一文详解「固定」深度神经网络中的「分类器」将带来怎样的好处?

图:pixabay
原文来源:arxiv
作者:Elad Hoffer、Itay Hubara、Daniel Soudry
「雷克世界」编译:嗯~是阿童木呀
相信大家都知道,神经网络通常被用作各种任务的分类模型。一般来说,我们将学习仿射变换(affine transformation)放置在这些模型的末尾,以产生用于分类的每个类的值。这个分类器可以有大量的参数,它会随着可能的类的数量呈现线性增长,因此需要越来越多的资源。
在这项研究中,我们认为这个分类器可以是固定的,可以达到一个全局规模常数,而对于大多数任务来说,精度损失很小或几乎没有损失,从而使得在内存和计算方面受益颇多。此外,我们的研究结果表明,通过对具有一个哈达玛矩阵(Hadamard matrix)的分类器进行初始化,我们可以加快推理的速度。在接下来的内容中,我们将讨论目前对神经网络模型理解的含义。

深度神经网络已经成为机器学习中一种广泛使用的模型,并且在许多任务上取得了当前最先进的成果。这些模型通常用于执行分类的任务中,就像用卷积神经网络(CNN)将图像分类到语义范畴一样。目前来说,CNN模型被认为是视觉任务的标准模型,相较于以前的方法,它具有有更好的精确度(Krizhevsky等人于2012年、He等人于2016年、Szegedy 等人于2015年提出)。
训练神经网络模型并使用它们进行推理需要大量的内存和计算资源,因此,近来科学家们做了大量的研究以减小网络的大小。Han等人于2015年采用权重共享与规范(weight sharing and specification);Micikevicius等人于2017年使用混合精度将神经网络的大小减半。Tai等人于2015年,Jaderberg等人于2014年使用低秩近似(low rank approximations)加速神经网络。
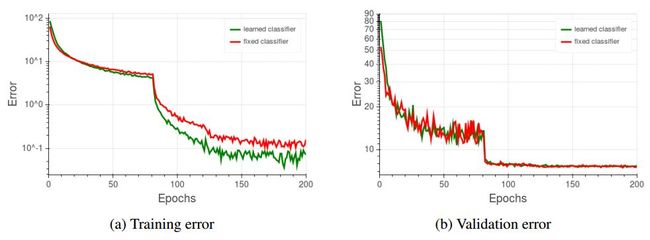
比较固定和学习分类器的训练和验证误差(ResNet56,Cifar10)
而Hubara等人于2016年、Li等人于2016年、Zhou等人于2016年则采用了一种更为积极的方法,其中,权重、激活和梯度被量化以进一步减少训练期间的计算。虽然对较小的模型进行积极的量化会带来很大的好处,但是极端的压缩率将导致精确度的损失。
在过去的研究中,人们注意到,预先定义的、随机的预测可以与学习仿射变换一起使用,以在若干任务中获得竞争性结果。而在这项研究中,提出了相反的观点——在使用常见的神经网络模型的情况下,即使不修改最终的输出层,它也能够学习有用的表示,而这些最终的输出层中往往含有大量随着类的数量呈现线性增长的参数。
卷积神经网络中的分类器
卷积神经网络(CNN)通常用于解决各种空间和时间任务。CNN通常由一堆卷积参数化层、空间池化层和完全连接层组成,由非线性激活函数分隔。较早的CNN体系结构(LeCun等人于1998年、Krizhevsky等人于2012年提出)在网络后期阶段使用了一系列完全连接层,从而可能使得其能够基于图像的全局特征进行分类。Springenberg等人经过研究证明,最终的分类器也可以被一个卷积层替换,其中,这个卷积层的输出特征映射与类的数量相匹配。
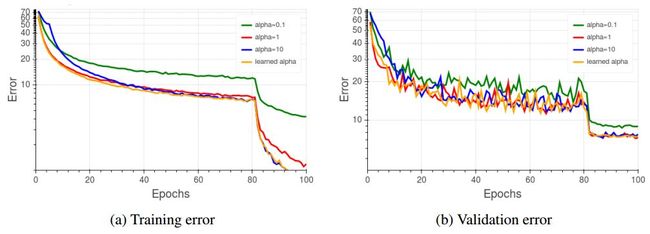
比较固定与训练的可变标量α(ResNet56,Cifar10)
尽管这些层添加到模型中的可训练参数的数量非常多,但是有一点是已知的,即它们对网络的最终性能具有相当的边际效应(marginal impact)(Zeiler与Fergus于2014年提出),并且当使用诸如矩阵分解和稀疏化等方法对模型进行简单训练后,很容易对这些可训练参数进行压缩和减少其数量(Han 等人于2015年提出)。此外,现代模型架构选择的特点是去除了大部分的完全连接层(Lin 等人于2013年、Szegedy等人于2015年、He等人于2016年提出),经研究结果表明,这将会带来更好的泛化效果、整体的精确度、以及可训练参数数量的大幅减少。
除此之外,大量的研究表明,CNNs可以通过一种度量学习方式(metric learning regime)进行训练(Bromley等人于1994年、Schroff等人于201年、Hoffer和Ailon于2015年提出),其中,没有引入明确的分类层,目标只考虑中间表示层之间的距离度量。所有这些性质都证明了这样一种观点,即完全连接层实际上是冗余的,在学习和泛化过程中起着很小的作用。
尽管它们起着明显的次要作用,但完全连接层依然被普遍用作分类层,从网络特征N维度转换到所需的类别C维度。因此,每个分类模型必须保持N•C数量的可训练参数,其随着类数量以一种线性方式增长。如Springenberg等人所示,当完全连接层被卷积分类器所取代时,这个性质仍然成立。
在这项研究中,我们秉持这样一种观点,即对于卷积网络的常见用例来说,用于最终分类变换的参数是完全冗余的,并且可以用预定的线性变换代替。在许多情况下,使用固定的变换可以使模型参数大大减少,并且可能带来计算收益。我们认为这有助于在具有低计算能力和较小内存容量的设备上部署这些模型。而且,由于我们保持分类器的固定,所以我们只需要更新更少的参数,从而降低了部署在分布式系统中的模型的通信成本。使用不依赖于类数量的固定变换可以使得模型能够扩展到大量的可能输出中,而不需要参数数目的线性成本。我们还认为,这些发现可能还揭示了之前的非线性层对于学习和泛化的重要性。
在这项研究中,我们建议从深度神经网络中使用的分类层中去除参数。经过大量的经验性研究结果表明,保持分类器的固定,将几乎不会导致在常见平衡数据集(如Cifar和Imagenet)的分类性能下降,同时还能够使得可训练参数的明显减少。我们认为,固定最后一层可以降低训练中计算的复杂度以及分布式学习中的通信成本。
此外,我们还认为,在实施得当的情况下,使用哈达玛矩阵作为分类器可能会带来一些计算收益,并节省内存,否则的话,将花费大量的变换系数。随着时间的推移,数据集往往会变得更加复杂(例如,Cifar100、ImageNet1K、ImageNet22k、JFT-300M和语言建模),我们认为在训练期间,资源匮乏的仿射变换应该保持固定,至少部分是这样的。我们还认为,应该探索新的有效方法以创建预定义的单词嵌入,因为它们需要大量的参数,而这些参数在学习新任务时应该是可以得以避免的。基于这些研究发现,我们认为未来的研究应该将重点放在神经网络的非线性部分所学习的表示——直到最后的分类器,因为它似乎是高度冗余的。

等式1
了解神经网络模型中使用的线性分类器在很大程度上是冗余的,这使得我们能够在训练和理解这些模型时考虑新的方法。
最近的研究提出了模型的泛化能力与其权重的各种标准相关量化之间的联系。这样的结果在我们的模型中可能被简化了,因为我们有一个标量变量(规模),这个变量似乎是模型中唯一的相关参数(因为我们对最后一个隐藏层进行了正则化,固定了最后一个权重层) 。
在二值化神经网络(Binarized Neural Networks)中,固定分类器的使用可能会得到进一步的简化,其中,在传播过程中激活和权重被限制在±1。在这种情况下,最后一个隐藏层的标准对于所有样本都是恒定的(等于隐藏层宽度的平方根)。这个常数可以被规范为比例常数α中,而且不需要像在等式1中那样对每个样本进行正则化。
我们还计划进一步探索更有效的学习单词嵌入的方法,其中分类器权重中类似的冗余可能表明更为简单的令牌表示形式——例如低阶或稀疏版本,从而像我们所提出的固定变换那样,带来巨大的优势。
原文链接:https://arxiv.org/pdf/1801.04540.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:中国人工智能产业创新联盟成立
ChinaDaily:China forms 1st AI alliance
证券时报:中国人工智能产业创新联盟成立 启动四大工程搭建产业生态“梁柱”
工信部网站:中国人工智能产业创新联盟与贵阳市政府、英特尔签署战略合作备忘录
 点击下图加入联盟
点击下图加入联盟

下载中国人工智能产业创新联盟入盟申请表

关注“雷克世界”后不要忘记置顶哟
我们还在搜狐新闻、雷克世界官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、雪球财经……
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册