样本不均衡之Borderline-SMOTE——smote算法的改进
许多现实领域存在着不平衡的数据集,如发现不可靠的电信客户、卫星雷达图像中的漏油检测、学习单词发音、文本分类、欺诈电话检测、信息检索和过滤任务等。在这些领域中,我们真正感兴趣的是少数类别而不是多数类别。因此,我们需要对少数群体作出相当高的预测。smote合成少数样本过采样技术是解样本不均衡的方法。本文提出了两种新的过采样方法,即Borderline-smote1和Borderline-smote2,对边界线附近的少数样本被过采样。对于少数类别的样本,实验表明,我们的方法比窒息和随机抽样方法获得更好的tp率和f值。
在解决不平衡数据集问题上,前人做了很多,先简单提下,可供研究者深入。
一个数据集中可能存在两种不平衡。一个是类别不平衡,在这种情况下,有些类别比其他类别有更多的例子。另一个是类内不平衡,在这种情况下,一个类的某些子集的示例比同一类的其他子集少很多。按照惯例,在不平衡的数据集中,我们称具有更多示例的类为多数类,具有较少示例的类为少数类。不平衡域的研究大多集中在两类问题上,因为多类问题可以简化为两类问题。按照惯例,少数类别标签是正的,多数类别标签是负的。表1说明了一个两类问题的混淆矩阵。表的第一列是示例的实际类标签,第一行显示了它们的预测类标签。tp和tn分别表示正确分类的正例和负例的数量,而fn和fp分别表示错误分类的正例和负例的数量。

数据极不平衡时,多数类别的样本更容易预测,对少数班级的表现较差。如果数据集极不平衡,即使分类器正确地对大多数示例进行分类,并且对所有少数示例进行了错误分类,分类器的准确性仍然很高,在这种情况下,准确度不能反映少数民族的可靠预测。因此,需要更合理的评估指标。
ROC曲线是评价学习器不平衡数据集的常用指标之一。ROC曲线二维图,y轴上绘制tp rate,x轴上绘制fp rate。fp rate表示错误分类的负样本的百分比,tp rate是正确分类的正样本的百分比。ROC曲线描述了收益(tp rate)和成本(fp rate)之间的相对权衡。F值也是不平衡问题的常用评价指标。它是召回和精度的结合,是存在不平衡问题的信息检索社区的有效度量。当召回和精度都很高时,f值很高,可以通过改变β的值来调整,其中β对应于精度相对于召回的相对重要性,通常设置为1。
对不平衡数据集的求解可以分为数据级和算法级。数据级的方法改变了不平衡数据集的分布,然后将平衡数据集提供给学习器,以提高少数类别的检测率。算法层面的方法对现有的数据挖掘算法进行了修改,或提出了新的算法来解决不平衡问题。
在数据层面,提出了不同形式的再抽样方法。最简单的重新抽样方法是上抽样和下抽样。前者复制少数类别的样本来,而后者则随机地去掉多数类别的一些样本。然而,随机上采样可能会使学习者的决策区域变得更小和更具体,从而导致学器者过拟合。下采样会减少一些有用的数据集信息。后来逐渐提出了许多改进的重采样方法,如启发式重采样方法、过采样和欠采样相结合、将重采样方法嵌入到数据挖掘算法中等。Kubat等人提出了一种启发式欠采样方法,通过消除大多数类的噪声和冗余实例来平衡数据集。Nitesh等人通过smote(合成少数类别过采样技术)方法对少数类别进行过采样,在少数类别实例与其选定的最近邻之间生成新的合成实例。SMOE的优势在于它使决策区域更大,更不具体。Gustavo等人采用过采样和欠采样相结合的方法来解决不平衡问题。Andrew Estabrooks等人提出了一种自适应选择最合适重采样率的多重重采样方法。Taeho Jo等人提出了一种基于聚类的超采样方法,同时解决了类内不平衡和类内不平衡问题。郭宏宇等。在推进过程中找出大多数和少数类的硬例子,然后从硬例子中生成新的合成例子,并将它们添加到数据集中。
算法级别的方法对数据集之外的算法进行操作。标准的增强算法,例如adaboost,增加了错误分类示例的权重,并减少了使用相同比例正确分类的示例,而不考虑数据集的不平衡。支持向量机本身在学习类边界时容易向少数类倾斜,从而增加少数类的误分类率。吴刚等。提出了通过改变SVMS的核函数来修改类边界的类边界对齐算法。黄开珠等。提出了有偏最小极大概率机(BMPM)来解决不平衡问题。考虑到多数类和少数类的可靠均值和协方差矩阵,BMPM可以通过调整测试集实际精度的下限来推导决策超平面。
SMOTE的改进方法:Borderline-SMOTE,为了实现更好的预测,大多数分类算法都试图在训练过程中尽可能准确地学习每个类的边界。边界和附近的例子(本文称之为边界示例)比远离边界的例子更容易被错误分类,因此对分类更为重要。根据上面的分析,那些远离边界的例子可能对分类没什么帮助。因此,提出了两种新的少数类别过采样方法,即borderline-smote1和borderline-smote2,其中只有少数类别的边界示例被过采样。这种方法是基于SMOE(合成少数民族过采样技术)。smote生成合成少数类别示例,以对少数类别进行过采样。对于每一个少数类别例子,计算其k(设为5 in-smote)最接近的同类邻居,然后根据过采样率从中随机选取一些例子。然后,沿着少数示例与其选定的最近邻之间的线生成新的合成示例。与现有的过度抽样方法不同,这种方法只是过度抽样或加强少数边界样本。首先,找出边界线少数类别的例子,然后从中生成合成的例子并添加到原始的训练集中。
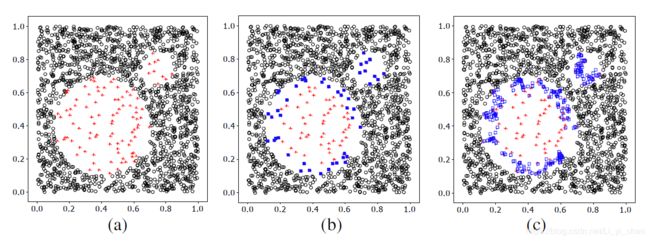
假设整个训练集是t,少数类是p,多数类是n,其中pnum和nnum是少数和多数例子的数量。
第1步。对于少数民族P类中的每一个样本pi(i=1,2,…,pnum),我们从整个训练集t中计算出它的m个最近邻。m个最近邻中的大多数例子用m'(0≤m'≤m)表示。
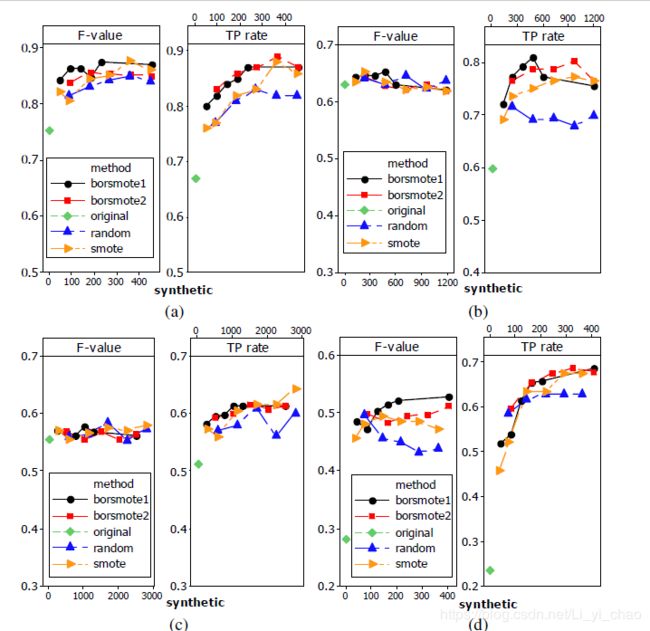
第2步。如果m’=m,即pi的所有m最近邻都是大多数例子,pi被认为是噪声,不按以下步骤操作。如果m/2≤m’ 第3步。处于危险中的例子是少数民族P类的边界数据,我们可以看到危险P。对于处于危险中的每个例子,我们从P计算出它的k最近邻。 第4步。在这一步中,我们从危险数据中生成s×dnum合成正例,其中s是1到k之间的整数。对于每个p'i,我们从p中的k个最近邻中随机选择s个最近邻。首先,我们计算p'i与其s个最近邻与p之间的差,dif j(j=1,2,…,s),然后将dif j乘以0到1之间的随机数rj(j=1,2,…,s),最后得到s个新的合成器。c少数民族的例子是在P'I和它的最近邻之间产生的。 对每一个处于危险中的P'I重复上述步骤,可以得到S×DNum合成实例,此步骤与smote类似。在上述程序中,p i、ni、p'i、dif j和合成j是向量。我们可以看到,新的合成数据是沿着少数边界示例和它们在同一类中最近的邻居之间的线生成的,从而加强了边界示例。borderline-smote2不仅从处于危险中的每一个例子及其p中的正最近邻生成合成的例子,而且从n中的最近负邻生成合成的例子。它与最近负邻之间的差乘以0到0.5之间的随机数,因此新生成的示例更接近于少数族类。 下图图(a)显示了数据集的原始分布,圆点代表大多数示例,加号代表少数示例。首先,我们应用smote法找出少数类别的边界例子,如图(b)中的实心正方形所示。然后,通过borderline-smote生成新的合成例子。合成示例如图(c)所示,带有空心正方形。图中可以看出,对少数类别的边界线及其附近的点进行过采样。 下面实验中,将smote、随机过采样法和Borderline-SMOTE1和Borderline-SMOTE2四种过采样方法应用于数据集,为了便于比较结果,对于每种方法,通过10倍交叉验证,得到tp率和f值。为了减少SMOE和我们的方法的随机性,这些方法的tp率和f值是三个独立的10倍交叉验证实验的平均结果。图中,(a)、(b)、(c)和(d)分别描述了四种过采样方法分别应用于Circle、PIMA、Satimage和Haberman时,少数民族的f值和tp率。图中还显示了C4.5原始数据集的f值和tp速率。 图中所示的结果显示:总的来说,以上四种抽样方法都有所提高。border-smote1在tp速率和f值上表现出色,borderline-smote2在tp速率上表现出色,因为它从少数边界示例和它们在多数类中最近的邻居生成合成示例,但是,该过程导致这两个类,因此在某种程度上降低了它的f值。 实验表明,该方法的性能较好,验证了该方法的有效性。在这方面的研究还有几个有待进一步考虑的主题。不同的策略来定义危险实例,以及自动自适应地确定危险实例的数量将是有价值的。我们的方法与欠采样方法的结合,以及我们的方法与一些数据挖掘算法的集成,也是值得尝试的。