数据库名 |
| target.db.name | * | targetdbname | 目标数据库名 |
| target.db.username | * | username | 目标数据库连接用户名 |
| target.db.password | * | password | 目标数据库连接密码 |
| source.db.global.where.clause | orgId=‘410e7127-d969-4e0b-8326-4828182363cc’ | global where clause to filter the migration data, the clause also be used in get status of report, ensure it able to be run in source and target db | |
| source.db.global.where.second.clause | userid in (select id from CORE_USERPROFILE where orgid=‘d7f8dffb-8ae9-4a97-857b-59f395942781’) | if the source table contain the column in where clause, will use the first where clause and ignore the second. if the source table does not contain the column in the where clause, but contain column in the second clause, will use the second clause and igonre the first clause. if the source table does not contain both where column, will ignore both | |
| migration.query.target.tables.sql | * | select ut.table_name from information_schema.tables ut where ut.table_schema=‘targetdbname’ and ut.table_type=‘base table’ | target db query sql: select migration tables |
| migration.query.target.table.columns.sql | * | select column_name from information_schema.columns t where table_schema=‘targetdbname’ and table_name=’{0}’ | target db query sql: select migration table columns |
| migration.query.target.table.primarykeys.sql | * | select column_name from information_schema.columns t where column_key=‘pri’ and table_name=’{0}’ | #target db query sql: select migration table primary keys |
| migration.query.source.tables.status.sql | * | select ut.table_name,(ut.data_length+ut.index_length)/1024/1024 as size_MB, ut.table_rows from information_schema.tables ut where ut.table_schema=‘targetdbname’ and ut.table_type=‘base table’ order by size_MB desc; | must contain 1:tablename,2:size,3:numOfRows. And must order by size desc. |
| migration.datax.channel.multiple | true | mutiple channel used within one job to speed the migration, 2 channel will open 2*5 thread for one job. Caution: Mutiple channels may able to cause records consistency. | |
| migration.datax.channel.2channels.records.over | 1000000 | if migration records more than this value, will use 2 channel in DataX json config. Caution: Mutiple channels may able to cause records consistency. | |
| migration.error.continue | true | if got error whether terminate the running thread | |
| migration.ingore.tables | empty | config ingore tables to ignore migration. empty=ignore none | |
| migration.ingore.bigtables.size.than.mb | 1 | define the table size bigger than the value and ignore to migration. 1=igonre all tables that size > 1MB | |
| migration.jobthread.split.type | size | job thread to group a number of tables in thread by split type, available value: index:tables list index in the cvs reports, size:table size | |
| migration.jobthread.split.maxcount | 40 | job thread max tables, if between size:20-10 got 60 tables, will be grouped to 40,20. similar for split by index numbers. Adjust this value according to the big table size to encrease the migration speed. | |
| migration.jobthread.split.tablesize.mb | “40000,30000,20000,10000,5000,1000,500,200,100,50,20,10,1,0.4375,0.25,0.1875,0.125,0.0625” | size unit is MB, split the table groups by table size, enabled when type=size | |
| migration.jobthread.split.indexes | “0,1,2,5,10,50,60,90,100,200,300,310” | split the table groups by index, enabled when type=index |
Feedback & Bug Report
欢迎使用,或加入我们使其变得更加完善。
- 问题可以直接 issue 我们
- Email: [email protected]
- Wechat: jawfneo
- 目前此项目已经被不少同学使用过了,也积赞了一些star,希望同学们多提供宝贵都意见或提交代码,多Pull Request
FAQ
1. config.properties 里面需要,替换sourcedbname, targetdbname,要用搜索替换:) 已有同学在此踩坑了..