python开发电影查询系统(一)—python实现后台数据
爬虫也学了很长一段时间了,虽然有些东西还不是很熟悉,但使用python和Django自己做了一个项目,即爬取http://www.bd-film.com/的电影信息,并将数据存储到本地,再通过Django做一个查询入口进行查询。
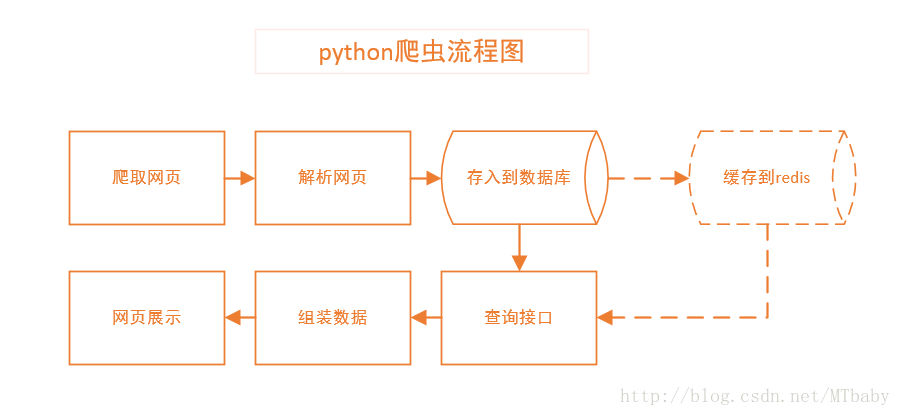
我将代码实现大致分为三部分:
1.电影信息的爬取;
2.数据的存储;(缓存到redis)
3.数据的查询;
效果图展示:
1.通过ID进行查询电影:
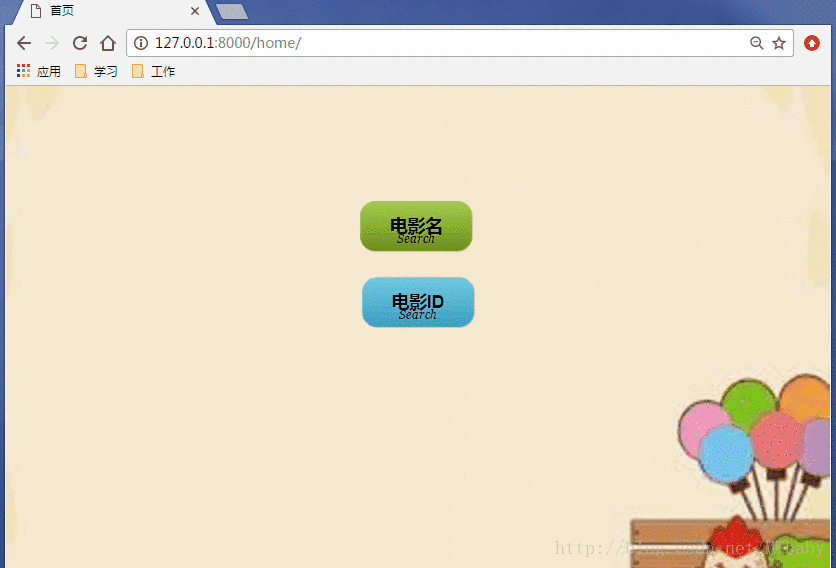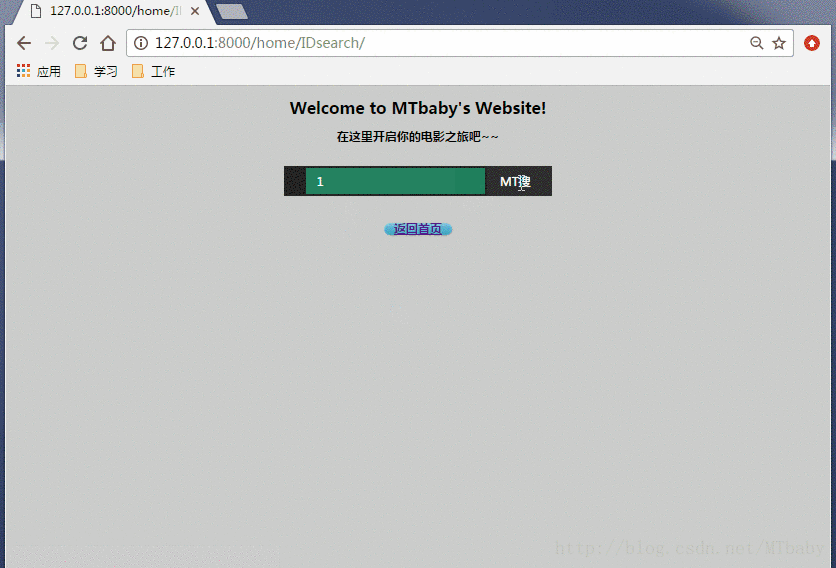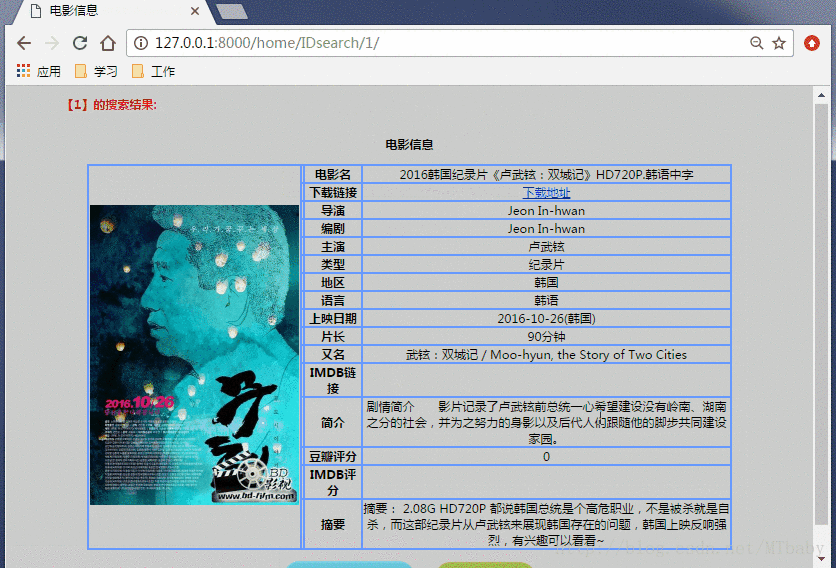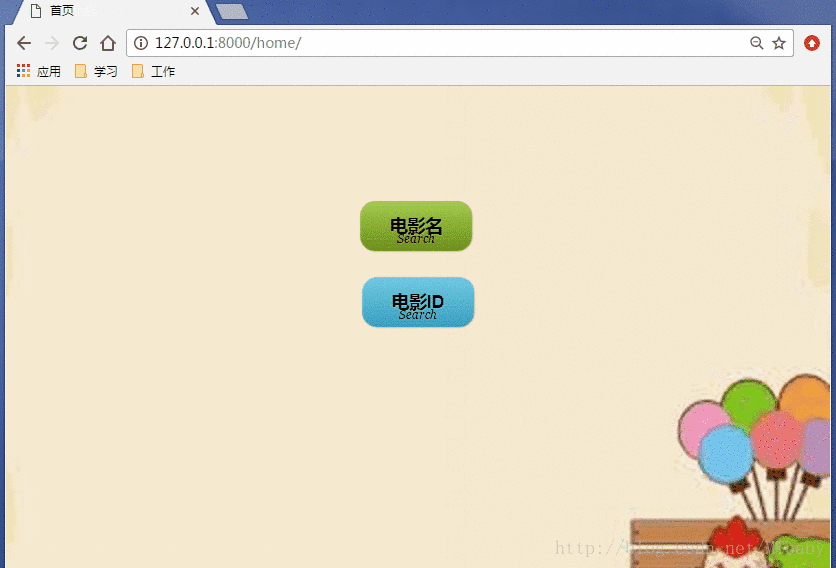
2.通过电影名查询:

这里先写第一部分,也是最重要的一步,就是电影信息的爬取,类似于后台程序。我们打开一个电影链接,发现每个电影有‘电影名’、‘摘要’、‘导演’、‘编剧’……这些信息。所以我们就将这些信息爬取到数据库。
先看一下我的思路:
一、爬取网页
#爬取网页
def getHtml(url):
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers = {"User-Agent":user_agent}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
html = response.read()
return html二、网页解析
#爬取信息并存储数据
def GetBdfilmInfo(cur_url):
# 先定义一个字典存储电影信息
film_info = {}
try:
html_doc = getHtml(cur_url)
sp = bs4.BeautifulSoup(html_doc,'html.parser',from_encoding="utf-8")
# 当前url,这里把当前的url当做下载链接来处理
film_info['url'] = cur_url
# 标题处理
film_info['name'] = ''
title = sp.find('h3')
if title:
film_info['name'] = title.string
# 豆瓣评分
film_info['douban'] = ''
db = sp.find('a',class_='list-douban')
if db:
film_info['douban'] = db.string
# IMDB评分
film_info['IMDB'] = ''
imdb = sp.find('a',class_='list-imdb')
if imdb:
film_info['IMDB'] = imdb.string
# 摘要
film_info["summery"] = ''
abst = sp.find('strong')
if abst:
einfo = ''
for i,e in enumerate(abst.next_elements):
if i>=2:
break
einfo += e
film_info['summery'] = einfo
#下载链接,由于该电影网站对下载链接做了反爬虫机制,所以我们这里暂不处理
# down_div = sp.find("div",id = "bs-docs-download")
#
# film_info['urls'] = []
# down_list = []
# durls = down_div.find_all('a')
# for u in durls:
# down_list.append(str(u))
# continue
# for n in u.children:
# down_list.append(n)
# film_info['urls'] = down_list
# 海报
film_info['postlink'] = ''
poster_url = sp.find('div',id = 'wx_pic')
if poster_url:
for img in poster_url.children:
film_info['postlink'] = img.attrs["src"]
#剧情介绍
film_info['brief'] = ''
jq = sp.find_all("div",style = "margin-bottom: 10px;")
for x in jq:
film_info['brief'] = x.get_text()
# 电影信息
mvinfo = []
information = sp.find_all("div",attrs={'class':"span7",'sytle':"font-size:12px"})
for b in information:
for v in b.children:
t = v.string
if t:
mvinfo.append(''.join(t))
spv = []
cv = ''
for v in mvinfo:
if v.find(':')>=0:
if cv:
spv.append(cv)
cv = v
else:
cv += v
spv.append(cv)
# 由于我们后面创建的数据表字段使用英文,为方便起见,这里用字典名映射转换
# 英文
mvh = ["director", "edit", "star", "type",
"region", "language", "date", "length",
"othername", "IMDblink"]
# 中文
mvhcn = ["导演","编剧","主演","类型","制片国家/地区","语言","上映日期","片长","又名","imdb链接"]
# 列表打包成字典,此时mvd是一个字典
mvd = dict(zip(mvhcn, mvh))
# 先把抓取的数据整理成字典
spvdict = {}
for element in spv:
its = [v.strip() for v in element.split(':')]
if len(its) != 2:
continue
nm = its[0].lower()#统一成小写
if type(nm).__name__=='unicode':
nm = nm.encode('utf-8')
vu = its[1]
spvdict[nm] = vu
#将字典的key与数据库中的字段对应,这里用mvh列表存储
for i,element in enumerate(mvh):
if spvdict.has_key(mvhcn[i]):
film_info[mvh[i]] = spvdict[mvhcn[i]]
else:
film_info[mvh[i]] = ''
except:#处理网页不存在的情况
pass
return film_info
三、数据存储
这里先创建一个数据库,并在该数据库下创建表film,由于我用的是sqlite3,所以不需要做登录认证,只需要连接即可
print '连接数据库……'
cx = sqlite3.connect('PaChong.db')
#在该数据库下创建表
cx.execute ('''CREATE TABLE film(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name str null,
url str null,
director str null,
edit str null,
star str null,
type str null,
region str null,
language str null,
date str null,
length str null,
othername str null,
IMDblink str null,
brief str null,
douban str null,
postlink str null,
IMDB str null,
summery str null
);''')
print "Table created successfully";
print "数据库连接完成"为了方便,我这里写一个数据库执行函数,直接调用
#数据库执行函数
def SqlExec(conn,sql):
cur = None
try:
cur = conn.cursor()
cur.execute(sql)
conn.commit()
except Exception,e:
print 'exec sql error[%s]'%(sql)
print Exception,e
cur = None
return cur这里就是主函数了,我们拼接一下url,抓取900条数据。
#main函数
def main():
for num in xrange(23000,23900):#爬取900条数据
cur_url = 'http://www.bd-film.com/gq/'
num = str(num)
h = ".htm"
cur_url = cur_url + num + h
mvi = {}
#调用解析函数
mvi = GetBdfilmInfo(cur_url)
# 这里加一个判断,判断是否获取网页成功
if not mvi.has_key('director'):
print 'Page get failed:',num
continue
# 格式化数据,防止插入数据库sql有问题
for k,v in mvi.items():
if v:
mvi[k] = v.replace("'","")
else:
mvi[k] = ''
#这里拼接sql语句
filed_sql = []
value_sql = []
for k,v in mvi.items():
filed_sql.append(k)
value_sql.append(v)
sql = 'insert into film(' + ','.join(filed_sql) + ') '
sql += "values('" + "','".join(value_sql) + "');"
#调用数据库函数
if SqlExec(cx, sql):
print "数据插入完毕",num
else:
print sql
if __name__ == '__main__':
main()到这里,
1.抓取网页数据
2.存储到数据库
这里两步就已经实现了。我们来看一下我们的数据库信息,由于截图有限,我这里就截取前面一部分。

完整代码
#coding:utf-8
import bs4
import urllib
from bs4 import BeautifulSoup
import urllib2
import sqlite3
import redis
print '连接数据库……'
cx = sqlite3.connect('PaChong.db')
#在该数据库下创建表
cx.execute ('''CREATE TABLE film(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name str null,
url str null,
director str null,
edit str null,
star str null,
type str null,
region str null,
language str null,
date str null,
length str null,
othername str null,
IMDblink str null,
brief str null,
douban str null,
postlink str null,
IMDB str null,
summery str null
);''')
print "Table created successfully";
print "数据库连接完成"
#main函数
def main():
for num in xrange(12525,22200):
cur_url = 'http://www.bd-film.com/gq/'
num = str(num)
h = ".htm"
cur_url = cur_url + num + h
mvi = {}
#调用解析函数
mvi = GetBdfilmInfo(cur_url)
# 这里加一个判断,判断是否获取网页成功
if not mvi.has_key('director'):
print 'Page get failed:',num
continue
# 格式化数据,防止插入数据库sql有问题
for k,v in mvi.items():
if v:
mvi[k] = v.replace("'","")
else:
mvi[k] = ''
#这里拼接sql语句
filed_sql = []
value_sql = []
for k,v in mvi.items():
filed_sql.append(k)
value_sql.append(v)
sql = 'insert into film(' + ','.join(filed_sql) + ') '
sql += "values('" + "','".join(value_sql) + "');"
#调用数据库函数
if SqlExec(cx, sql):
print "数据插入完毕",num
else:
print sql
#数据库执行函数
def SqlExec(conn,sql):
cur = None
try:
cur = conn.cursor()
cur.execute(sql)
conn.commit()
except Exception,e:
print 'exec sql error[%s]'%(sql)
print Exception,e
cur = None
return cur
#访问网页
def getHtml(url):
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers = {"User-Agent":user_agent}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
html = response.read()
return html
#爬取信息并存储数据
def GetBdfilmInfo(cur_url):
# 先定义一个字典存储电影信息
film_info = {}
try:
html_doc = getHtml(cur_url)
sp = bs4.BeautifulSoup(html_doc,'html.parser',from_encoding="utf-8")
# 当前url,这里把当前的url当做下载链接来处理
film_info['url'] = cur_url
# 标题处理
film_info['name'] = ''
title = sp.find('h3')
if title:
film_info['name'] = title.string
# 豆瓣评分
film_info['douban'] = ''
db = sp.find('a',class_='list-douban')
if db:
film_info['douban'] = db.string
# IMDB评分
film_info['IMDB'] = ''
imdb = sp.find('a',class_='list-imdb')
if imdb:
film_info['IMDB'] = imdb.string
# 摘要
film_info["summery"] = ''
abst = sp.find('strong')
if abst:
einfo = ''
for i,e in enumerate(abst.next_elements):
if i>=2:
break
einfo += e
film_info['summery'] = einfo
#下载链接,由于该电影网站对下载链接做了反爬虫机制,所以我们这里暂不处理
# down_div = sp.find("div",id = "bs-docs-download")
#
# film_info['urls'] = []
# down_list = []
# durls = down_div.find_all('a')
# for u in durls:
# down_list.append(str(u))
# continue
# for n in u.children:
# down_list.append(n)
# film_info['urls'] = down_list
# 海报
film_info['postlink'] = ''
poster_url = sp.find('div',id = 'wx_pic')
if poster_url:
for img in poster_url.children:
film_info['postlink'] = img.attrs["src"]
#剧情介绍
film_info['brief'] = ''
jq = sp.find_all("div",style = "margin-bottom: 10px;")
for x in jq:
film_info['brief'] = x.get_text()
# 电影信息
mvinfo = []
information = sp.find_all("div",attrs={'class':"span7",'sytle':"font-size:12px"})
for b in information:
for v in b.children:
t = v.string
if t:
mvinfo.append(''.join(t))
spv = []
cv = ''
for v in mvinfo:
if v.find(':')>=0:
if cv:
spv.append(cv)
cv = v
else:
cv += v
spv.append(cv)
# 字典名映射转换
# 英文
mvh = ["director", "edit", "star", "type",
"region", "language", "date", "length",
"othername", "IMDblink"]
# 中文
mvhcn = ["导演","编剧","主演","类型","制片国家/地区","语言","上映日期","片长","又名","imdb链接"]
# 列表打包成字典,此时mvd是一个字典
mvd = dict(zip(mvhcn, mvh))
# 先把抓取的数据整理成字典
spvdict = {}
for element in spv:
its = [v.strip() for v in element.split(':')]
if len(its) != 2:
continue
nm = its[0].lower()#统一成小写
if type(nm).__name__=='unicode':
nm = nm.encode('utf-8')
vu = its[1]
spvdict[nm] = vu
#将字典的key与数据库中的字段对应,这里用mvh列表存储
for i,element in enumerate(mvh):
if spvdict.has_key(mvhcn[i]):
film_info[mvh[i]] = spvdict[mvhcn[i]]
else:
film_info[mvh[i]] = ''
except:#处理网页不存在的情况
pass
return film_info
if __name__ == '__main__':
main()
ok,数据已经到我们的本地了。为了查询快速,我这里讲数据缓存到redis中,这一步可以不要,我后面也是直接查询数据库的,只是以防数据多,缓存到redis,那查询就会快速很多。
四、数据缓存到redis
#coding:utf-8
import redis
import sqlite3
from film_spider import SqlExec #将前面文件里的SqlExec函数导入
#思路
#1.mid先去redis查
#2.如果没有,取数据库数据
#3.写redis
#4.返回查询数据
def RedisMviQuery(mid):
#定义空字典来存储查询结果
mvi_dict = {}
key_name = 'film_info_'+str(mid)
# **1.mid去redis查**
r = redis.Redis(host = 'localhost', port = 6379, db = 0)
if r.exists(key_name):
return r.hgetall(key_name)
else:
print "没有查询到,将连接数据库查询,并返回查询结果"
# **2.取数据库数据**
#连接数据库
cx = sqlite3.connect('PaChong.db')
#sql查询,将查询结果返回到query_result列表
sql2 = "select * from film where id=%d"%(mid)
#调用数据库执行函数
cu = SqlExec(cx,sql2)
query_result = []
if cu:
row = cu.fetchone()
query_result = row
if not query_result:
print "无查询结果"
return mvi_dict
mvi_key = ["ID","name","director","url", "edit", "star", "type",
"region", "language", "date", "length",
"othername", "IMDblink","brief","douban","postlink","IMDB","summery"]
for i,m in enumerate(mvi_key):
mvi_dict[m] = query_result[i]
# **3.把查询到的结果储存到redis**
for k,v in mvi_dict.items():
r.hset(key_name,k,v)
# **4.返回**
return mvi_dict
if __name__ == "__main__":
mvi = RedisMviQuery(3)
for k,v in mvi.items():
print k,':',v
ok ,这样,后台数据就处理好了,下篇将会讲述使用django将我爬取的数据展示在前端。