机器学习算法总结(一)
1、TF-IDF文本相似度分析
余弦相似度计算个体间的相似性,即将两个个体的特征向量化,通过余弦公式计算两者之间的相似性。

通过计算模型公式可以明确的求出余弦相似度的值。那么对于我们写程序实现这个算法,就是把两个个体转换为向量,然后通过这个公式求出最终解。
比如向量a(x1, x2, x3, x4, x5),向量b(y1, y2, y3, y4, y5)。分子为(x1*y1)+(x2*y2)+(x3*y3)+(x4*y4)+(x5*y5),分母为sqrt(x1*x1+x2*x2+x3*x3+x4*x4+x5*x5)。
下面通过实际例子来看如何由一个句子转换为向量。
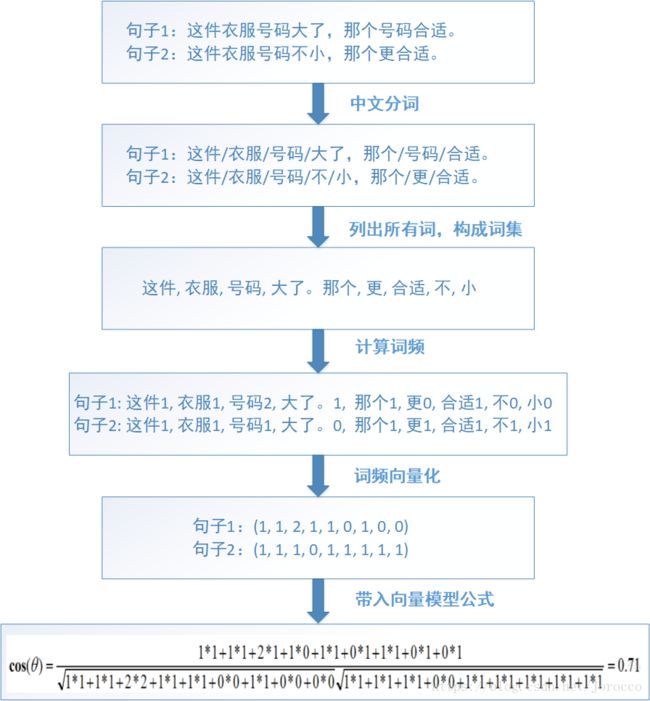
由图可知,两个句子的相似度计算的步骤是:
1、通过中文分词,把完整的句子根据分词算法分为独立的词集合
2、求出两个词集合的并集
3、计算各自词集的词频并把词频向量化
4、带入向量计算模型求出文本相似度
注意,词包确定之后,词的顺序是不能修改的,不然会影响到向量的变化。
以上是对两个句子做相似度计算,如果是对两篇文章做相似度计算,步骤如下:
1.找出各自文章的关键词并合成一个词集合
2.求出两个词集合的并集(词包)
3.计算各自词集的词频并把词频向量化
4.带入向量计算模型就可以求出文本相似度
句子的相似度计算只是文章相似度计算的一个子部分,关键词的提取可以采用jieba分词进行提取。
词频TF,词频是一个词语在文章或句子中出现的次数。如果一个词很重要,很明显是应该在一个文章中出现很多次的,但是这也不是绝对的,比如“地”,“的”,“啊”等词,它们出现的次数对一篇文章的中心思想没有一点帮助,只是中文语法结构的一部分而已。这类词也被称为“停用词”。所以,在计算一篇文章的词频时,停用词是应该过滤掉的。
如果某个词比较少见(在我们准备的文章库中的占比比较少),但是它在这篇文章中多次出现,那么它很可能反映了这篇文章的特性,正是我们所需要的关键词。在此,在词频TF的基础上又引出了反文档频率IDF的概念。一般来说,在一篇文章或一个句子来说,对于每个词都有不同的重要性,这也就是词的权重。在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性。比如一篇报道中国农业养殖的新闻报道。最常见的词(“的”、“是”、“在”)给予最小的权重,较常见的词(“国内”、“中国”、“报道”)给予较小的权重,较少见的词(“养殖”、“维基”)。所以刻画能力强的词语,权重应该是最高的。
将TF和IDF进行相乘,就得到了一个词的TF-IDF值,某个词对文章重要性越高,该值越大,于是排在前面的几个词,就是这篇文章的关键词。(在实际中,还要考虑词的词性等多维度的特性,动词,名词,形容词的刻画能力也是有所差别的;因社会热点而词的刻画性爆发式提高(比如 打call))。
下图是词频的计算方法:

词频标准化的目的是把所有的词频在同一维度上分析。词频的标准化有两个标准,第一种情况,得出词汇较小,不便于分析。一般情况下,第二个标准更适用,因为能够使词频的值相对大点,便于分析。
下面是反文档频率的计算方法:
![]()
针对这个公式,可能有人会有以下的疑问:
1.为什么+1?是为了处理分母为0的情况。假如所有的文章都不包含这个词,分子就为0,所以+1是为了防止分母为0的情况。
2.为什么要用log函数?log函数是单调递增,求log是为了归一化,保证反文档频率不会过大。
3.会出现负数?肯定不会,分子肯定比分母大。
TF-IDF = 计算的词频(TF)*计算的反文档频率(IDF)。通过公式可以知道,TF-IDF与在该文档中出现的次数成正比,与包含该词的文档数成反比。
利用TF-IDF计算相似文章步骤:
1)使用jieba分词,找出两篇文章的关键词
2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频)
3)生成两篇文章各自的词频向量
4)计算两个向量的余弦相似度,值越大就表示越相似
实例
#!/usr/bin/python
# -*-coding:utf-8-*-
# __author__ = 'ShenJun'
from gensim import corpora,models,similarities
import jieba
from collections import defaultdict
doc1=open("F:\\网络爬虫\\视频课程\\源码\\源码\\第7周\\gud.txt",encoding="utf-8").read()
doc2=open("F:\\网络爬虫\\视频课程\\源码\\源码\\第7周\\ljm.txt",encoding="utf-8").read()
data1=jieba.cut(doc1)
data2=jieba.cut(doc2)
#获取文本1中的分词,组成一个字符串
data11=""
for item in data1:
data11+=item+" "
#获取文本2中的分词,组成一个字符串
data21=""
for item in data2:
data21+=item+""
#合并文本1和文本2中的分词
documents=[data11,data21]
texts=[[word for word in document.split()]
for document in documents]#里面是两个列表,每个列表中包含一个文档的词汇
# print(texts)
#创建频率对象
frequency=defaultdict(int)
for text in texts:
for token in text:
#统计出词频,相同的词加1,frequency返回的是一个字典,词为key,数量为values
frequency[token]+=1
# #过滤掉频率比较低的词汇
# texts=[[word for word in text if frequency[token]>25
# for text in texts]]
#通过语料库建立字典,格式:{单词id,在多少文档中出现}
dictionary=corpora.Dictionary(texts)
dictionary.save("F:\\网络爬虫\\视频课程\\源码\\源码\\第7周\\wenben.txt")
'''
dictionary的一些用法:
# print(dictionary.dfs) #字典,{单词id,在多少文档中出现}
# print(dictionary.num_docs)#文档数目
# print(dictionary.num_pos)#所有词的个数
# for key in dictionary.items():
# print(key)#(17183, '龙骨随葬') 单词id:单词
# print(dictionary.num_nnz) #每个文件中不重复词个数的和
'''
#加载要对比的文档
doc3="F:\\网络爬虫\\视频课程\\源码\\源码\\第7周\\盗墓笔记.TXT"
d3=open(doc3,encoding="utf-8").read()
data3=jieba.cut(d3)
data31=""
for item in data3:
data31+=item+" "
new_doc=data31
#将要对比的文档通过doc2bow转化为稀疏向量
new_vec=dictionary.doc2bow(new_doc.split())#注意必须通过同一个字典dictionary
# print(new_vec)#词袋new_vec,列表[(单词id,词频)],结果:[(0, 108), (1, 75), (2, 74), (3, 25), (4, 32),...]
#对稀疏向量进行进一步处理,得到新的语料库
corpus=[dictionary.doc2bow(text) for text in texts]
# print(corpus)#结果:[[(0, 1), (1, 2), (2, 2), (3, 3), (4, 1), (5, 9), ...],[...]]
#将新的语料库通过tfidfmodel进行处理,得到tfidf
#完成对corpus中出现的每一个特征的IDF值的统计工作即词语普遍重要性的度量,返回一个权重
tfidf=models.TfidfModel(corpus)
# print(len(tfidf[corpus]))
# for i in tfidf[corpus]:
# print(i)
# '''
# 结果:
# [(0, 6.278644801648022e-05), (1, 0.00012557289603296043),..]
# 返回的是两个文档中的每一个特征的权重
#得到特征数
#dictionary.token2id:字典,{词,对应的单词id} dictionary.token2id.keys():单词个数
featureNum=len(dictionary.token2id.keys())
# #计算稀疏矩阵的相似性,稀疏矩阵相似度,从而建立索引,通过tfidf[corpus]和特征对应起来,则可直接找到相应的权重(相似度),也就是建立了索引
#???????????????
index=similarities.SparseMatrixSimilarity(tfidf[corpus],num_features=featureNum)
# #得到最终相似度结果
# print(tfidf[new_vec])
sim=index[tfidf[new_vec]]
# print(sim)
'''
[9.8796403e-01 1.8048293e-05]
9.8796403e-01表示盗墓笔记和gud的相似度
1.8048293e-05表示盗墓笔记和ljm的相似度
'''首先引入分词API库jieba、文本相似度库gensim
import jieba
from gensim import corpora,models,similarities以下doc0-doc7是几个最简单的文档,我们可以称之为目标文档,本文就是分析doc_test(测试文档)与以上8个文档的相似度。
doc0 = "我不喜欢上海"
doc1 = "上海是一个好地方"
doc2 = "北京是一个好地方"
doc3 = "上海好吃的在哪里"
doc4 = "上海好玩的在哪里"
doc5 = "上海是好地方"
doc6 = "上海路和上海人"
doc7 = "喜欢小吃"
doc_test="我喜欢上海的小吃"分词
首先,为了简化操作,把目标文档放到一个列表all_doc中。
all_doc = []
all_doc.append(doc0)
all_doc.append(doc1)
all_doc.append(doc2)
all_doc.append(doc3)
all_doc.append(doc4)
all_doc.append(doc5)
all_doc.append(doc6)
all_doc.append(doc7)以下对目标文档进行分词,并且保存在列表all_doc_list中
all_doc_list = []
for doc in all_doc:
doc_list = [word for word in jieba.cut(doc)]
all_doc_list.append(doc_list)把分词后形成的列表显示出来:
print(all_doc_list)[[‘我’, ‘不’, ‘喜欢’, ‘上海’],
[‘上海’, ‘是’, ‘一个’, ‘好’, ‘地方’],
[‘北京’, ‘是’, ‘一个’, ‘好’, ‘地方’],
[‘上海’, ‘好吃’, ‘的’, ‘在’, ‘哪里’],
[‘上海’, ‘好玩’, ‘的’, ‘在’, ‘哪里’],
[‘上海’, ‘是’, ‘好’, ‘地方’],
[‘上海’, ‘路’, ‘和’, ‘上海’, ‘人’],
[‘喜欢’, ‘小吃’]]
以下把测试文档也进行分词,并保存在列表doc_test_list中
doc_test_list = [word for word in jieba.cut(doc_test)]
doc_test_list[‘我’, ‘喜欢’, ‘上海’, ‘的’, ‘小吃’]
制作语料库
首先用dictionary方法获取词袋(bag-of-words)
dictionary = corpora.Dictionary(all_doc_list)词袋中用数字对所有词进行了编号
dictionary.keys()[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
编号与词之间的对应关系
dictionary.token2id{‘一个’: 4,
‘上海’: 0,
‘不’: 1,
‘人’: 14,
‘北京’: 8,
‘和’: 15,
‘哪里’: 9,
‘喜欢’: 2,
‘在’: 10,
‘地方’: 5,
‘好’: 6,
‘好吃’: 11,
‘好玩’: 13,
‘小吃’: 17,
‘我’: 3,
‘是’: 7,
‘的’: 12,
‘路’: 16}
以下使用doc2bow制作语料库
corpus = [dictionary.doc2bow(doc) for doc in all_doc_list]语料库如下。语料库是一组向量,向量中的元素是一个二元组(编号、频次数),对应分词后的文档中的每一个词。
[[(0, 1), (1, 1), (2, 1), (3, 1)],
[(0, 1), (4, 1), (5, 1), (6, 1), (7, 1)],
[(4, 1), (5, 1), (6, 1), (7, 1), (8, 1)],
[(0, 1), (9, 1), (10, 1), (11, 1), (12, 1)],
[(0, 1), (9, 1), (10, 1), (12, 1), (13, 1)],
[(0, 1), (5, 1), (6, 1), (7, 1)],
[(0, 2), (14, 1), (15, 1), (16, 1)],
[(2, 1), (17, 1)]]
以下用同样的方法,把测试文档也转换为二元组的向量
doc_test_vec = dictionary.doc2bow(doc_test_list)
doc_test_vec[(0, 1), (2, 1), (3, 1), (12, 1), (17, 1)]
相似度分析
使用TF-IDF模型对语料库建模
tfidf = models.TfidfModel(corpus)获取测试文档中,每个词的TF-IDF值
tfidf[doc_test_vec][(0, 0.08112725037593049),
(2, 0.3909393754390612),
(3, 0.5864090631585919),
(12, 0.3909393754390612),
(17, 0.5864090631585919)]
对每个目标文档,分析测试文档的相似度
#这个函数是采用余弦相似度方法,使用TFIDF将语料转换成词频表示,并计算出每个文档的相似度
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
#这个索引是测试文档与8个文档的相似度,它是按照余弦相似度计算出来的,语料库中每一行代表一个一个文档的向量(8个文档),没来一个测试文档它都会与语料库中的每一行向量计算其余弦相似度从而得出一个相似度,所以最终出来的应该是8个相似度
sim = index[tfidf[doc_test_vec]]
simarray([ 0.54680777, 0.01055349, 0. , 0.17724207, 0.17724207,
0.01354522, 0.01279765, 0.70477605], dtype=float32)
根据相似度排序
sorted(enumerate(sim), key=lambda item: -item[1])[(7, 0.70477605),
(0, 0.54680777),
(3, 0.17724207),
(4, 0.17724207),
(5, 0.013545224),
(6, 0.01279765),
(1, 0.010553493),
(2, 0.0)]
从分析结果来看,测试文档与doc7相似度最高,其次是doc0,与doc2的相似度为零。大家可以根据TF-IDF的原理,看看是否符合预期。
最后总结一下文本相似度分析的步骤:
1、读取文档
2、对要计算的多篇文档进行分词
3、对文档进行整理成指定格式,方便后续进行计算
4、计算出词语的词频
5、【可选】对词频低的词语进行过滤
6、建立语料库词典
7、加载要对比的文档
8、将要对比的文档通过doc2bow转化为词袋模型
9、对词袋模型进行进一步处理,得到新语料库
10、将新语料库通过tfidfmodel进行处理,得到tfidf
11、通过token2id得到特征数
12、稀疏矩阵相似度,从而建立索引
13、得到最终相似度结果