支持向量机,K近邻模型,回归树在不同配置下的性能比较
1 延续上一篇,还是采用美国波士顿房价测试数据,对支持向量机,K近邻模型以及回归树采用不同的参数配置,进行同一模型在不同配置下的回归预测性能的评估
2 实验代码及结果截图
#导入数据读取器
from sklearn.datasets import load_boston
boston=load_boston()
#数据分割
from sklearn.cross_validation import train_test_split
import numpy as np
X=boston.data
y=boston.target
#随机25%的测试样本数据,其他为训练样本数据
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=33,test_size=0.25)
#数据的标准化处理
from sklearn.preprocessing import StandardScaler
ss_X=StandardScaler()
ss_y=StandardScaler()
X_train=ss_X.fit_transform(X_train)
X_test=ss_X.fit_transform(X_test)
y_train=ss_y.fit_transform(y_train.reshape(-1,1))
y_test=ss_y.fit_transform(y_test.reshape(-1,1))
from sklearn.svm import SVR
#使用线性核函数配置向量机进行回归训练并预测
linear_svr=SVR(kernel='linear')
linear_svr.fit(X_train, y_train)
linear_svr_y_predict=linear_svr.predict(X_test)
#多项式核函数配置
poly_svr=SVR(kernel='poly')
poly_svr.fit(X_train, y_train)
poly_svr_y_predict=poly_svr.predict(X_test)
#径向基核函数配置
rbf_svr=SVR(kernel='rbf')
rbf_svr.fit(X_train, y_train)
rbf_svr_y_predict=rbf_svr.predict(X_test)
#回归性能的评估
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
print '三种不同配置下的支持向量机的回归分析'
print 'linear SVR'
print 'R-squared:',linear_svr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(linear_svr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(linear_svr_y_predict))
print 'Poly SVR'
print 'R-squared:',poly_svr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(poly_svr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(poly_svr_y_predict))
print 'rbf SVR'
print 'R-squared:',rbf_svr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(rbf_svr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(rbf_svr_y_predict))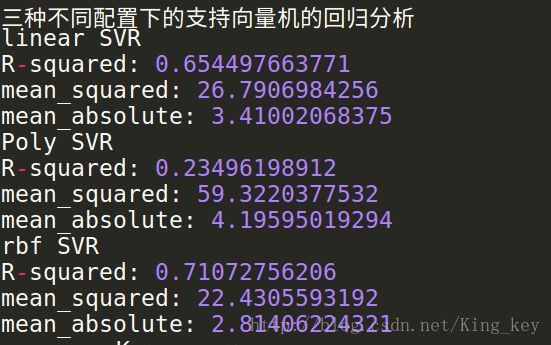
#两种配置下K近邻模型的回归性能分析
#导入K近邻模型
from sklearn.neighbors import KNeighborsRegressor
#初始化,使预测的方式为平均回归:weights='uniform'
uni_knr=KNeighborsRegressor(weights='uniform')
uni_knr.fit(X_train, y_train)
uni_knr_y_predict=uni_knr.predict(X_test)
#初始化预测方式为根据距离加权回归:weight='distance'
dis_knr=KNeighborsRegressor(weights='distance')
dis_knr.fit(X_train, y_train)
dis_knr_y_predict=dis_knr.predict(X_test)
#性能评估
print '两种配置下K近邻模型的回归性能分析'
print '平均回归配置'
print 'R-squared',uni_knr.score(X_test,y_test)
print 'mean_squared',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(uni_knr_y_predict))
print 'mean_absolute',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(uni_knr_y_predict))
print '距离加权回归'
print 'R-squared',dis_knr.score(X_test,y_test)
print 'mean_squared',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(dis_knr_y_predict))
print 'mean_absolute',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(dis_knr_y_predict))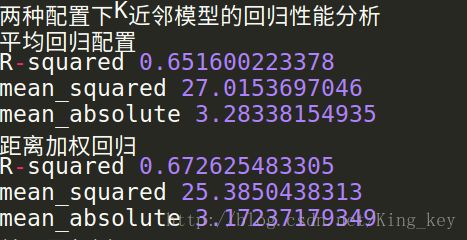
#回归树
#模型导入
from sklearn.tree import DecisionTreeRegressor
dtr=DecisionTreeRegressor()
#构建回归树
dtr.fit(X_train, y_train)
#单一回归树
dtr_y_predict=dtr.predict(X_test)
#评估
print '单一回归树'
print 'R-squared:',dtr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(dtr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(dtr_y_predict))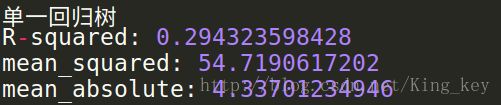
#集成模型
#模型导入
from sklearn.ensemble import RandomForestRegressor,ExtraTreesRegressor,GradientBoostingRegressor
#模型训练及预测
rfr=RandomForestRegressor()
rfr.fit(X_train,y_train)
rfr_y_predict=rfr.predict(X_test)
etr=ExtraTreesRegressor()
etr.fit(X_train,y_train)
etr_y_predict=etr.predict(X_test)
gbr=GradientBoostingRegressor()
gbr.fit(X_train, y_train)
gbr_y_predict=gbr.predict(X_test)
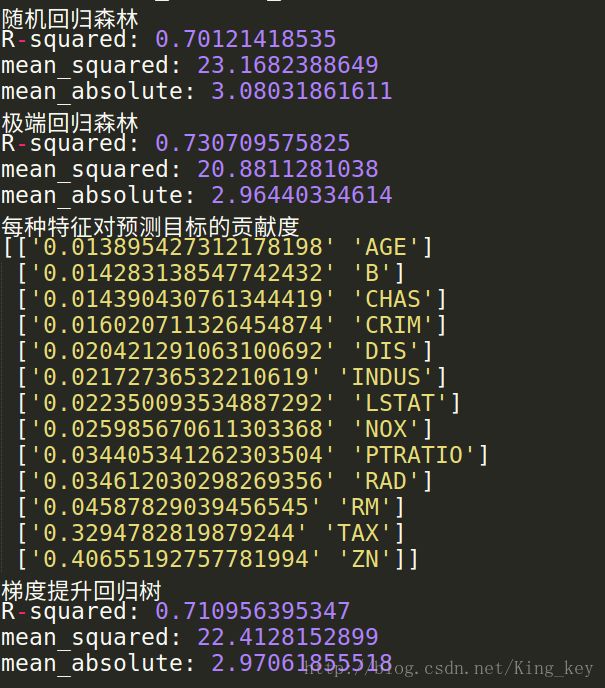
print '随机回归森林'
print 'R-squared:',rfr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(rfr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(rfr_y_predict))
print '极端回归森林'
print 'R-squared:',etr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(etr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(etr_y_predict))
#每种特征对预测目标的贡献度
print '每种特征对预测目标的贡献度'
print np.sort(zip(etr.feature_importances_,boston.feature_names),axis=0)
#梯度提升回归树
print '梯度提升回归树'
print 'R-squared:',gbr.score(X_test,y_test)
print 'mean_squared:',mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(gbr_y_predict))
print 'mean_absolute:',mean_absolute_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(gbr_y_predict))