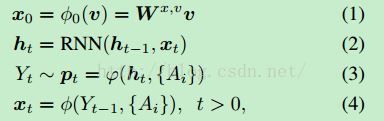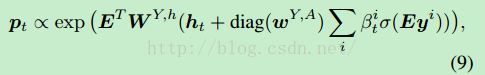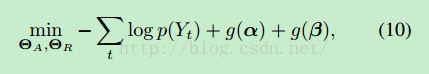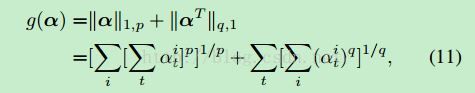这两年image caption的问题在CV领域非常火,就是输入一张图片,计算机自动输出对这张图片的文本描述。因为这个问题同时牵涉到了CV(Computer Vision)和NLP(Natural Language Processing),也牵涉到了当下非常流行的一些网络:CNN,RNN,LSTM,所以从14年这个问题变得火了起来。而本人也研究过一段这个问题,所以写点感悟,也方便以后复习。
image caption这个问题的算法个人认为有三类:
(1)基于image-text embedding的方法;
(2)基于目标检测的方法;
(3)基于CNN+RNN的方法。
关于这部分我会在之后的博客中给出详细的思想和论文补充。而本篇博客主要关注的是attention的方法。
attention机制引入的出发点有两条:(1)由于之前的caption问题中,对图像信息的提取基本上都是整张图像直接提取特征,这样用一个向量来表示一张图像,肯定会损失掉一部分的图像信息。
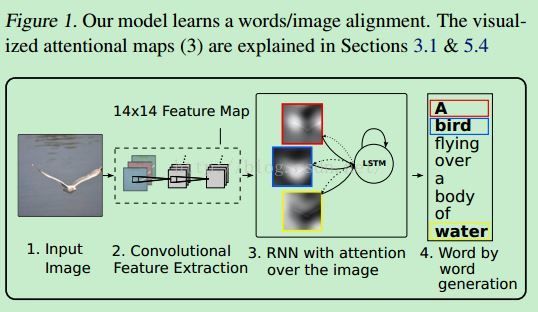
(2)正像人的视觉机制,看一张图片不会盯着一整张来看,肯定是有着重点和细节来看。因此,作者想到了在image caption问题中加入attention机制,就是在提取图像特征后,将图像特征和之前的预测出的单词信息共同输入RNN中计算隐层输出,这样就可以根据之前预测出的单词信息来提示应该关注图像的哪个部分,而不是漫无目的关注整张图像。(比如我们之前时刻预测出了“ride”这个单词,那么接下来应该预测的可能是horse,bike这种单词,而不是盲目的关注一些毫不相关的图像区域)。就目前的文章看,效果还是比Google的NIC等采用CNN+RNN的要好一些。
目前我看到attention文章有两篇:
[1]Show, attend and tell: Neural image caption generation with visual attention.
[2]Image Captioning with Semantic Attention.
两篇都发表在CVPR2016上,attention机制的引入也算是caption问题未来的一个发展方向,而不是说再改网络结构,拼接网络这么简单。
文章[1]就是普通的加入attention的思路,具体过程如下图所示:
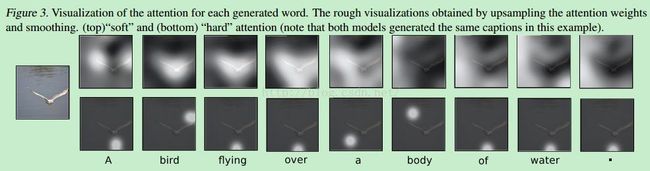
还提出了一个重要概念:soft attention 和 hard attention:
soft的意思指:由上一时刻推断出的单词来决定下一时刻对图像中哪部分着重注意,它是对图像中所有visual concepts都attention,只是根据不同的权值来确定对哪些部分关注更多,最终的attention结果也是对整张图像visual concepts进行加权和,生成attention map;
而hard则是指对特定某一个visual concept进行attention,而对其他的部分不引入attention。具体看下图:
实验结果是hard-attention效果更好一些
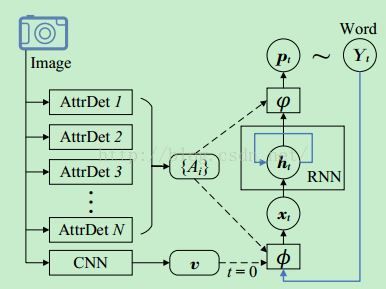
然后来看文章[2],这篇文章在attention的基础上,结合了图片的全局特征(top-down)和局部特征(bottom-up),比[1]获得了一些提升。照例先看算法流程图:
首先对于输入图片,提取了两种特征,一种是Visual Attributes:{Ai},也就是提取图像中的目标,对应bottom-up特征;一种是图像的全局特征 v,就是我们平时通过CNN提取的整张图像特征。其中提取Ai的时候,作者用了三种方法:(1)类似图像检索的方法,通过图像特征之间的相似性来得到最终一张图片中包含的目标;(2)multi-label模型[3],就是通过一个目标函数式,保证该图片中含有的标签排序高于图片中不存在的标签,这样能够保证图像标签的正确预测;(3)Fully-Convolutional-Network[4],就是采用语义分割的方法得到Attributes。实验证明第三种方法效果最好。
然后在t=0时刻,将全局特征输入RNN中,在t>0时刻,通过input attention模型:大fai(希腊字母),和output attention模型:小fai(希腊字母)来通过t时刻预测出的单词,来决定下一时刻对那些Attributes进行Attention。具体公式如下:
其中关键就是(3)(4)式,output attention模型和input attention模型的构建,具体公式如下图:
上面是input attention model的公式,(5)中的alpha就是图片中每个attributes的注意力权重,yt-1对应的是t-1时刻预测出的单词,yi对应的是attribute i。这里需要说明的是,因为图像中检测出的visual attributes也就是图像中目标的单词,如猫、狗等,所以和预测出的单词是在同一个词汇空间Y的,因此二者都可以用y表示,只是上下标有所不同。
接下来(6)式就是在(5)的基础上,对词汇特征进行embbeding降维,因为之前的词汇特征yt-1,yi都是one-hot表示法,维度较高不好处理。E是embbed矩阵。
然后就是最终的input attention模型了,(7)式对应(4)式,主要是由两部分组成,一部分是之前预测的单词Yt-1,一部分是对图像中的visual attributes {Ai}进行attention,其中wx,A用来确定这两部分的重要性,而在在attention部分是用的各块的加权和,所以对应soft attention。
下面介绍output attention model的公式:
(8)与(6)相似,只是对attribute yi要经过一个激活函数,这是为了保证输出与RNN隐层输出ht保持格式一致。
(9)与(7)相似,是最终的output attention model,对应上面的公式(3)。
最后一部分就是训练部分了:
从(10)中可以看出,前一步logp(Yt)和普通的image caption问题的目标函数一致,就是保证每次预测出的单词都是所有单词中概率最高的,只是在后面对输入输出attention模型中的权重加了两个约束,详见式(11)。其中[11]前半部分是对同一个属性i在每一时刻都被attention的惩罚;后半部分是对某一时刻对所有的属性都attention的惩罚。
本篇论文目前来看是做image caption问题中效果最好的。
本人知识有限,写作水平也一般,文中如有不妥之处,欢迎大家指出,互相交流,共同进步。另转载请注明出处
参考文献:
[1]Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015.
[2]Image Captioning with Semantic Attention. In CVPR, 2016
[3]Deep Convolutional Ranking for Multilabel Image Annotation. InICLR, 2014.
[4]Fully Convolutional Networks for Semantic Segmentation. InCVPR, 2015