引言
本文通过对卷类型的分析对比,来帮助读者选取生产环境最符合服务的挂载存储,命令可结合《glusterfs详解及kubernetes 搭建heketi-glusterfs》进行实验,下面进入正题
几种卷类型
- 基础卷:布式卷(distribute)、条带卷(stripe)、复制卷(replica)、纠错卷(Dispersed )
- 复合卷:分布式条带卷(distribute stripe)、分布式复制卷(distribute replica)、条带复制卷(stripe replica)、分布式条带复制卷(distribute stripe)
一、基础卷
以下创建挂载卷,均可通过以下命令进行查看、启用、停止、删除
#查看已创建挂载卷
gluster volume info
#启动挂载卷
gluster volume start gv0
#删除前,先停止挂载卷
gluster volume stop gv0
#删除挂载卷
gluster volume delete gv0 1. 布式卷(distribute voulme)
分布式模式,既DHT,是GlusterFS的默认模式,在创建卷时,默认选项是创建分布式卷。在该模式下,并没有对文件进行分块处理,而是通过hash算法分布到所有brick server上,只是扩大了磁盘空间,类似window中的跨区卷
distribute voulme特点
- 文件分布在不同的服务器,不具备冗余性。
- 更容易且廉价地扩展卷的大小。
- 单点故障会造成数据丢失,不具备容错性。
- 依赖底层的数据保护。
1.1. 创建命令
gluster volume create gv0 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv02. 条带卷(stripe volume)
条带模式,既Striped,类似RADI 0,在该模式下,根据偏移量将文件分成N块(N个条带节点),轮询地存储在每个Brick Server节点。节点把每个数据块都作为普通文件存入本地文件系统,通过扩展属性记录总块数和每块的序号。在配置时指定条带数必须等于卷中Brick 所包含的存储服务器数,在存储大文件时,性能尤为突出,但是不具备冗余性。
stripe volume特点
- 数据被分割成更小块分布到块服务器群中的不同条带区。
- 分布减少了负载且更小的文件加速了存取的速度。
- 没有数据冗余,不具备冗余性。
单点故障会造成数据丢失,不具备容错性。
⚠️RAID0称为条带化存储,将数据分段存储在各个磁盘中,读写均可以并行处理,因此读写速率为单个磁盘的N倍,没有冗余功能,任何一个磁盘的损坏就会导致的数据不可用。
RAID 0的特点:
- 数据条带式分布
- 没有冗余,性能最佳(不存储镜像、校验信息)
- 不能应用于对数据安全性要求高的场合
2.1. 创建命令
gluster volume create gv0 stripe 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv03. 复制卷(replica volme)
复制模式,既AFR,文件级别RAID 1,即同一文件保存一份或多份副本,每个节点上保存相同的内容和目录结构。复制模式因为要保存副本,所以磁盘利用率较低,如果多个节点上的存储空间不一致,那么将按照木桶效应取最低节点的容量作为该卷的总容量。复制卷具有冗余性,即使一个节点损坏,也不影响数据的正常使用。
replica volme特点
- 卷中所有的服务器均保存一个完整的副本。
- 卷的副本数量可由客户创建的时候决定。
- 磁盘利用率低。
具备冗余性
RADI1是镜像存储,没有数据校验,数据被同等的写入到2个或者多个磁盘中。
RAID 1的特点:
- 提供数据块冗余
- 写入速度相对慢, 但是读取速度比较快
3.1. 创建命令
gluster volume create gv0 replica 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv04. 纠错卷
Dispersed Volume是基于ErasureCodes(纠错码)的一种新类型的Volume(3.6版本正式发布该特性),类似于RAID5/6。通过配置Redundancy(冗余)级别提高可靠性,在保证较高的可靠性同时,可以提升物理存储空间的利用率。
详细请查看《GlusterFS Dispersed Volume(纠错卷)总结》
4.1. 创建命令
gluster volume create gv1 disperse 4 redundancy 1 10.8.4.92:/var/lib/heketi/mounts/gv1 10.8.4.93:/var/lib/heketi/mounts/gv1 10.8.4.131:/var/lib/heketi/mounts/gv1 10.8.4.132:/var/lib/heketi/mounts/gv1二、复合卷
1. 分布式条带卷(distribute stripe volume)
最少需要4台服务器才能创建。 brickserver数量是条带数的倍数,兼具distribute和stripe卷的特点,是DHT 与 Striped 的组合型。
1.1. 创建命令
gluster volume create gv0 stripe 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv0 10.8.4.131:/var/lib/heketi/mounts/gv0 10.8.4.132:/var/lib/heketi/mounts/gv02. 分布式复制卷(distribute replica volume)
最少需要4台服务器才能创建。brickserver数量是镜像数的倍数,兼具distribute和replica卷的特点,可以在2个或多个节点之间复制数据,是DHT 与 AFR 的组合型。
2.1. 创建命令
gluster volume create gv0 replica 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv0 10.8.4.131:/var/lib/heketi/mounts/gv0 10.8.4.132:/var/lib/heketi/mounts/gv03. 条带复制卷(stripe replica volume)
最少需要4台服务器才能创建。类似RAID 10,是 Striped 与 AFR 的组合型。
先组成RAID1,然后组成RAID0
RAID 10(又叫RAID 1+0)特点:
- 先按RAID 0分成两组,再分别对两组按RAID 1方式镜像
- 兼顾冗余(提供镜像存储)和性能(数据条带形分布)
3.1. 创建命令
gluster volume create gv0 stripe 2 replica 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv0 10.8.4.131:/var/lib/heketi/mounts/gv0 10.8.4.132:/var/lib/heketi/mounts/gv04. 分布式条带复制卷(distribute stripe volume)
至少需要8台 服务器才能创建。三种模式的混合。
4.1. 创建命令
gluster volume create gv0 stripe 2 replica 2 10.8.4.92:/var/lib/heketi/mounts/gv0 s10.8.4.93:/var/lib/heketi/mounts/gv0 10.8.4.131:/var/lib/heketi/mounts/gv0 10.8.4.132:/var/lib/heketi/mounts/gv0 exampleNode5:/var/lib/heketi/mounts/gv0 exampleNode6:/var/lib/heketi/mounts/gv0 exampleNode7:/var/lib/heketi/mounts/gv0 exampleNode8:/var/lib/heketi/mounts/gv0三、结合集群对比优缺点
1.结合《glusterfs详解及kubernetes 搭建heketi-glusterfs》一文讲解
1.1. 复制卷:volumetype: replicate:3
概述:
- 单个节点或硬盘挂损,不影响存储使用,数据不会丢失
- 对于kubernetes的StatefulSet类型服务,如es这种本身具有数据同步功能的服务,虽然达到了自动建设volume目的,但是一份数据备份了node数量x复制卷的Brick1数,得不偿失。
1.2. 分布式卷:volumetype: none
概述:
- 对于可以同步数据的高可用服务,推荐此卷。
- 对于普通服务(Deploy),此类型没有容错性和冗余数据。
- 方便扩展磁盘空间
1.3. 纠错卷:volumetype: disperse:4:2
概述:
- 对于普通服务(Deploy),此类型具备了高可用,而且提升了存储空间利用率,推荐使用。
2. 关于手动创建volume、PV,概述
Gluster:Quick Start Guide
请按照官网搭建,很简单,便不再赘述。
主要步骤:
- 创建罗磁盘
- 磁盘分区
- 磁盘挂载
glusterd peer probe server2新增gluster pool节点- gluster创建volume
对于重要的数据存储,kubernetes提供的三种存储方式不能满足,可手动创建volume、PV。作者更趋向条带复制卷(stripe replica volume),通常情况用分布式条带复制卷(distribute stripe volume)较多。
⚠️整理分析不易,对您如果有帮助,关注作者,留下你的喜欢,后续还有技术干料!!!
四、数据分布
以下内容引自《GlusterFS卷类型及数据分布分析》,可以直接在本文阅读或跳转阅读
1. Distributed volume
在该模式下,并没有对文件进行分块处理,文件直接存储在某个server节点上。“没有重新发明轮子”,这句话很好的概括了这种GlusterFS的设计思路。因为使用了已有的本地文件系统进行存储文件,所以通用的很多linux命令和工具可以继续正常使用。这使得GlusterFS可以在一个比较稳定的基础上发展起来,也更容易为人们所接受。因为需要使用到扩展文件属性,所以其目前支持的底层文件系统有:ext3、ext4、ZFS、XFS等。
由于使用本地文件系统,一方面,存取效率并没有什么没有提高,反而会因为网络通信的原因而有所降低;另一方面,支持超大型文件会有一定的难度。虽然ext4已经可以支持最大16T的单个文件,但是本地存储设备的容量实在有限。所以如果有大量的大文件存储需求,可以考虑使用Stripe模式来实现,如考虑新建专门存储超大型文件的stripe卷。

功能:
将文件存放在服务器里,如上图,File1和File2存放在server1,而File3存放在server2,文件都是随机存储
2. Stripe volume
其实Stripe模式相当于raid0,在该模式下,系统只是简单地根据偏移量将文件分成N块(N个stripe节点时),然后发送到每个server节点。server节点把每一块都作为普通文件存入本地文件系统中,并用扩展属性记录了总的块数(stripe-count)和每一块的序号(stripe-index)。stripe数必须等于volume中brick所包含的存储服务器数,文件被分成数据块,以Round Robin的方式存储在bricks中,并发粒度是数据块,大文件性能好
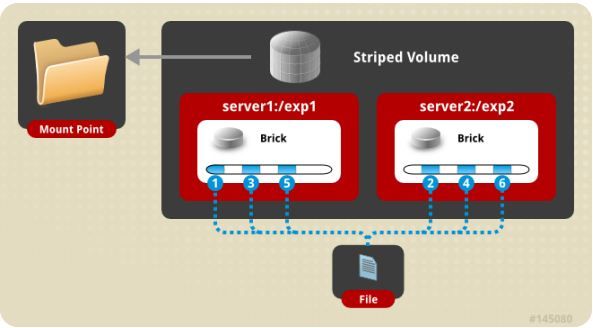
功能:
将文件存放在不同服务器里,如上图,File被分割为6段,1、3、5放在server1,2、4、6放在server2
3. Replicated volume
Replicated模式,也称作AFR(AutoFile Replication),相当于raid1,即同一文件在多个镜像存储节点上保存多份,每个replicated子节点有着相同的目录结构和文件。replicated模式一般不会单独使用,经常是以“Distribute+ Replicated”或“Stripe+ Replicated”的形式出现的。如果两台机的存储容量不同,那么就如木桶效应,系统的存储容量由容量小的机器决定。replica数必须等于volume中brick所包含的存储服务器数,可用性高。创建一个两两互为备份的卷,存储池中一块硬盘损坏,不会影响到数据的使用,最少需要两台服务器才能创建分布镜像卷。
Replicated模式是在文件的级别上进行的(相比较于HDFS),而且在创建卷volume时就确定每个server节点的职责,而且只能人工的进行调整。这样的话就相对的不灵活,如果一个节点A出了问题,就一定要用新的节点去替代A,否则就会出现一些问题隐患。
在Replicated模式下,每个文件会有如下几个扩展属性:
读写数据时,具体的情况如下:
- 读数据时:系统会将请求均衡负载到所有的镜像存储节点上,在文件被访问时同时就会触发self-heal机制,这时系统会检测副本的一致性(包括目录、文件内容、文件属性等)。若不一致则会通过changelog找到正确版本,进而修复文件或目录属性,以保证一致性。
- 写数据时:以第一台服务器作为锁服务器,先锁定目录或文件,写changelog记录该事件,再在每个镜像节点上写入数据,确保一致性后,擦除changelog记录,解开锁。
如果互为镜像的多个节点中有一个镜像节点出现了问题,用户的读/写请求都可以正常的进行,并不会受到影响。而问题节点被替换后,系统会自动在后台进行同步数据来保证副本的一致性。但是系统并不会自动地需找另一个节点来替代它,而是需要通过人工新增节点来进行,所以管理员必须及时地去发现这些问题,不然可靠性就很难保证。
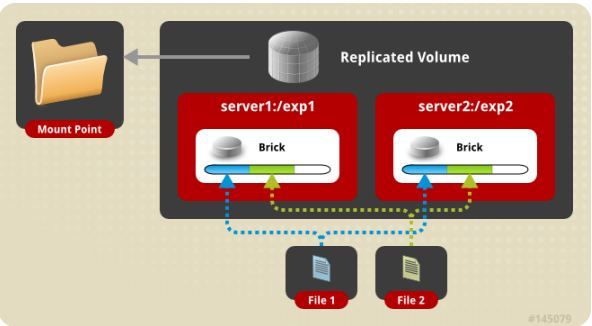
功能:
将文件存放在服务器里,如上图,File1同时存在server1和server2,File2也是如此,相当于server2中的文件是server1中文件的副本。
4. distribute stripe volume
分布式的条带卷,volume中brick所包含的存储服务器数必须是stripe的倍数(>=2倍),兼顾分布式和条带式的功能。每个文件分布在四台共享服务器上,通常用于大文件访问处理,最少需要 4 台服务器才能创建分布条带卷。
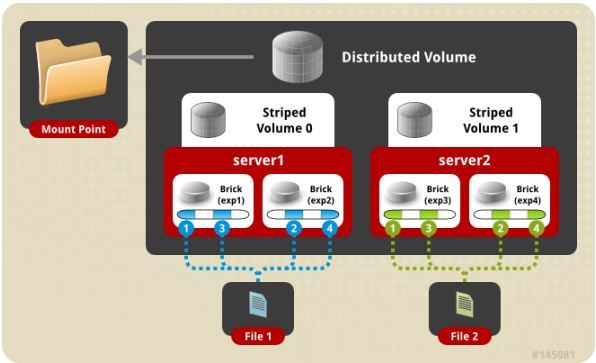
功能:
将文件存到不同服务器里,如上图,File被分割成4段,1、3在server1(exp1)中,2、4在server1(exp2)中。server2(exp3)1、3存放server1(exp1)中的备份文件,server2(exp4)2、4存放server1(exp2)中的备份文件。
5. distribute replica volume
分布式的复制卷,volume中brick所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
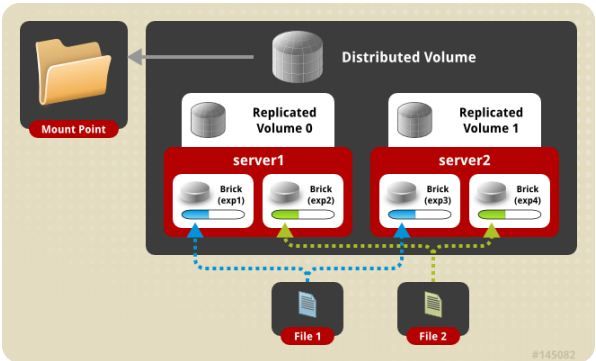
功能:
将文件备份随机存放在服务器里,如上图,server1(exp1)存放File1文件,Server1(exp2)存放File2文件。server2(exp3)存放File1的备份文件,server2(exp4)存放File2的备份文件。
6. stripe replica volume

功能:
将文件分割并备份随机存放在不同的服务器里,如上图,File被分割4段,1、3存放在server1(exp1)上,2、4存放在server2(exp4),server1上的(exp3)存放server2(exp4)的备份文件,server2上的(exp2)存放server1(exp1)的备份文件。
7. distribute stripe replica volume
分布式条带复制卷分布条带数据在复制卷集群。为了获得最佳效果,你应该使用分布在高并发的条带复制卷环境下并行访问非常大的文件和性能是至关重要的。

功能:
将文件分割并备份随机存放在不同服务器里,如上图,File被分割成4段,1、3存放在server1(exp1)中,2、4存放在server2(exp3)中。server1(exp2)存放server1(exp1)的备份文件,server2(exp4)存放server2(exp3)的备份文件。