一、正排索引与倒排索引
1、什么是正排索引呢?
以一本书为例,一般在书的开始都会有书的目录,目录里面列举了一本书有哪些章节,大概有哪些内容,以及所对应的页码数。这样,我们在查找一些内容时,就可以通过目录来定位到这些内容大概在哪页。因此,书的目录就可以称之为正排索引(目录页)。
2、什么时倒排索引呢?
还是以一本书为例,在有些书的最后,会有以词为单位的列表,指明了相应的词分别出现在了哪些页中,而这样的列表就称之为倒排索引(索引页)。
3、两者在搜索引擎中的对比
正排索引:文档ID到文档内容和单词的关联;
倒排索引:单词到文档ID的关联;
如下表所示:
| 文档ID | 文档内容 |
| 1 | mastering elasticsearch |
| 2 | elasticsearch server |
| 3 | elasticsearch stack |
| 单词 | 出现次数 | 文档ID:出现位置 |
| mastering | 1 | 1:0 |
| elasticsearch | 3 | 1:1,2:0,3:0 |
| server | 1 | 2:1 |
| stack | 1 | 3:1 |
上述两表就是正排索引与倒排索引的简单结构说明。
4、倒排索引的组成
倒排索引由两部分组成:
1)单词词典:它记录了所有文档的单词,同时记录了单词到倒排列表的关联关系。单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足高性能的插入与查询。
2)倒排列表:它记录单词所对应的文档组合体,主要是由倒排索引项组成的。
倒排索引项的内容包括:
a)文档ID;
b)词频(Term Frequency),代表单词在文档中出现的次数,用于相关性打分;
c)位置(Position),表示单词在文档中分词的位置,用于语句搜索;
d)偏移(Offset),记录单词开始和结束位置,用于实现高亮显示;
二、分词与分词器
1、分词:文本分析就是把全文转换成一系列单词(term/token)的过程,也叫做分词。
2、分词器:分词是通过分词器来实现的,它是专门处理分词的组件。可以使用ElasticSearch内置的分词器,也可以按需定制化分词器。
因此,除了在数据写入时用分词器转换词条,在匹配查询语句时,也需要用相同的分词器对查询语句进行分析。
分词器由三部分组成:
1)Character Filters:它的主要作用是对原始文本进行处理,例如去除HTML标签;
2)Tokenizer:主要作用是按照规则来切分单词;
3)Token Filter:将切分好的单词进行加工,例如:小写转换、删除停用词、增加同义词;
ElasticSearch内置了如下分词器:
1)Standard Analyzer:默认分词器,按词切分,转小写处理;
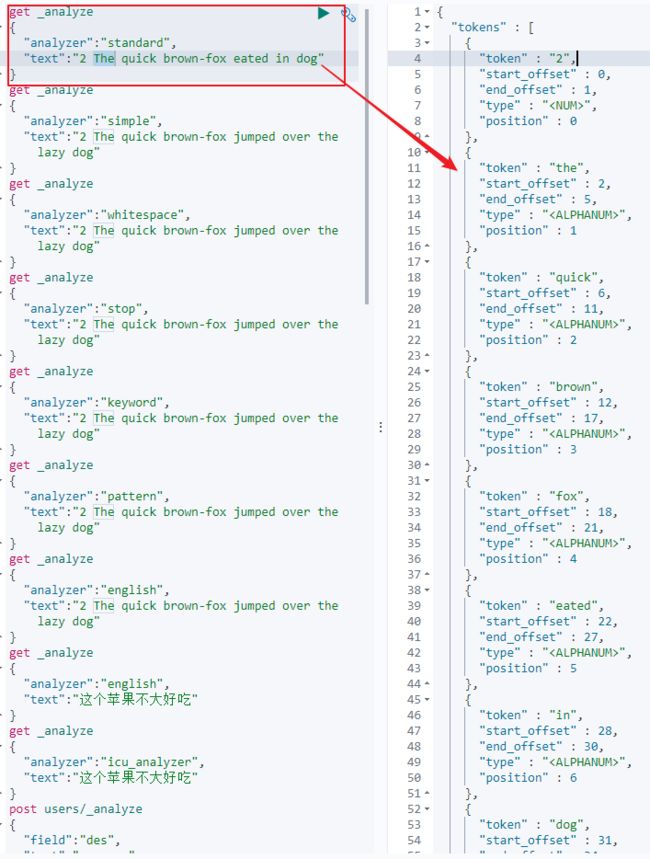
2)Simple Analyzer:按照非字母切分(符号被过滤),转小写处理;

3)Stop Analyzer:停用词过滤(is/a/the),转小写处理;

4)WhiteSpace Analyzer:按照空格切分,转小写处理;

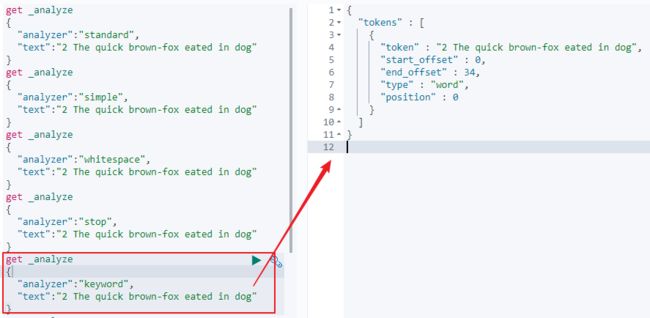
5)Keyword Analyzer:直接将输入当作输出,不分词;
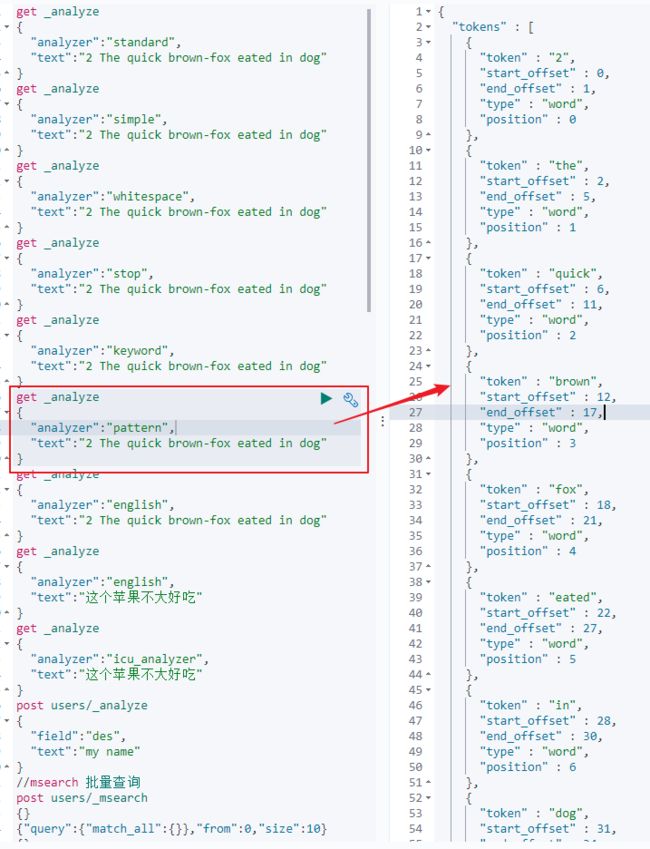
6)Pattern Analyzer:正则表达式分词,默认\W+(非字符分隔);
7)Language:提供了30多种常见语言的分词器;

8)Custom Analyzer:自定义分词器;
3、中文分词
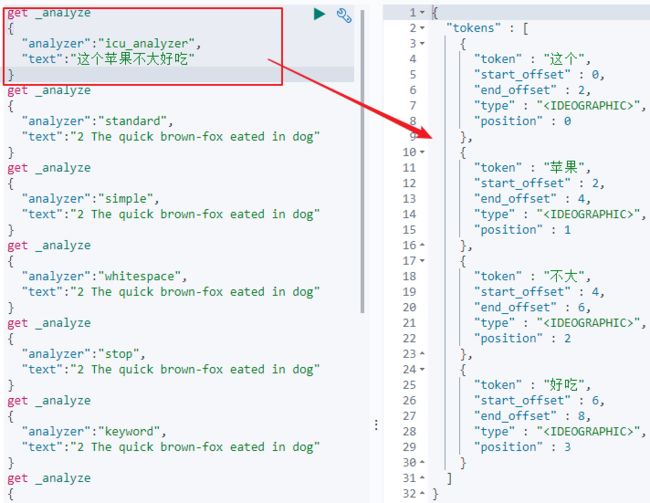
1)我们采用analysis-icu插件进行中文分词,可通过命令行:ElasticSearch-plugin install analysis-icu来安装此插件。该插件提供了Unicode支持,可以更好的支持亚洲语言。如下图所示:
2)社区中还有其他很好的分词器,如下:
a)IK:支持自定义词库,支持热更新分词字典;下载地址:https://github.com/medcl/elasticsearch-analysis-ik
b)THULAC:THU Lexucal Analyzer for Chinese,由清华大学自然语言处理和社会人文计算实验器出的一套中文分词器;下载地址:https://github.com/microbun/elasticsearch-thulac-plugin
大家可关注我的公众号

知识学习来源:《Elasticsearch核心技术与实战》