如何一文读懂「进化策略」?这里有几组动图!

原文来源:blog.otoro.net
「雷克世界」编译:嗯~阿童木呀
![]() 本文将借助于一些视觉实例,阐述进化策略(Evolution Strategies,ES)是如何进行工作的。为了能够让读者更为容易地了解更多详细信息,将尽量保持文中所涉及的等式简明易懂,同时附加原始文章的链接。这是一系列文章中的第一篇文章,计划展示该如何将这些算法应用于MNIST、OpenAI Gym、RobSchool以及PyBullet环境的一系列任务中。
本文将借助于一些视觉实例,阐述进化策略(Evolution Strategies,ES)是如何进行工作的。为了能够让读者更为容易地了解更多详细信息,将尽量保持文中所涉及的等式简明易懂,同时附加原始文章的链接。这是一系列文章中的第一篇文章,计划展示该如何将这些算法应用于MNIST、OpenAI Gym、RobSchool以及PyBullet环境的一系列任务中。
介绍
神经网络模型具有很强的表达性和灵活性,如果我们能够找到合适的模型参数的话,那么就可以使用神经网络,解决许多具有挑战性的问题。深度学习的成功很大程度上来自于使用反向传播算法有效地计算目标函数在每个模型参数上的梯度的能力。有了这些梯度,我们就可以有效对参数空间进行搜索,以找到一个解,而这个解通常足够让我们的神经网络完成困难的任务。
不过,有许多问题是反向传播算法无法解决的。例如,在强化学习(RL)问题中,我们也可以训练一个神经网络做出决策,以执行一系列动作来完成环境中的某些任务。然而,当智能体在当前执行了一个动作之后,对未来给予智能体的奖励信号的梯度进行评估是非常重要的,特别是在未来,奖励是跨越了许多时间步长之后实现的情况下。另外,即使我们能够计算出精确的梯度,但也存在被困于局部最优解的问题,而这个问题在强化学习任务中是极其常见的。
困于局部最优解
可以这样说,强化学习的整个领域都是致力于研究这一信用分配问题的,并且近年来也取得了很大的进步。但是,当奖励信号稀疏时,信用分配仍然是个难题。在实际中,奖励可以是稀疏和嘈杂的。有时候,我们可能只得到一份奖励,这就像是年终的奖金支票,主要是取决于雇主,我们很难弄清楚为什么会这么低。对于这些问题,与其依赖于对策略进行未来的非常嘈杂且可能毫无意义的梯度评估,还不如忽略任何梯度信息,并尝试使用诸如遗传算法(GA)或ES这样的黑盒优化技术。
OpenAI发表了一篇名为《进化策略:作为强化学习的可扩展性替代方法》(https://blog.openai.com/evolution-strategies/)的论文,其中,他们展示了虽然进化策略在数据效率方面低于强化学习,但提供了不少益处。放弃梯度计算的能力使得该算法能够更有效地对其进行评估。也很容易将一个ES算法的计算分配给数千台机器进行并行计算。通过多次运行该算法,他们还发现,与RL算法发现的策略相比,使用ES发现的策略更具多样化。
我想指出的是,即使是识别诸如设计一个神经网络架构这样的机器学习模型问题,也是我们无法直接计算梯度的。虽然强化学习、进化、GA等可以应用于在模型空间中进行搜索,以及它们的模型参数可以用来解决某些问题,但在本文中,我将把重点放在应用这些算法来搜索预先定义的模型的参数上。
什么是进化策略(ES)?
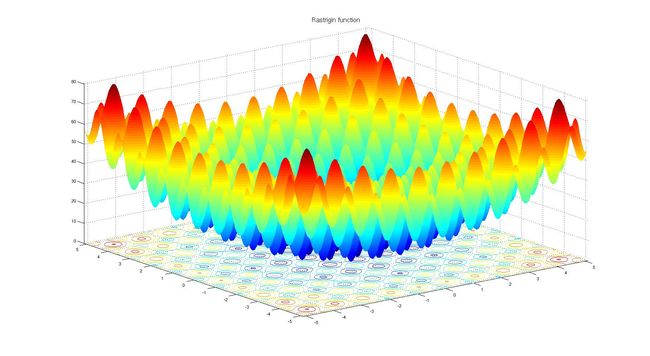
二维Rastrigin函数有很多局部最优解(资料来源:维基百科)
下图是自动调整2D Schaffer和Rastrigin函数的自上而下的曲线,用于测试连续黑盒优化算法的几个简单玩具问题的其中两个。图中较亮的区域代表F(x,y)的较高值。正如你所看到的那样,在这个函数中有很多局部最优解。我们的任务是找到一组模型参数(x,y),使得F(x,y)能够尽可能接近全局最大值。
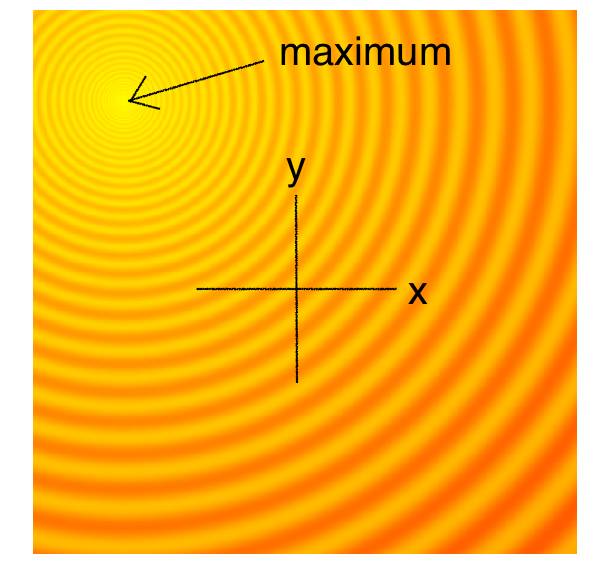
Schaffer-2D函数
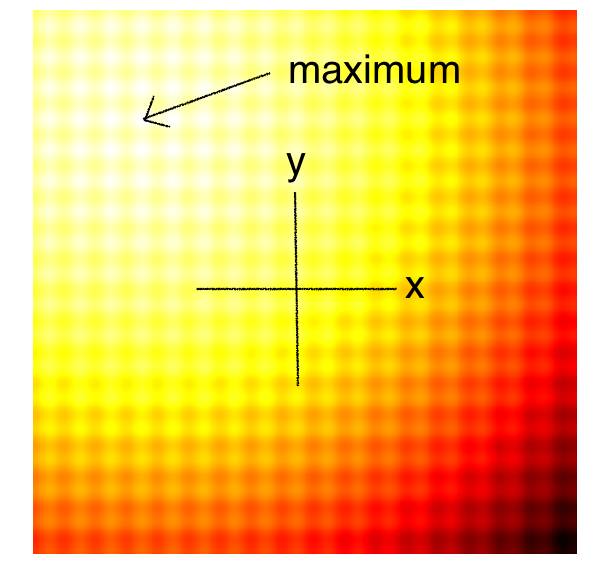
Rastrigin-2D函数
尽管进化策略有很多定义,但我们可以将进化策略定义为一种算法,它能够为用户提供一组候选解以对问题进行评估。该评估基于一个目标函数,该函数接受给定的解,并返回一个单一的适应性值。基于当前解的适应性结果,该算法将生成下一代候选解,而且极有可能比当前一代生成更好的结果。一旦用户对最好的解满意的话,迭代过程就会停止。
简单进化策略(ES)

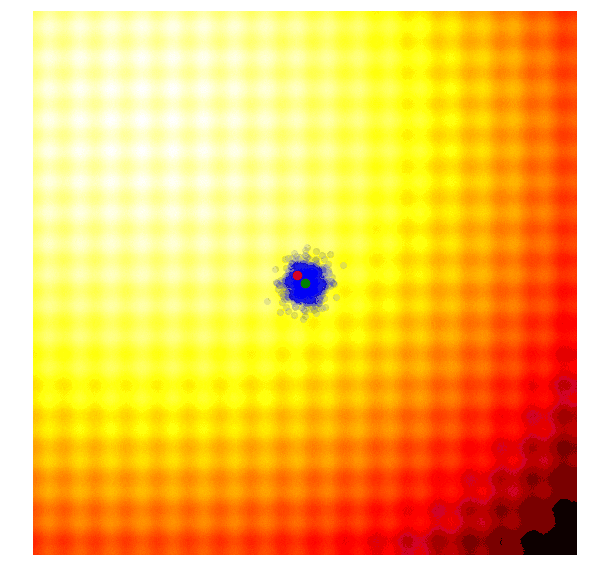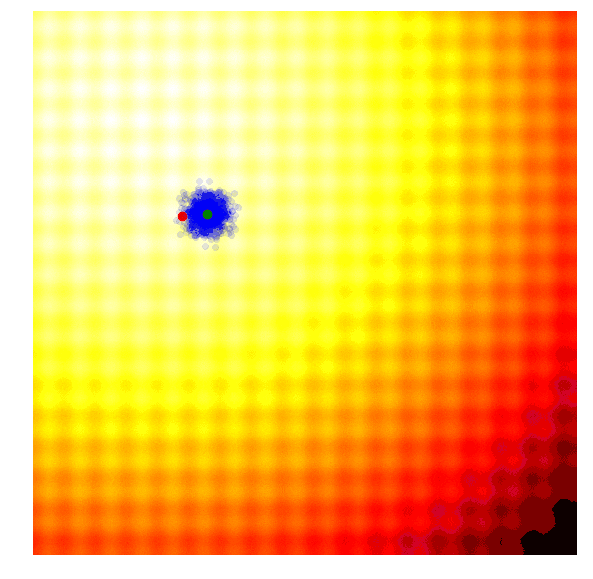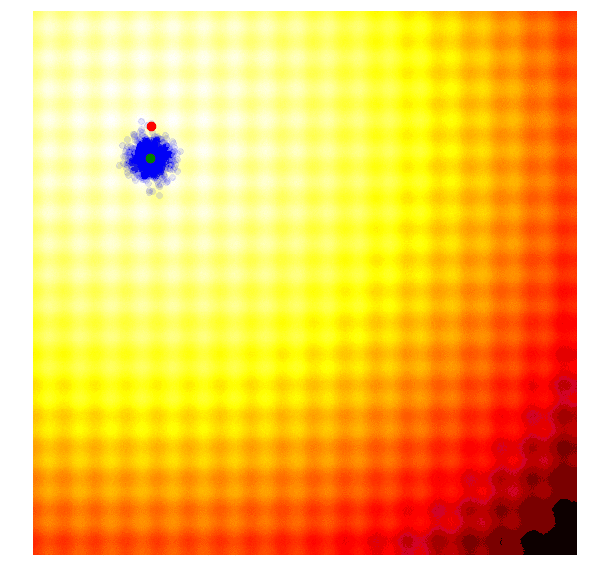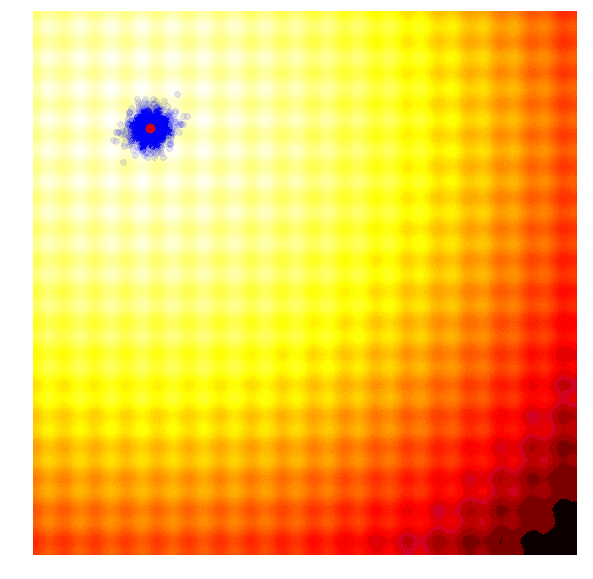
这个简单的算法通常只适用于简单的问题。鉴于其贪婪的本质,它抛弃了除了最好的解之外的所有解,并且可能容易陷入局部最优,以至更复杂的问题。而且从代表更多样化想法的概率分布中进行下一代采样,而不是对来自当前一代的最佳解采样,这一点可能更为有有益。
简单遗传算法(Simple GA)

遗传算法通过追踪一系列不同的候选解来重现下一代,以帮助实现多样性。然而,在实际中,“精英生存”式的大多数解往往会随着时间的推移而趋向于局部最优解。同时还有GA的更为复杂的变体,例如CoSyNe、ESP和NEAT,其想法是将群体中的类似解集中到不同的种类中,以保持更好的多样性。
协方差矩阵适应性进化策略(CMA-ES)
简单ES和简单GA的缺点是我们的标准偏差噪声参数是固定的。有时候,我们想要进行更多的探索、增加搜索空间的标准偏差。有时候,我们会非常有信心,觉得正接近一个很好的最优解,只想对解进行微调。我们基本上希望搜索过程如下:

上图中所示的搜索过程就是由协方差矩阵适应进化策略(CMA-ES)生成的。CMA-ES。
如果再一次对整个解进行设想的话,就整个搜索过程而言,如下图所示:

因为CMA-ES可以使用最佳解的信息来调整其均值和协方差矩阵,所以在距离最佳解很远时,它可以决定扩大至更广泛的网络,或者当距离最佳解很近时,缩小搜索空间。如果对CMA-ES算法进行高度简化描述的话,那就是:让想法变为现实。有关更多详细信息,可阅读CMA-ES作者Nikolaus Hansen编写的CMA-ES教程。(https://arxiv.org/abs/1604.00772)
该算法是最流行的无梯度优化算法之一,并且已经成为许多研究人员和从业者的首选算法。唯一真正的缺点就是,如果我们需要解决的模型参数的数量很大的话,其性能是个问题。
自然进化策略(NES)
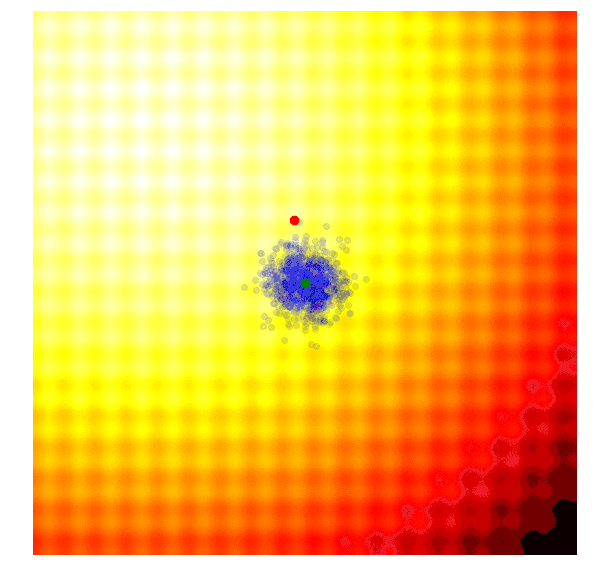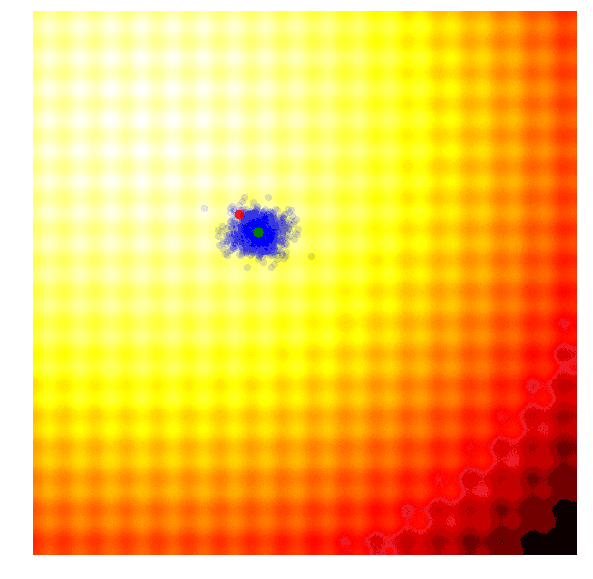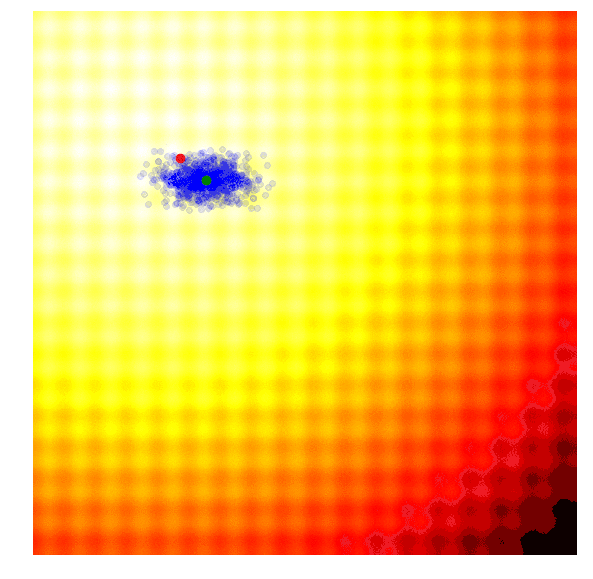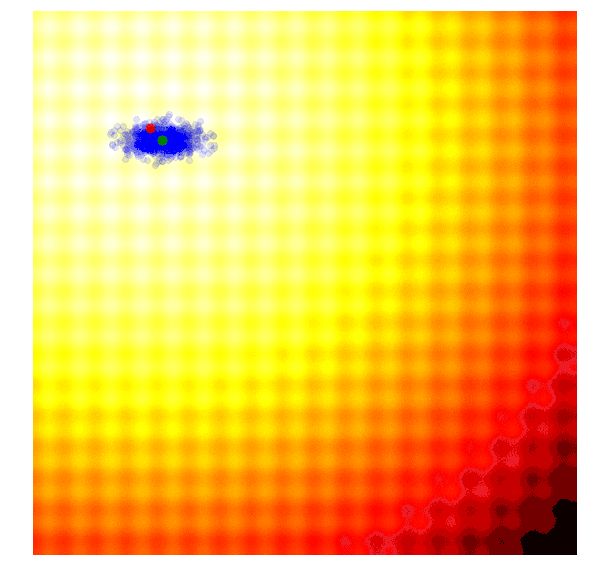
该算法能够动态地更改函数参数值,以便根据需要对解空间进行探索或微调。与CMA-ES不同的是,其在实现过程中没有相关性结构,所以我们只能得到对角椭圆样本、垂直或水平的样本,但原则上如果需要的话,我们可以推出更新规则以合并整个协方差矩阵,但这一点是要以牺牲计算效率为代价的。
很多人喜欢这个算法,因为同CMA-ES一样,搜索空间可以随着时间的推移而扩展或缩小。因为在该实现中没有使用相关参数,所以算法的效率是较高的。
OpenAI进化策略(OpenAI-ES)
在OpenAI的论文(https://blog.openai.com/evolution-strategies/)中,他们实现了一种进化策略,这是前面提到的REINFORCE-ES算法的一个特例。下面就是该策略:

Fitness Shaping
上面的大多数算法通常都是与Fitness Shaping法结合在一起的,比如基于rank的Fitness Shaping方法。Fitness Shaping使我们能够避免群体出现的异常值,从而避免了前面提到的近似梯度计算的影响。
MNIST
尽管ES可能是搜索更为新颖的解的一种方法,而这种解是用基于梯度的方法难以找到的,但是在许多可以计算高质量梯度的上,它的性能仍然要远远低于基于梯度的方法。例如,只有傻瓜才会尝试使用遗传算法进行图像分类,但世界上确实有这样的人存在。所以有时候这些探索也是会有成果的!
由于所有机器学习算法都应该在MNIST上进行测试,所以我也尝试使用这些不同的ES算法来寻找一个较小的、简单的2层卷积神经网络的权重,用来对MNIST进行分类,而这只是为了看一下相较于SGD,我们所处的位置。卷积大约只有11000个参数,所以我们可以应用较慢的CMA-ES算法。代码和实验都在这里。(https://github.com/hardmaru/pytorch_notebooks/tree/master/mnist_es)
以下是各种ES方法的训练结果。我们对在每轮结束时在整个训练集上表现最好的模型参数进行追踪,并在300轮之后在测试集上对该模型进行评估。有趣的是,测试集的准确性比那些得分较低的模型的训练集要高。
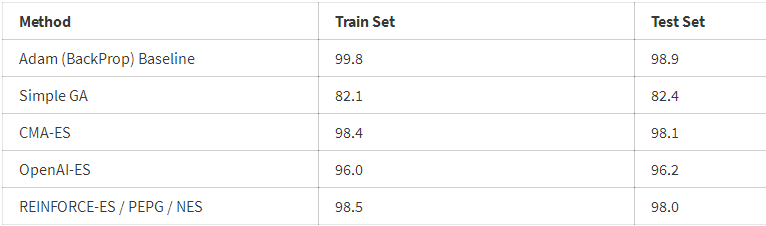
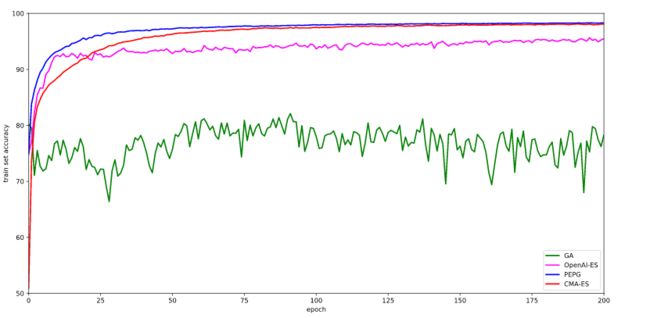
我们应该对此结果保持一种质疑态度,因为它们基于单次运行,而不是5—10次的平均运行。 基于单次运行的结果似乎表明,CMA-ES在MNIST任务中是最好的,但是PEPG算法没有那么大的影响。这两种算法都能达到98%的测试准确度,比SGD / ADAM基线低1%。也许动态地改变其协方差矩阵以及每一代的标准偏差参数的能力,使得它相较于OpenAI的更为简单的变体而言,能够更好地调整其权重。
详情查看原文链接:(http://blog.otoro.net/2017/10/29/visual-evolution-strategies/)
回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:中国人工智能产业创新联盟成立
ChinaDaily:China forms 1st AI alliance
证券时报:中国人工智能产业创新联盟成立 启动四大工程搭建产业生态“梁柱”
工信部网站:中国人工智能产业创新联盟与贵阳市政府、英特尔签署战略合作备忘录
 点击下图加入联盟
点击下图加入联盟

下载中国人工智能产业创新联盟入盟申请表

关注“雷克世界”后不要忘记置顶哟
我们还在搜狐新闻、雷克世界官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、雪球财经……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册