Ubuntu下CIFAR10训练过程
1.数据准备
本实验使用的数据集是CIFAR-10,一共有60000张32*32的彩色图像,其中50000张是训练集,另外10000张是测试集。数据集共有10个类别,分别如下所示

在./data/cifar10目录下运行get_cifar10.sh脚本,得到解压缩的数据集,其脚本内容如下:
#!/usr/bin/env sh
# This scripts downloads the CIFAR10 (binary version) data and unzips it.
DIR="$( cd "$(dirname "$0")" ; pwd -P )"
cd $DIR
echo "Downloading..."
wget --no-check-certificate http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz
echo "Unzipping..."
tar -xf cifar-10-binary.tar.gz && rm -f cifar-10-binary.tar.gz
mv cifar-10-batches-bin/* . && rm -rf cifar-10-batches-bin
# Creation is split out because leveldb sometimes causes segfault
# and needs to be re-created.
echo "Done."主要是从官网下载http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz二进制的原始文件(163M),速度可能较慢,然后再对二进制压缩文件进行解压,解压后的结果如下:

主要是生成了原始训练数据以及其5个训练分块和1个测试分块,均为二进制文件。
2.数据格式转换
caffe只能识别lmdb和leveldb格式的输入文件,所以需要对原始数据进行格式转换,转换的文件位于./examples/cifar10目录下。在caffe根目录下运行
./examples/cifar10/create_cifar10.shcreate_cifar10.sh脚本文件的内容如下:
#!/usr/bin/env sh
# This script converts the cifar data into leveldb format.
EXAMPLE=examples/cifar10
DATA=data/cifar10
echo "Creating leveldb..."
rm -rf $EXAMPLE/cifar10_train_leveldb $EXAMPLE/cifar10_test_leveldb
./build/examples/cifar10/convert_cifar_data.bin $DATA $EXAMPLE
echo "Computing image mean..."
./build/tools/compute_image_mean -backend = leveldb
$EXAMPLE/cifar10_train_leveldb \
$EXAMPLE/mean.binaryproto
echo "Done."运行后将会在examples中出现数据集./cifar10_xxx_lmdb和数据集图像均值./mean.binaryproto。
3.训练
cifar-10训练的方法主要有全部训练和快速训练,两者的区别主要在于迭代的次数。快速训练迭代次数只有5000次,训练时间较少,相对应的精度有所下降,本次实验采用快速训练主要是出于时间效率方面的考虑。在caffe根目录下运行:
./examples/cifar10/train_quick.sh train_quick.sh文件的内容如下:
#!/usr/bin/env sh
TOOLS=./build/tools
$TOOLS/caffe train \
--solver=examples/cifar10/cifar10_quick_solver.prototxt
# reduce learning rate by factor of 10 after 8 epochs
$TOOLS/caffe train \
--solver=examples/cifar10/cifar10_quick_solver_lr1.prototxt \
--snapshot=examples/cifar10/cifar10_quick_iter_4000.solverstate可已发现,网络训练过程中有两个网络描述文件依次被使用,分别是cifar10_quick_solver.prototxt和cifar10_quick_solver_lr1.prototxt。两者的内容分别如下:
1.cifar10_quick_solver.prototxt
# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
# The train/test net protocol buffer definition
net: "examples/cifar10/cifar10_quick_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.001
momentum: 0.9
weight_decay: 0.004
# The learning rate policy
lr_policy: "fixed"
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 4000
# snapshot intermediate results
snapshot: 4000
snapshot_prefix: "examples/cifar10/cifar10_quick"
# solver mode: CPU or GPU
solver_mode: CPU2.cifar10_quick_solver_lr1.prototxt
# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
# The train/test net protocol buffer definition
net: "examples/cifar10/cifar10_quick_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.0001
momentum: 0.9
weight_decay: 0.004
# The learning rate policy
lr_policy: "fixed"
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 5000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/cifar10/cifar10_quick"
# solver mode: CPU or GPU
solver_mode: CPU4.实验结果
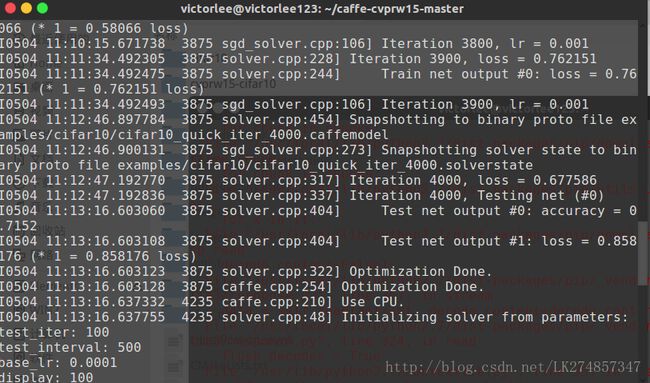
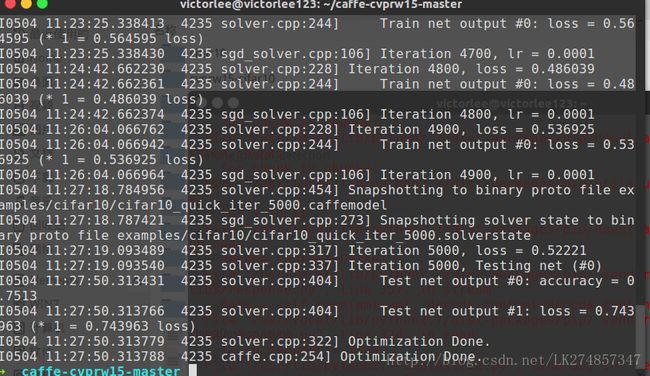
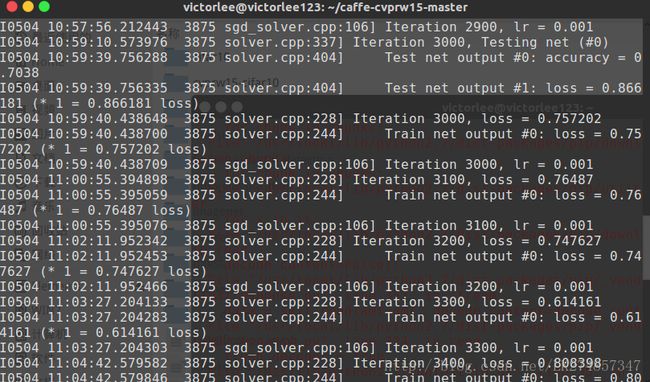
本次试验从上午10:20:27开始,上午11:27:50结束,历时1小时7分钟。
前4000次迭代结束时间为11:13:16,测试结果的准确度为accuracy=0.7152,loss=0.858176
到了5000次迭代结束的时候,测试结果的准确度为accuracy=0.7513,loss=0.743963
实验过程部分截图如下: