Python3爬虫小项目(一)之爬取抖音的小视频
版权声明:本文为博主原创文章,未经博主允许不得转载。https://blog.csdn.net/LInthunder/article/details/82929564
第一次写博客,请多多支持,下面这个是我参考的链接,我用的是Python3,然后可以爬取到一个人的全部抖音小视频作品。
https://blog.csdn.net/Ch97CKd/article/details/81571529
首先来看看,怎么找到在电脑端查看小视频呢,嘿嘿,首先抖音手机版找到个人主页,右上角分享个人名片,以链接的方式发送到电脑端。

我们以下面这个链接为例来继续:http://v.douyin.com/ds3s6d/,浏览器打开之后,按F12下拉,Network中查找,如图中user_id,_signature,dytk需要手动输入
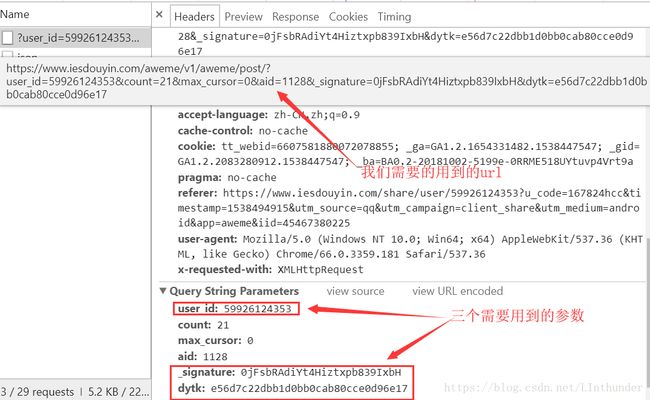
好了,然后看下浏览器响应,返回的是json格式,找到aweme_list里面是我们要的作品信息,而里面就是我们需要的作品名称与视频地址所在属性中。(还有一个自己看,在video属性中。)
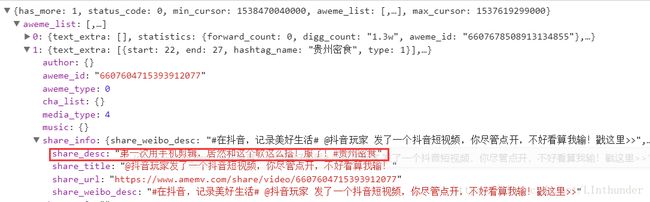
我们知道一个人作品太多的时候,一次肯定是不会完全显示的,当我们下拉的时候就发现发生了点变化,观察这两个链接发现:
https://www.iesdouyin.com/aweme/v1/aweme/post/?user_id=59926124353&count=21&max_cursor=0&aid=1128&_signature=0jFsbRAdiYt4Hiztxpb839IxbH&dytk=e56d7c22dbb1d0bb0cab80cce0d96e17
https://www.iesdouyin.com/aweme/v1/aweme/post/?user_id=59926124353&count=21&max_cursor=1537619299000&aid=1128&_signature=0jFsbRAdiYt4Hiztxpb839IxbH&dytk=e56d7c22dbb1d0bb0cab80cce0d96e17
区别仅在于max_cursor= 0 和 1537619299000,这个是说明此时未完全显示,到了最大的cursor才显示完全。而观察我们的response信息也能看到有个 "has_more:1" 这个就是说明有新页需要更新,直到has_more参数为0才罢休,自行观察浏览器响应。count最大值为32,意思是每次显示最大为多少个视频,所以我们设置为32是最好的。
注意以上观察操作均需要将Chrome浏览器调成手机浏览模式,同样F12中找到这个设置,如图。

下面开始贴代码咯,其实主要是url的找寻较为麻烦,可以多观察url的构造,代码倒是不是那么难理解。我封装成了一个类形式输出,然后自认为代码较为简洁
from urllib import request,parse
from selenium import webdriver
import json
from bs4 import BeautifulSoup
import requests
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
class Doyin_Download(object):
def __init__(self,user_id,signature,dytk):
print("======================================================================= ")
print(" By Juanjuan QingQuan \n ")
print(" Douyin_Video_Download\n ")
print(" Python3.6X ")
print("======================================================================= ")
#配置selenium
self.__headers__= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
self.__mobile_emulation__ = {
'deviceName':'iPhone X'
}
self.__options__ = webdriver.ChromeOptions()
self.__options__.add_experimental_option("mobileEmulation",self.__mobile_emulation__)
self.browser = webdriver.Chrome(options=self.__options__)
#保存好三个参数
self.user_id = user_id
self.signature =signature
self.dytk = dytk
def get_url(self):
#个人主页网址所得到的响应
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=0&aid=1128&_signature=%s&dytk=%s'%(self.user_id,self.signature,self.dytk)
url_list = [url]
self.browser.get(url)
response = self.browser.page_source
soup = BeautifulSoup(response,'lxml')
web_data = json.loads(str(soup.pre.string))
if web_data['status_code']==0:
#先判断到没到32个,这里因为如果没到32,将max_cursor更改后会出bug,这个自行查看F12
if len(web_data['aweme_list'])==32:
while web_data['has_more']==1:#只要has_more属性为1,就继续循环保存url
max_cursor = web_data["max_cursor"]
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(self.user_id,max_cursor,self.signature,self.dytk)
self.browser.get(url)
response2 = self.browser.page_source
soup2 = BeautifulSoup(response2,'lxml')
web_data = json.loads(str(soup2.pre.string))
url_list.append(url)
else:
max_cursor = web_data["max_cursor"]
url = 'https://www.amemv.com/aweme/v1/aweme/post/?user_id=%s&count=32&max_cursor=%s&aid=1128&_signature=%s&dytk=%s'%(self.user_id,max_cursor,self.signature,self.dytk)
url_list.append(url)
self.url_list = url_list
return url_list
def get_download_url(self,url_list):
download_url = []
title_list = []
if len(url_list)>0:
for url in url_list:#访问个人主页(可能分页了)的url,获得视频地址与每个视频的名称
self.browser.get(url)
response = self.browser.page_source
soup = BeautifulSoup(response,'lxml')
web_data = json.loads(str(soup.pre.string))
if web_data['status_code']==0:
for i in range(len(web_data['aweme_list'])):
download_url.append(web_data['aweme_list'][i]['video']['play_addr']['url_list'][0])
title_list.append(web_data['aweme_list'][i]['share_info']['share_desc'])
self.download_url= download_url
self.title_list = title_list
return download_url,title_list
def video_Download(self,download_url,title_list):#写入mp4
for i in range(len(download_url)):
title= str(title_list[i]).replace('/',' ')+'.mp4'
response = requests.get(download_url[i],headers=self.__headers__,verify = False)
f = open(title,'wb')
f.write(response.content)
print("%s is over"%title)
f.close()
def run(self):
url_list = self.get_url()
download_url,title_list = self.get_download_url(url_list)
self.video_Download(download_url,title_list)
if __name__ =="__main__":
print("请先利用浏览器打开分享的链接")
print("F12右侧拉到最下会有需要的三个参数")
user_id = input("user_id: ")
signature =input("signature: ")
dytk = input("dytk: ")
'''
#用于测试
user_id = "59926124353"
signature = "sf7VfhAa6lsb0ZX-afbEp7H-1W"
dytk = "e56d7c22dbb1d0bb0cab80cce0d96e17"
'''
start = Doyin_Download(user_id,signature,dytk)
start.run()
注意:dytk其实可以利用requests.get()方法访问你的分享链接而不去找响应,就可以获取到dytk了,这个可以自己探索哦。下图中的url即为http://v.douyin.com/ds3s6d/在浏览器中打开之后的url地址。
from bs4 import BeautifulSoup
from selenium import webdriver
url = "https://www.iesdouyin.com/share/user/59926124353?u_code=167824hcc×tamp=1538494915&utm_source=qq&utm_campaign=client_share&utm_medium=android&app=aweme&iid=45467380225"
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
mobile_emulation = {
'deviceName':'iPhone X'
}
options = webdriver.ChromeOptions()
options.add_experimental_option("mobileEmulation",mobile_emulation)
browser = webdriver.Chrome(options=options)
browser.get(url)
response = browser.page_source
browser.close()
soup = BeautifulSoup(response,'lxml')
print(soup)