点云目标检测-综述2019.04
说明:美团无人配送团队主笔,摘录自智车科技公众号
激光雷达成像原理
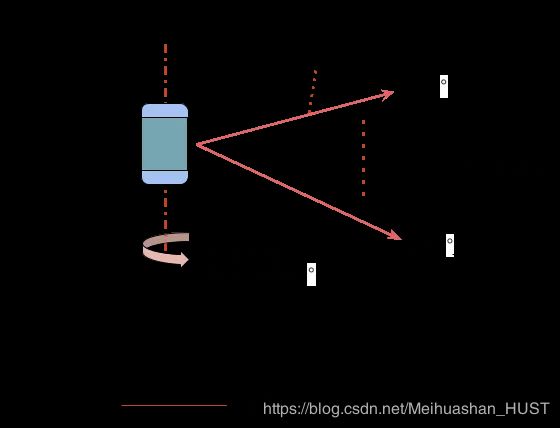
通常采集到的360°的数据被称为一帧,上面的例子中一帧数据在理论上最多包含32*(360/0.2)=57600个点,在实际情况中如果雷达被放置在车的上方大约距地面1.9米的位置,则在比较空旷的场景中大约获得40000个点,一部分激光点因为被发射向天空或被吸收等并没有返回到接收器,也就无法得到对应的点。下图是典型的一帧数据的可视化图。

点云数据成像特点
距离中心点越远的地方越稀疏;
机械激光雷达的帧率比较低,一般可选5hz、10hz和20hz,但是因为高帧率对应低角分辨率,所以在权衡了采样频率和角分辨率之后常用10hz;
点与点之间根据成像原理有内在联系,比如平坦地面上的一圈点是由同一个发射器旋转一周生成的;
激光雷达生成的数据中只保证点云与激光原点之间没有障碍物以及每个点云的位置有障碍物,除此之外的区域不确定是否存在障碍物;
由于自然中激光比较少见所以激光雷达生成的数据一般不会出现噪声点,但是其他激光雷达可能会对其造成影响,另外落叶、雨雪、沙尘、雾霾也会产生噪声点;
与激光雷达有相对运动的物体的点云会出现偏移,例如采集一圈激光点云的耗时为100ms,在这一段时间如果物体相对激光有运动,则采集到的物体上的点会被压缩或拉伸。
点云目标检测
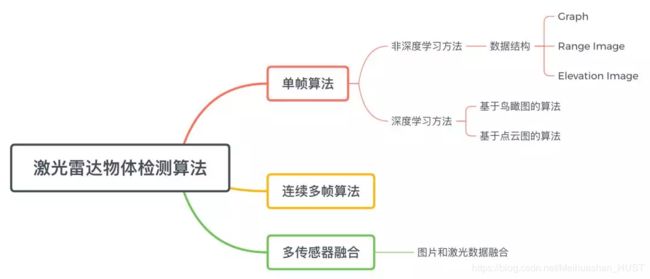
为了提高算法的速度,很多算法并不直接作用于三维点云数据,而是先将点云数据映射到二维平面中然后再处理。常见的二维数据形式的有Range Image和Elevation Image。
现在自动驾驶中一般关注鸟瞰图中物体检测的效果,主要原因是直接在三维中做物体检测的精确度不够高,而且目前来说路径规划和车辆控制一般也只考虑在二维平面中车体的运动。
现在在鸟瞰图中的目标检测方法以图片目标检测的方法为主,主要在鸟瞰图结构的建立、物体的空间位置的估计以及物体在二维平面内的旋转角度的估计方面有所不同。
从检测结果来看这类算法比在三维空间中的物体检测要好。直接作用在三维空间中的物体检测方法在近年来也有所突破,其通过某种算子提取三维点云中具有点云顺序不变性的特征,然后通过特殊设计的网络结构在三维点云上直接做分类或分割。这类方法的优点是能对整个三维空间任何方向任何位置的物体进行无差别的检测,其思路新颖但是受限于算法本身的能力、硬件设备的能力以及实际应用的场景,现在还不能在实际中广泛地使用。
虽然在学术界的排行榜中现在最好的方法是基于深度学习的算法,但是在实际问题中数据的预处理、后处理等对最终结果有着至关重要的影响,而这些部分的算法往往需要根据数据和使用场景有针对性的设计。
无论是基于Graph或是基于Range Image的结构都比单纯的点云蕴涵了更多的信息。在这些结构中有时使用简单的基于规则的方法就可以得到比较好的结果,这一点在实际应用中非常重要。例如在物体检测任务中出现了训练集合中未出现过的物体,基于学习的方法一般无法正确地将其检测出来。但是基于简单规则的方法却可以正常给出检测结果,虽然此时分类结果往往是未知。在自动驾驶中检测算法的漏检问题远比错分类问题严重很多,从这个角度说基于简单规则的方法是保证安全的一把锁。从实时数据预处理的效率来说,在实际环境中为了提高检测精度需要将离散的噪声点和不在检测范围内的物体过滤掉。在Graph和Range Image中进行噪声数据的过滤有时比直接在点云上做效率高。
1.基于Graph的方法
基于Graph的建模方法指直接根据三维点云直接建立无向图G = {N, E},N表示图中的节点E表示节点之间的边。常用的建图方式是将三维点云中每个点的坐标(x,y,z)作为一个节点。找到每个节点对应的雷达的线数l和水平方向的旋转角度θ,当两个节点i和j满足下面任何一个条件时为这两个节点建立一条边。即如果两个点由相邻线在同一时刻产生,或由同一根线在相邻时刻产生,则为两个点建立一条边。数学描述如下:
|l_i - l_j| = 1 and θ_i = θ_j
l_i = l_j and (θ_i - θ_j) mod 360 = r
这里r表示水平方向的最小旋转角,上节例子中r=0.2。实际在建图时会增加其他约束,比如两个节点的距离不能太远或两个节点的高度差不能太大等。建图的目的是在空间中离散的三维点之间建立某种联系,从而为后续的聚类和分割做准备。一般这种建图的方法不设定边的权重,依靠节点的特征进行聚类和分割。
Moosmann提出了一种使用法向量作为节点特征的方法【1】。其思路是将点云看成连续曲面上的离散采样。所谓法向量是指曲面在每个节点处的法向量,如果两个相邻的节点的法向量相似则说明这两个节点所在局部平面比较光滑,那么这两个节点应当属于一个同一个物体。论文中使用一种简单快速的方法对于每个节点位置的法向量进行估计,即首先计算所有相邻平面的法向量(如下图蓝色箭头),然后求法向量的几何平均值并进行归一化(下图红色箭头),最后所有节点的法向量再根据所有相邻节点进行均值滤波。
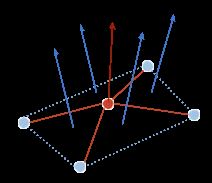
得到特征之后就可以根据相邻节点之间的特征相似性进行聚类,聚类的首要目的一般是求出属于地面的节点即地面分割。
Douillard为不同的数据类型提出了不同的地面分割方法【2】。其基于Graph结构的地面分割算法的核心思想是:首先确定属于地面的种子节点然后由内向外进行区域增长。
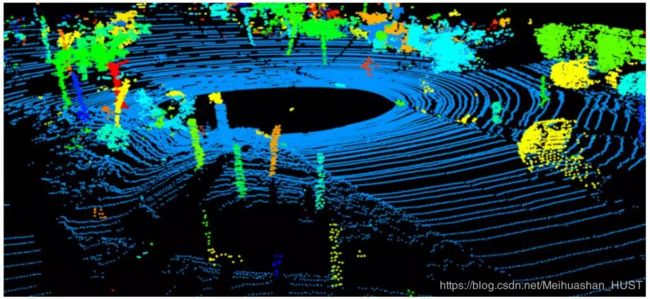
论文中提出的算法为了在处理各种边缘情况的同时尽可能的增加地面节点的召回率,手工设定了一系列复杂的约束条件。这样做确实在实验指标上看起来好一些,但是在实际的应用中关注更多的并不是地面节点的召回,而是地面节点在所有可行驶区域内的分布是否均匀。一般来说根据这个目标在实际场景中只用很简单的决策树,就可以建立出满足应用要求的约束模型。Douillard在得到地面之后通过聚类算法找到其他类别的物体如下图
上面介绍的建图的方法只能作用在低速单帧的数据中。因为在高速情况由于多普勒效应很难准确为每一个三维点找到其对应的雷达线数和水平旋转角度,多帧的情况也类似。而更通用的建模方法是为每个节点寻找最邻近的k的节点建立边。这种方法虽然可以建立八叉树等数据结构进行加速,但是没有在Range Image中建图的效率高。
2.基于Range Image的方法
Range Image是指距离图,即一种类似图片的数据结构。以上节32线激光雷达的数据为例子,对应的Range Image宽360/0.2=1800像素,高32像素。每个像素值表示对应点到原点的距离。上节中的点云对应的Range Image的的可视化如下图,因为这个图非常细长所以只截取了一小段。黑色的部分缺少对应的点云信息,其他的不同颜色代表不同距离。
Zhu提出了一种在Range Image中建立无向图G = {N, E}的方法【3】。即在图中每一个像素代表一个节点,以每一个节点为中心在二维平面上以一定距离搜索其他节点,如果两个节点在三维空间中满足某些条件则建立一条边,边的权重是两个点在三维空间中的距离。建图之后使用基于图的分割算法(例如【4】)即可得到聚类结果。
这种方法建图的速度非常快,在实际使用过程中还需要处理多个点映射到同一个像素的情况,其建图的结果和直接在三维点云中建图相比非常接近。Range Image不仅仅能为计算进行提速,还可以做到一些不方便在点云上直接处理的事情,因为其比点云包含了更多的信息。
Biasutti提出了一种对点云中被遮挡的部分进行还原的方法【5】。其思路是:首先将点云生成Range Image结构并在其中进行聚类,然后选择某个物体所代表的类并在图中抹掉,之后根据周围像素将抹掉的部分复原出来,最后将Range Image映射回点云。下图是论文中的算法的结果,可以看出白色的行人被抹掉了,而地面上的空洞被漂亮的填充了。

基于深度学习的方法
研究者发现虽然点云数据与图片数据有很多不一样的特点,但是在鸟瞰图中这两种不同的数据在目标检测的框架下具有相通之处,因此基于鸟瞰图的激光点云的目标检测算法几乎都沿用了图片目标检测算法的思路。
2016年PointNet【8】提出了另外的一种算法框架,其提出了一种在三维空间中与点云顺序无关的算子并结合CNN也在目标分割和识别上得到了很好的效果。这个方法为三维点云中的目标检测提供了新的思路,即有可能存在一种比基于鸟瞰图算法通用的三维目标检测方法。
如前文所述激光点云数据有一些无法克服的问题,其中最主要的就是稀疏性。提高雷达的线数是一个解决问题的途径,但是现有高线数雷达的成本过高很难真正落地,并且高线数也无法从根本上解决远距离的稀疏问题。
为了解决这个问题一些研究者提出了激光数据和图片数据相融合的方法,这种方法尤其对小物体和远处的物体有很好的效果。
激光点云中目标检测的结果的稳定性也十分重要,传统的检测算法并不特别关注这个问题,其中一个原因是在后续的跟踪和关联算法中可以对检测到的目标的大小、尺寸进行滤波,从而得到稳定的结果。近几年一些研究者尝试将“稳定算法输出”的任务交给深度神经网络,尝试根据连续的多帧数据对当前帧进行检测,这种方法可以增加算法输出结果的稳定性,减少后续跟踪算法的复杂程度,提高整个系统的鲁棒性。
单帧激光检测
Zhou提出的VoxelNet是一个在激光点云数据中利用图片深度学习检测框架的很好的例子【13】。其先将三维点云转化成voxel结构,然后以鸟瞰图的方式来处理这个结构。这里voxel结构是用相同尺寸的立方体划分三维空间,这里每个立方体被称为voxel即体素。举一个空间划分的例子,如果点云中的点在三维空间满足
(x,y,z) ∈ [-100,100] x [-100,100] x [-1,3]
当设定voxel的尺寸为(1,1,1)时可以将空间划分为2002004 = 160000个voxel。很多论文中称这种结构的维度为2.5维,如果把每个格子都看成一个像素那么这是一种类似二维图片的数据结构,而每个voxel的内部是三维空间结构。
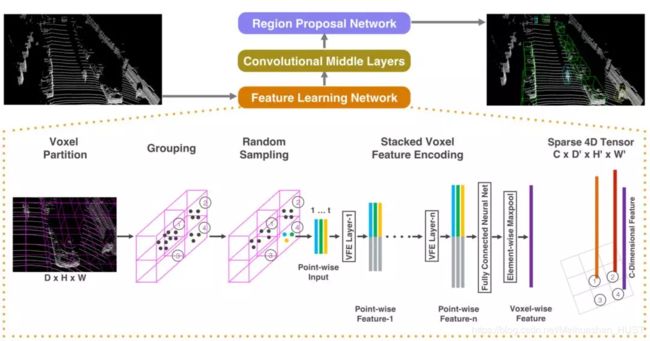
VoxelNet有两个主要的过程,第一个被称为VFE(Voxel Feature Extraction)是voxel的特征提取过程,第二个是类似YOLO的目标检测过程。在VEF过程中所有voxel共享同一组参数,这组参数描述了生成voxel的特征的方法。论文中VFE的过程由一系列CNN层组成如下图。
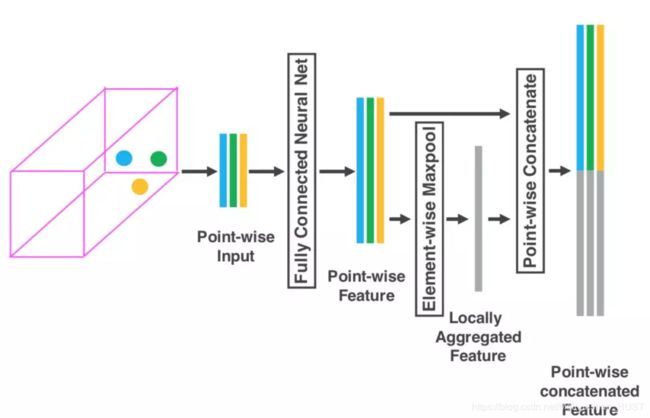
VFE过程的结果是每个voxel都得到了长度相同的特征,将这些特征按照voxel的空间排列方式堆叠在一起形成了一个4维的特征图,以上面的例子来说特征图的尺寸为(200,200,4, l),这里l是voxel的特征长度。
在目标检测过程中其首先将voxel特征通过三维卷积压缩成3维的形式(200,200,l’),然后对得到的特征图进行目标检测。和二维图片检测相比VoxelNet不仅要给出物体中心的二维坐标和包围盒的长宽,还需要给出物体中心在Z轴的位置、物体的高度和物体在XY平面上的朝向。
VoxelNet在实际使用中有两个问题:首先在VFE过程中因为所有的voxel都共享同样的参数和同样的层,当voxel数量很大时在计算上会引入错误或效率问题,一些神经网络的框架例如Caffe在bn和scale层的实现时没有考虑到这点,需要使用者自己去做调整;其次三维卷积操作的复杂度太高使得这个算法很难在自动驾驶车辆上实际使用的硬件设备上满足实时性要求。
Yang提出的PixorNet算法可以在一定程度上解决上述问题【14】,首先其没有VFE的过程,而是用手工设计的0-1的布尔变量和像素的反射强度表示每一个voxel,即每个voxel由两个数值表示。其次PixorNet从4维到2维做的简单的线性映射,即按照某种固定顺序将(200,200,4, l)整理成(200,200,4*l)的结构。与VoxelNet相比PixorNet可以节约非常多的计算量,从而达到实时性的要求,但是因为其手工设计的特征过于简单检测效果不是特别好。
上述方法主要在鸟瞰图上进行目标检测,Qi提出了PointNet和PointNet++可以在三维空间中直接做分割和识别任务【8,9】。
PointNet首先为点云中每一个点计算特征(下图中1024维),然后通过一个点云顺序无关的操作(下图max pool)将这些特征组合起来得到属于全体点云的特征,这个特征可以直接用于识别任务。而将全局特征与每个点的特征组合到一起形成的新特征可以用于点云分割任务中。
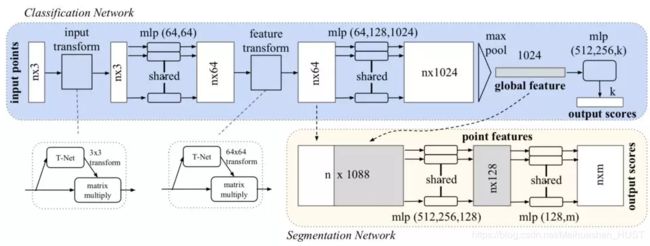
PointNet在计算点的特征时共享一组参数,这一点和VoxelNet很类似因此也有与之相同的问题。另外PointNet主要提取了所有点云组成的集合的全局特征,而没有提取描述点与点之间关系的特征。将PointNet的方法类比到二维图片中,可以看出其与传统卷积神经网络的区别,即PointNet中没有类似卷积的操作。
PointNet++主要解决的就是这个问题,其尝试通过使用聚类的方法建立点与点之间的拓扑结构,并在不同粒度的聚类中心进行特征的学习。
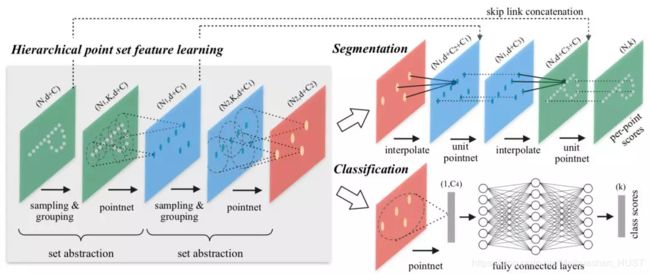
这种方法确实比PointNet在分割算法中有所提高,但是将其直接用于检测算法却不能得到较好的结果。主要原因是在PointNet的结构中很难设计anchor。现在图片中的检测算法一般需要先在稠密的二维空间中提取anchor,然后再对anchor不断过滤、回归和分类。但是在PointNet++中处理的是稀疏的点云,在点云中很难确根据一个点确定物体的中心位置。
基于图像与点云融合
从融合的时间点来看,多特征融合方法大致可以分为两类:前融合和后融合。前融合首先将不同来源的数据的特征进行融合,然后对融合后的特征进行处理得到检测的结果。后融合中不同特征分别经过独立的过程得到检测结果,然后再将这些结果融合到一起。
两种方法各有优劣,前融合能够更好的挖掘不同特征之间的联系从而得到更好的检测结果,而后融合从宏观来看具有更强的系统稳定性,当部分感知设备出现故障时只要还有一个设备在工作,那么就不会让整个感知系统崩溃。
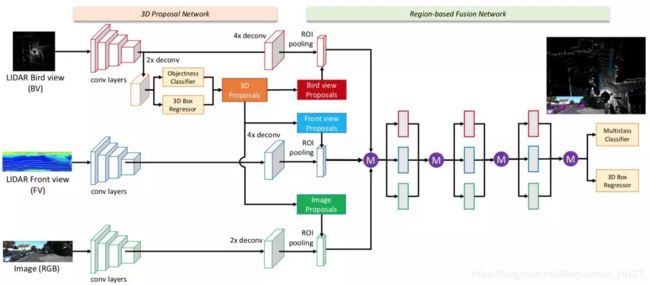
近几年出现了很多图片和激光雷达数据融合的方法。Chen提出了MV3D的方法,其首先在不同数据上提取特征图,然后在点云的鸟瞰图中做三维物体检测,之后将检测的结果分别映射到鸟瞰图、Range Image和图片中,通过roi-pooling分别在三种特征图中进行特征提取,最后将提取到的特征融合在一起再做后续的处理【16】。这个方法中检测过程只在鸟瞰图中进行,融合了鸟瞰图、Range Image和图片这三类数据源的特征。
Qi提出的FPointNet方法也使用了类似的思路,首先在图片上做物体检测,然后找到对应的物体的点云【18】。得到每个物体的点云之后,采用了类似PointNet的思路对物体的点云进行特征提取。
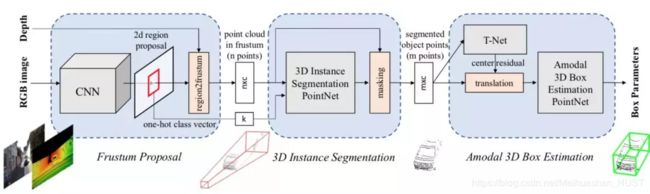
这两个方法具有一定的共通之处:都具有似于FasterRCNN的两段式(two-stage)检测方法的串行过程,即先在某一种数据的特征图上进行物体的检测(这个过程也称为proposal),然后根据检测到的结果再在其他的数据中提取特征。这类方法的问题在于第一步proposal的过程并没有引入其他的特征。上面讨论过对于自动驾驶的检测任务来说,召回率是非常重要的指标,而这类算法的召回率的上限直接与某一种数据类型绑定,并没有很好地达到自动驾驶目标检测中特征融合的目的。
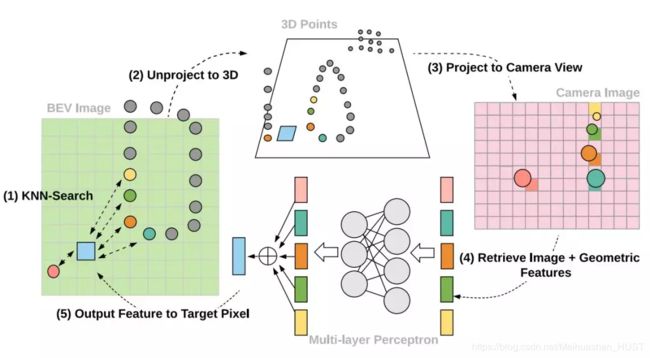
Liang提出了一种将图片特征融合到鸟瞰图中的方法【19】。其核心思路是:对于鸟瞰图中每个位置首先在三维空间中寻找临近的点,然后把将这些点根据激光雷达和摄像机标定信息投影到图片特征图上,最后将对应的图片特征和点的三维信息融合到鸟瞰图对应的位置中。融合后的结果是得到了一个具有更多信息量的鸟瞰图的特征图。
这个特征图中除了包含自带的点云信息还包含了相关的图片信息。后续的分割和检测任务都基于这个特征图。这个方法中虽然还是在鸟瞰图中对物体进行检测,但是由于此时特征图中还包含了图像信息,因此从理论上来说可以得到更高的召回率。
多帧点云检测
为了得到较稳定的检测结果,可以在后处理中增加约束、也可以在跟踪算法中进行滤波。这些方法可以看作通过手工设计一些操作以减少各项检测结果的方差,从现有的理论上来看,通过学习类算法自动设计相关操作应该有更好的效果。Luo利用深度神经网络在鸟瞰图中通过连续帧的数据进行目标检测【20】。
其建立了一个“多入多出”的结构,即算法的输入是过去连续帧的鸟瞰图,而算法的输出是当前时刻和未来连续时刻的物体位置。Luo希望通过这种结构让网络不仅仅学习到物体在鸟瞰图中的形状,还可以学习到物体的速度、加速度信息。其步骤如下:
设当前帧为i并设定时间窗口k,选取第i-k+1帧到第i帧的点云,并将这些点云根据GPS/IMU的信息映射到第i帧的坐标系下;
分别提取这k帧点云的特征;
融合这些特征;
输出第i帧和未来若干帧物体的信息,并建立轨迹。
这个方法可以在减少物体检测的噪声、增加召回率同时增加检测结果的稳定性。例如当道路上某辆车突然被其他其他的车辆遮挡,由于前面若干帧中是存在这个车的点云的,所以此时是可以通过网络猜测到其当前真实的位置。
当被遮挡的车辆逐渐脱离遮挡区域时,虽然历史时刻中没有其对应的点云信息,但是当前时刻存在其点云,所以同样也可以检测到其位置。
这篇文章从一定程度上证明了这样做的可行性,但是还有一些方面值得继续挖掘:更好的特征融合的方式、每次不重复提取帧的特征以及更好的处理轨迹的方法等。
在实际中设计相关算法时一般不是完整地应用其中某一个方法,而是首先采用某个方法的工作流程作为主体框架,然后根据在实际情况中遇到的问题再不断地对其进行修改。
从长远来看,激光雷达未必是自动驾驶系统中必须的设备,因为多角度摄像头的图片结果理论上可以做到周围空间的三维感知。但是就现阶段来说,激光雷达还是一种非常可靠的感知手段。
随着工艺的进步,激光雷达的线数和可视范围会逐渐增加。对于目标检测算法来说,高线数激光雷达的数据一定比低线数雷达的要好,但是高线数也对算法的速度有着更高的要求,所以相关算法的效率的提高可能会是一个研究的方向。
由于激光雷达的本身的特性,小物体、远处物体和被遮挡物体的点云相对稀疏,提高这种情况下算法的效果可能会是相关研究的另一个方向。实际应用中激光雷达目标检测可能面临的问题更多,包括但不仅限于高效的数据标注、处理不平坦的地面、不同天气的影响、不同物体材质的区分、算法效果与复杂度的权衡、算法效果的评估等等。
希望这些问题可以随着技术的发展逐步得到解决,未来可以真正实现安全便捷的自动驾驶。