YOLO3 + Python3.6 深度学习篇(中)- Transfer Learning 迁移学习
上一篇文章链接:
- YOLO3 + Python3.6 实时物体检测篇(上)- Transfer Learning 迁移学习
继上一次内容中,我们调用了 Google “图片下载” 的 API 接口通过简易爬虫的方法抓下了一卡车的图片信息,在整个环节中可以算是完成了第一步:搜集数据。但是我们需要通过一个机制,一个电脑看得懂的方法,告诉电脑图片里面的东西分别是什么,而这个机制就是使用 XML 文件去记录图片内容信息,从图片名称,物件坐标位置,物件名称,图片像素点... 等等信息完整记录于此。
之所以使用 XML 作为记录标记图片信息的方式原因在于它是一个除了 JSON 之外,极为明确且通用的一种记录方式,并且从学术论文和相关单位研究中也都可以看到研究人员使用此类档案作为他们标记图片的方式,与他们的模型良好的整合在一起。随着计算机发展的时间到现在,XML 的配套函数包也都已经健全,只要简单地引用相关函数功能,就可以轻松建立一个 XML 文件。
PASCAL Visual Object Classes
实战中,一个完整的 XML 文件内容长这样的 [点击] ,在 YOLO 的官网中也有相关的数据库 [点击] 介绍并提供下载,而他们统一遵循着一个名为 VOC 的数据训练集(官网 [点击] ) 所使用的文档规则,搜集文章的时候读到一篇说明比较清楚的内容 [点击] 供大家参考。
由于这个训练集是单位发起的一个挑战赛,每个参赛单位都以训练集的统一格式作为他们模型输入端口的资料展开训练,所以很快的这类的文档也逐渐沉淀成为所谓的 “业内标准”。
训练集里面的图片又一个共通性,其大小被约束在一个范围区间内,并且在一开始训练的第一步就是重新整合数据集里面的图片大小,做到 “大一统” 的目的后,才来开始谈训练过程和结果。
Data Labeling 标记数据
于实战中使用到的 Python module 有:(模块引用名: 使用文档)
- os: https://docs.python.org/3/library/os.html
- cv2: 官网 [https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_tutorials.html]
文档 [https://media... 点击] - matplotlib.pyplot: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.plot.html
- matplotlib.widgets: https://matplotlib.org/api/widgets_api.html
- lxml.etree: http://lxml.de/tutorial.html
- lxml.etree.cElementTree: http://lxml.de/2.2/tutorial.html
p.s. 更多记录会逐一完备并添加链接于此,更为深入的介绍个人使用每个包的心得与常见功能
The codes are written below in practice:
# 用来操控电脑相关文件属性与档案路径的模块
import os
# 用来操控图片,导入摄像头,处理色彩超级模块
import cv2
# 这是一个 matplotlib 下面的类,主要功能是制图
import matplotlib.pyplot as plt
# 这是一个 matplotlib 下面的类,提供格式小工具,这边使用的是方形选取
from matplotlib.widgets import RectangleSelector
# 一个用来处理 xml 文本的包,这边用来重新排布文本段落,使之更可视化
from lxml import etree
# 同上,只是它的引用名太长了,给个短的名字方便
import xml.etree.cElementTree as ET
# 人工输入一个我们目标的文件夹路径,让代码从此展开执行的旅程
folder_path = input("Enter the directory of the targeted folder: ")
# 一开始要全选出来的东西的名字也需要在这里 ”初始化“
Label_name = input("The object name being specified: ")
# 设置一个 list 容器,分别用来容纳之后经过鼠标产出的数据
TL_corner = []
BR_corner = []
Labels_list = []
# 定义一个 “事件“ 名为 mouse_click 的函数,在下面与 “RectangleSelector" 相连接
def mouse_click(press, release):
# 当需要对这些变量在函数里面被修改的时候,用上 global 会比较精确且保险
global TL_corner
global BR_corner
global Labels_list
# 如果第一个参数按下去的 .button 按钮是鼠标左键的话
if press.button == 1:
# 就把这个框框左上与右下的值分别贴到两个空的 list 中做保存,并且把一开始我们取好名字的 Label 也存入 list 中
TL_corner.append((int(press.xdata), int(press.ydata)))
BR_corner.append((int(release.xdata), int(release.ydata)))
Labels_list.append(Label_name)
# 如果第二个参数放开鼠标的 .button 按钮是左键的话
elif release.button == 3:
# 就把最近一次存进去 list 里面的元素给删了,并且打印字串告知
del TL_corner[-1]
del BR_corner[-1]
del Labels_list[-1]
print('-- Latest bounding box has been removed --')
# 定义一个函数,用来在中途改变我们要标记的物体
def change_label(event):
# 当需要对这些变量在函数里面被修改的时候,用上 global 会比较精确且保险
global Label_name
# 如果按下的按钮是滑鼠中间的滚轮(如果你的滑鼠没有滚轮那就 GG 了)
if event.button == 2:
# 继续让方框选择的功能开启
selectImg_RS.set_active(True)
# 重新输入定义标签名称
Label_name = input('The other object name being specified: ')
# 即便鼠标按下的功能不是滚轮,也还是要确保方框选择功能是被开启的状态
elif event.button != 2:
selectImg_RS.set_active(True)
'''
这只是个用来学习和测试的代码部分,之所以留下来就是为了深刻告诉自己:
在 matplotlib.widgets 这个模块中的 RectangleSelector 和诸多 plt.connect(‘event name’, function)
的不同之处,当时用 RectangleSelector 的时候,他所链接到的自定义 function 就可以有两个 arguments,
他们分别表示按下和放开方框的时候鼠标的坐标轴位置,而 connect 的 event 就不同。
def mouse_press(press):
global TL_corner
if press.button == 1:
TL_corner.append((int(press.xdata), int(press.ydata)))
elif press.button == 3:
print('-- Release button to remove your latest bounding box --')
else:
print('-- Please use mosue left click to select an area --')
def mouse_release(release):
global BR_corner
if release.button == 1:
BR_corner.append((int(release.xdata), int(release.ydata)))
elif release.button == 3:
del TL_corner[-1]
del BR_corner[-1]
else:
print('-- Please use mosue left click to select an area --')
拿这两个 function 做举例他们分别连接到的是 ‘button_press_event’ 和 ‘button_release_event’,
只容许他们在定义函数的时候有一个 argument 表示按下或是放开的瞬间鼠标坐标点的位置。
而那个 argument 自带的 .xdata | .ydata | .button 属性也是在 .connect 链接起来后自己产生的 attribute,
如果没有 connect,那是没有 .xdata 这类功能的。
'''
# 定义一个 xml 文件生成函数,需要方框的两个顶点坐标信息,图片放置位置,与最一开始的手动输入的目标文件位置
def xml_maker(TL_corner, BR_corner, file_path, folder_path):
# os.path 生成的 object 有一个 .name 功能打印改路径的最后一个文件名称
target_img = file_path.name
# 告知 xml 文件最后面应该存在哪个资料夹,os.path.split() 可以把最后一个文件名和前面路径分开成为一个 tuple 里面的两个不同元素
xml_save_dir = os.path.join(os.path.split(folder_path)[0],
os.path.split(folder_path)[1] + "_xml")
# 如果没有这个文件夹名字的话,创造一个该路径下的文件夹
if not os.path.isdir(xml_save_dir):
os.mkdir(xml_save_dir)
# 开始编辑 xml 文件内容,最外层的 Tag 叫 annotation
main_tag = ET.Element('annotation')
# main_tag 下面有许多子 tags,分别他们的内容要装的是对应到的文件夹名称,对应图片名称
ET.SubElement(main_tag, 'folder').text = os.path.split(folder_path)[1]
ET.SubElement(main_tag, 'filename').text = target_img
ET.SubElement(main_tag, 'segmented').text = str(0)
# 同理上面编辑步骤,把图片的尺寸资料记录于此
size_tag = ET.SubElement(main_tag, 'size')
ET.SubElement(size_tag, 'width').text = str(width)
ET.SubElement(size_tag, 'height').text = str(height)
ET.SubElement(size_tag, 'depth').text = str(depth)
# 由于 object 可能有很多个,甚至很多个 objects 要记录,这边需要迭代,把三个 list 容器重新 zip 在一起会方便许多
for La, TL, BR in zip(Labels_list, TL_corner, BR_corner):
# 同理上面编辑步骤,把 object 对应的名字等信息记录于此
object_tag = ET.SubElement(main_tag, 'object')
ET.SubElement(object_tag, 'name').text = La
ET.SubElement(object_tag, 'pose').text = 'Unspecified'
ET.SubElement(object_tag, 'truncated').text = str(0)
ET.SubElement(object_tag, 'difficult').text = str(0)
# 同理上面编辑步骤,把方框起来的坐标记录于此
bndbox_tag = ET.SubElement(object_tag, 'bndbox')
ET.SubElement(bndbox_tag, 'xmin').text = str(TL[0])
ET.SubElement(bndbox_tag, 'ymin').text = str(TL[1])
ET.SubElement(bndbox_tag, 'xmax').text = str(BR[0])
ET.SubElement(bndbox_tag, 'ymax').text = str(BR[1])
# 为了让 xml 排布能够漂亮,pretty_print=True 前面的 root 必须是对应的 object,所以做了一个转换过去然后又变回来的过程
xml_str = ET.tostring(main_tag)
root = etree.fromstring(xml_str)
xml_str = etree.tostring(root, pretty_print=True)
# 重新命名文件夹并重新整合储存路径,修改意味着先要拆开
# os.path.splitext 可以良好的把文件名和档名分成两个元素放在一个 tuple 里面
save_path = os.path.join(xml_save_dir,
str(os.path.splitext(target_img)[0] + '.xml'))
# 储存文件于该位置
with open(save_path, 'wb') as xml_file:
xml_file.write(xml_str)
# 定义一个函数,当对一张图片的事情做好了之后,跳到下一张图片时候需要做的事情
def next_image(release):
global TL_corner
global BR_corner
global Labels_list
# 如果按下的按钮是 Space 键,且方框选取功能是开着的
if release.key in [' '] and selectImg_RS.active:
# 那就呼叫刚定义好的生成 xml 函数
xml_maker(TL_corner, BR_corner, file_path, folder_path)
# 为了给自己方便看存了什么,在内容还没背归零最前先打印出来给我看看
print(TL_corner, BR_corner, Labels_list)
# 归零,并关掉该窗口
TL_corner = []
BR_corner = []
Labels_list = []
plt.close()
# 如果按的不是 Space 键,则打印下面句子
else:
print('-- Press "space" to jump to the next pic --')
# 只有当前 .py 文件呼叫的函数可以被执行,如果是 import 进来的文本里面有函数执行指令,该函数就会被挡住不执行
if __name__ == '__main__':
# 遍历每个一开始输入进去的路径里面的文件路径
for file_path in os.scandir(folder_path):
# 如果里面有些文件不符合预期,让程序报错了,用此跳开进到下一个文件
try:
# 习惯的画图手法,可以一次创造 figure 和 axis 两个 objects 并且还同时描绘了几个子窗口,非常方便
fig, ax = plt.subplots(1)
# 使用 opencv 读取图片信息,找出其长宽深度值
image = cv2.imread(file_path.path, -1)
height, width, depth = image.shape
# 并且由于在 matplotlib 显示图片是 RGB 格式,和 opencv 的BGR 顺序不同,需要转制
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 在 matpolotlib 基础上秀出图片内容
ax.imshow(image)
# 把 widgets 里面的 RectangleSelector 跟 mouse_click 做关联,给他一个名字原因纯粹是太长了,要开要关不方便
selectImg_RS = RectangleSelector(
ax, mouse_click, drawtype='box',
useblit=True, minspanx=5, minspany=5,
spancoords='pixels', interactive=True)
# 一样把其他上面设定好的函数与图片关联
plt.connect('button_press_event', change_label)
plt.connect('key_release_event', next_image)
# plt.connect('button_press_event', mouse_press)
# plt.connect('button_release_event', mouse_release)
# 这里把在图片上面做的事情 show 出来
plt.show()
# 如果报错,则直接跳到下一个循环中
except:
continue
这次的代码相对上次来说,是比较多的,做的事情也更为复杂和多元,主要代码任务排布顺序如下:
- 找到装载很多张图片档案的目标资料夹
- 把这些资料夹里面的照片一次一张的方式显示出来
- 在图片上面拉上方框选取我们肉眼判定的目标区域
- 如果区域拉错了,可以使用滑鼠右键拉方框删除最近一次拉的方框坐标点记录
- 按下滑鼠中间滚轮可以重新定义方框的名字
- 按下键盘上 “空白键” 储存那些拉好的方框坐标位置到 XML 文件中
- 重复步骤完成所有图片的标记工作
p.s. 一般图片标记量会在百来张图片的范围,要是希望图像识别能够更为准确,那么就需要甚至上千张的量去训练机器学习的模型。
标记环节也也因此成为这个项目中最耗费人力时间的部分,可能需要花两三个小时毫不费力的做着同样的动作,如图:
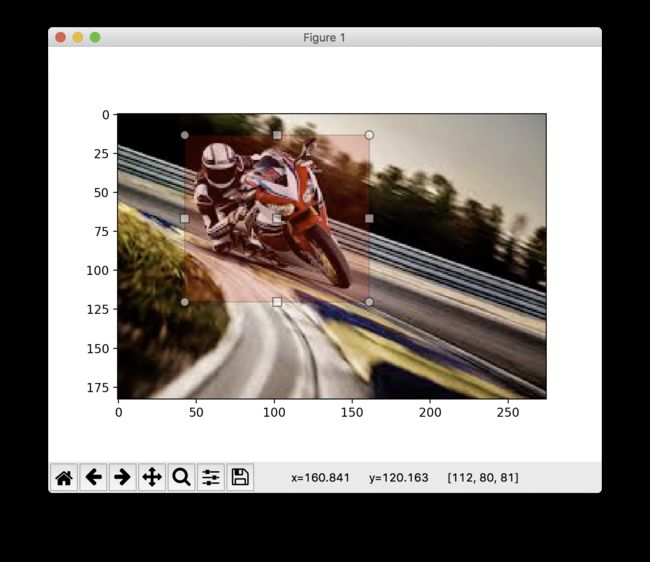
而标记出来的 XML 内容如下代码:
motorcycle
000026.png
0
338
149
3
细心的读者们可能会发现到这样的 XML 文件内容和上面链接里面展现出来的内容有三点不同之处:
和 两个 Tags 没有出现在上面结果中,原因在于训练过程中两个 Tags 的存在与否并不影响结果,因此标注图片生成 XML 的时候就没把它们放入其内容中去。 - 一张图不只有可以标注一个 object,而是可以有很多个 objects 并行,只要他们彼此的标签在同一个标签树的 “深度” 即可,并且分别做好各自方框坐标单位在 object “支” 里面的保存动作,训练起来就会顺利不出错!
里面的数值是浮点数,于样本的整数不一样,还不知道数字形式是否会影响到训练结果
重新细究代码
标记数据的过程不外乎就是把图片信息用手工的方式标记好,并记录在 XML 文件当中,中间牵涉到一些比较繁琐的细节。
- 初步是:文件存放位置,存放的文件夹名字,文件的名字,读取图片的名字,图片存放的位置,图片的尺寸
- 接着是:鼠标与图片的交互,键盘与流程的交互,选取图片区域的描述
- 最后是:如何归档于 XML 文件,如何重新拼接文件名和资料夹名,让文件成功落入指定位置
写代码的时候需要的不止是清晰的思路,很多时候人类在直觉上视为理所当然的事情,却需要在计算机上面拆分到极细的步骤让它去顺利执行。而就此项目而言,精简的步骤说明如下:
- 手动输入找到文件目标图片存放的文件夹位置,并用 os module 遍历这个文件夹里面的所有东西出来一个一个准备处理。
- 用 matplotlib 建立一个含有坐标轴的视窗,并用 cv2 module 把图片转换成 np.array 的数据形式,经过矩阵转制一下(因为颜色显示顺序两个包不同),把图片结果在建立好的坐标轴上面呈现。
- 开始在图片上面动手脚,画方框标注坐标位置等,但是这之前我们要先创建属于自己需要的工具,就是函数的意思,因此上面一堆的 def ... 开始定义按下鼠标,按下键盘分别代表什么意思,定义好之后把这些功能与图片在对的步骤用 plt.connect() 做触发链接。
- 接着把小工具在图片上做的事情 show() 出来,让整个过程更可视化一些。
- 最后触发键盘按钮,把 “图片上动手脚的记录” 存到 XML 文件之后,跳到下一张图片继续处理,直到所有图片都被处理完毕。