为了防止不提供原网址的转载,特在这里加上原文链接:
http://www.cnblogs.com/skabyy/p/7517397.html
本篇我们实现数据库的访问。我们将实现两种数据库访问方法来访问一个SQLite数据库——使用NHibernate实现的ORM映射访问和使用Dapper实现的SQL语句访问。然后完成前一篇未完成的CreateTweet和GetTweets接口。
在开始之前,先做一些准备工作,新建Domain层的Module:
public class MyTweetDomainModule : AbpModule
{
public override void Initialize()
{
IocManager.RegisterAssemblyByConvention(Assembly.GetExecutingAssembly());
}
}同时MyTweetApplicationModule添加对MyTweetDomainModule的依赖:
[DependsOn(typeof(MyTweetDomainModule))]
public class MyTweetApplicationModule : AbpModule安装NuGet包Abp.NHibernate到MyTweet.Domain和MyTweet.Infrastructure。
下面我们将完成这些步骤来实现数据库的访问:
- 配置数据库连接
- 新建
tweet表以及相应的Model类型 - 实现访问数据的Repository
- 用Dapper实现通过SQL访问数据库
使用Fluent NHibernate配置数据库连接
我们这里使用的数据库是SQLite数据库,其他数据库的配置也是类似的。我们将连接到App_Data文件夹下的一个SQLite数据库。新建LocalDbSessionProvider类并在构造函数处配置数据库连接。由于LocalDbSessionProvider实现了接口ISingletonDependency,模块初始化时LocalDbSessionProvider会以单例的形式注册到IoC容器。
public class LocalDbSessionProvider : ISessionProvider, ISingletonDependency, IDisposable
{
protected FluentConfiguration FluentConfiguration { get; private set; }
private ISessionFactory _sessionFactory;
public LocalDbSessionProvider()
{
FluentConfiguration = Fluently.Configure();
// 数据库连接串
var connString = "data source=|DataDirectory|MySQLite.db;";
FluentConfiguration
// 配置连接串
.Database(SQLiteConfiguration.Standard.ConnectionString(connString))
// 配置ORM
.Mappings(m => m.FluentMappings.AddFromAssembly(Assembly.GetExecutingAssembly()));
// 生成session factory
_sessionFactory = FluentConfiguration.BuildSessionFactory();
}
private ISession _session;
public ISession Session
{
get
{
if (_session != null)
{
// 每次访问都flush上一个session。这里有效率和多线程问题,暂且这样用,后面会改。
_session.Flush();
_session.Dispose();
}
_session = _sessionFactory.OpenSession();
return _session;
}
}
public void Dispose()
{
_sessionFactory.Dispose();
}
}这里每次用到session都只是简单地把上一次的session flush了,然后打开新的session。这会有效率和多线程冲突的问题。这里只是单纯为了展示实现数据库链接的方法而先用的简单实现。后面做工作单元(UoW)时会解决这个问题。
为了NHibernate能创建SQLite的连接,还需要安装System.Data.SQLite.Core到MyTweet.Web(其他数据库的话要安装其他相应的包)。
新建tweet表以及相应的Model类型
我们用tweet表保存tweet数据。tweet数据表接口以及对应Model属性如下:
| 数据库字段 | Model属性 | 类型 | 描述 |
|---|---|---|---|
pk_id |
PkId |
string |
主键 |
content |
Content |
string |
内容 |
create_time |
CreateTime |
string |
创建时间 |
使用SQLite工具新建MySQLite.db文件,并新建表tweet。
然后将MySQLite.db文件拷贝到App_Data文件夹下。
CREATE TABLE `tweet` (
`pk_id` TEXT,
`content` TEXT,
`create_time` TEXT NOT NULL,
PRIMARY KEY(`pk_id`)
);接下来新建Model类Tweet以及映射TweetMapper。Tweet继承Entity,其中的string表示Tweet的主键Id是string类型的。TweetMapper继承ClassMap,上面LocalDbSessionProvider构造函数执行到.Mappings(m => m.FluentMappings.AddFromAssembly(Assembly.GetExecutingAssembly()))这个方法时,会用反射的方式搜索程序集中ClassMap的子类,建立Model和数据库表的映射(Tweet和tweet表的映射)。
public class Tweet : Entity // 主键为string类型
{
public string Content { get; set; }
public DateTime CreateTime { get; set; }
}
public class TweetMapper : ClassMap
{
public TweetMapper()
{
// 禁用惰性加载
Not.LazyLoad();
// 映射到表tweet
Table("tweet");
// 主键映射
Id(x => x.Id).Column("pk_id");
// 字段映射
Map(x => x.Content).Column("content");
Map(x => x.CreateTime).Column("create_time");
}
} 实现Repository与增查接口
Repository即是DDD中的仓储,它封装了数据对象的增删改查操作。ABP的NhRepositoryBase已经实现了常用的增删改查功能,因此这里只需要继承一下就行了。
public interface ITweetRepository : IRepository { }
public class TweetRepository : NhRepositoryBase, ITweetRepository
{
public TweetRepository()
: base(IocManager.Instance.Resolve())
{ }
} 最后,修改MyTweetAppService,实现CreateTweet接口和GetTweets接口。
public class CreateTweetInput
{
public string Content { get; set; }
}
public class MyTweetAppService : ApplicationService, IMyTweetAppService
{
public ITweetRepository TweetRepository { get; set; }
public object GetTweets(string msg)
{
return TweetRepository.GetAll().OrderByDescending(x => x.CreateTime).ToList();
}
public object CreateTweet(CreateTweetInput input)
{
var tweet = new Tweet
{
Id = Guid.NewGuid().ToString("N"),
Content = input.Content,
CreateTime = DateTime.Now
};
var o = TweetRepository.Insert(tweet);
return o;
}
}大功告成!测试一下。用Postman调用CreateTweet接口插入一条tweet:
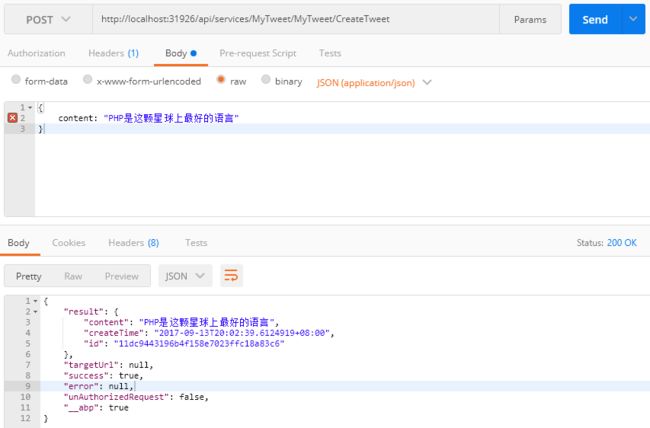
然后调用GetTweets查询:

ABP的依赖注入
可能有同学会疑惑,在MyTweetAppService中只声明了ITweetRepository类型的属性TweetRepository,但是并没有进行赋值,那么这个属性的对象实例是哪里来的呢?这就涉及到ABP框架的依赖注入策略了。
ABP基于Castle Windsor框架实现自己的依赖注入功能。依赖注入最基本的功能无非是注册(Register)和解析(Resolve)两个,注册功能将对象注册到IoC容器,解析功能根据类名或接口名获从IoC容器获取已注册的对象。我们可以直接通过IocManager获得Castle Windsor的IoC容器,直接进行注册和解析操作。
// 以单例模式注册类型T
IocManager.Register(Abp.Dependency.DependencyLifeStyle.Singleton);
// 以临时对象模式注册类型T,解析的时候会生成T的一个新对象
IocManager.Register(Abp.Dependency.DependencyLifeStyle.Transient);
// 从IoC容器解析已注册的类型T的对象
var obj = IocManager.Resolve(); 还有一些其他方法可以做注册和解析,具体可以参照ABP的文档。不过一般都不需要使用这些方法。ABP框架有一套依赖注入的规则,通过编写应用程序时遵循最佳实践和一些约定,使得依赖注入对于开发者几乎是透明的。
ABP的注册
基本上每个模块的初始化方法都会有这么一行代码:
IocManager.RegisterAssemblyByConvention(Assembly.GetExecutingAssembly());模块初始化时,ABP会搜索这个模块所在的程序集,自动注册满足常规注册条件与实现帮助接口的类。
常规注册
ABP自动注册所有Repositories, Domain Services, Application Services, MVC 控制器和Web API控制器。ABP通过判断是否实现了相应接口来判断是不是上述几类。例如下面的MyAppService:
public interface IMyAppService : IApplicationService { }
public class MyAppService : IMyAppService { }由于它实现了接口IApplicationService,ABP会自动注册,我们就可以通过IMyAppService解析出一个MyAppService对象。
通过常规注册的类的生命期都是transient(临时的),每次解析时都会生成一个新的临时对象。
帮助接口
ABP另外提供了ITransientDependency和ISingletonDependency两个接口。这两个接口前面也有用到过了。实现了ITransientDependency的类会被注册为transient。而实现了ISingletonDependency的类则被注册为单例。
ABP的解析
除了手工解析外,还可以通过构造函数和公共属性注入来获取类的依赖。这也是最常用的方法。例如:
public class MyAppService : IMyAppService
{
public ILogger Logger { get; set; }
private IMyRepository _repo;
public MyAppService(IMyRepository repo)
{
_repo = repo;
}
}ILogger从公共属性注入,IMyRepository从构造函数注入。注入过程对开发者是透明的,开发者不需要去写注入的代码。
QueryService - 使用SQL语句查询数据
实际开发中,经常需要直接使用SQL进行数据访问。查询逻辑比较复杂时直接使用SQL可以避免复杂的Mapper。通常复杂的Mapper会导致低效率的查询甚至会触发NHibernate一些奇怪的bug。实际上,在开发中,对于单纯的读取数据的功能(即使查询逻辑不复杂),我们建议直接使用SQL查询实现。直接使用SQL查询在调试时更为方便——直接拷贝SQL语句到SQL客户端执行即可检验该语句是否正确。
下面简要介绍一下使用Dapper来实现数据库查询功能。封装了sql查询操作的类我们称为QueryService。
首先,安装dapper包到MyTweet.Infrastructure。在MyTweet.Infrastructure实现QueryService的基类BaseQueryService:
public class BaseQueryService : ITransientDependency
{
private ISessionProvider _sessionProvider;
protected BaseQueryService(ISessionProvider sessionProvider)
{
_sessionProvider = sessionProvider;
}
public IEnumerable Query(string sql, object param = null)
{
var conn = _sessionProvider.Session.Connection;
return conn.Query(sql, param);
}
} Dapper给System.Data.IDbConnection接口扩展了Query方法,该方法执行SQL查询并将查询结构映射为IEnumerable类型的对象。为了使用这个扩展方法,还需在文件开头加个using语句。
using Dapper;QueryService并不在ABP依赖注入的常规注册规则里,所以让BaseQueryService实现了ITransientDependency,这样它的子类都会自动被注册到IoC容器。
接下来在MyTweet.Domain新建类TweetQueryService,它负责实现具体的SQL查询。方法SearchTweets实现了查询包含关键词keyword的所有tweet。
public interface ITweetQueryService
{
IList SearchTweets(string keyword);
}
public class TweetQueryService : BaseQueryService, ITweetQueryService
{
public TweetQueryService() : base(IocManager.Instance.Resolve())
{ }
public IList SearchTweets(string keyword)
{
var sql = @"select
pk_id Id,
content Content,
create_time CreateTime
from tweet
where content like '%' || @Keyword || '%'";
return Query(sql, new { Keyword = keyword ?? "" }).ToList();
}
} 最后在MyTweetAppService实现查询tweet数据的接口GetTweetsFromQS:
public ITweetQueryService TweetQueryService { get; set; }
public object GetTweetsFromQS(string keyword)
{
return TweetQueryService.SearchTweets(keyword);
} 测试一下:

结束
本文介绍了通过NHibernate以及Dapper进行数据库访问的方法,简单说明了ABP依赖注入策略。现在数据库连接部分的代码只是单纯为了演示的简单实现,没有做合理的数据库Session管理,会有效率和多线程冲突的问题。后面会加上工作单元(Unit of Work)来解决这些问题。
最后,放上代码链接:https://github.com/sKabYY/MyTweet-AbpDemo