tensorflow(十一)--利用seq2seq的Decoder-Encoder机制实现序列生成模型(上)
前言:
由于本社群打算组队参加京东的多轮对话系统挑战赛,比赛内容主要是做一款功能强大的聊天机器人,由于之前一直都是在做视觉,而seq2seq又是聊天机器人不可或缺的,因此打算学一下nlp的东西。(PS:大佬们如果对比赛感兴趣的,可以联系群主。)
一、初识
seq2seq 即“Sequence to Sequence”,是一个 Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
这个结构最重要的地方在于输入序列和输出序列的长度是可变的,可以用于翻译,聊天机器人,句法分析,文本摘要等。
seq2seq最早由两篇文章独立地阐述了它主要思想,分别是
《Sequence to Sequence Learning with Neural Networks》
地址:https://arxiv.org/pdf/1409.3215.pdf
和《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》
地址:https://arxiv.org/pdf/1406.1078.pdf
二、深入
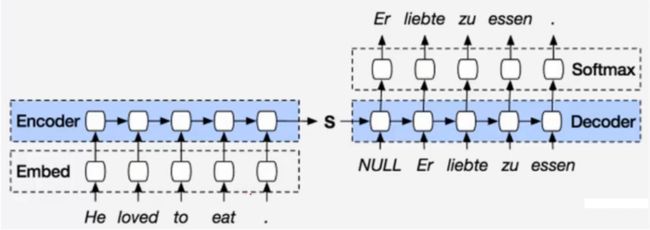
Encoder-Decoder的基本结构如图所示:

模型读取一个输入句“ABC”,并生成“WXYZ”作为输出语句。该模型在输出句尾标记后停止进行预测。注意,LSTM读取输入相反,因为这样做在数据中引入了许多短期依赖项,使得优化问题更加容易。
LSTM 的目的是估计条件概率 p(y1, … , yT′ |x1, … , xT ) ,
它先通过最后一个隐藏层获得输入序列 (x1, … , xT ) 的固定长度的向量表达 v,
然后用 LSTM-LM 公式计算输出序列 y1, … , yT′ 的概率,
在公式中,初始状态就是 v,公式如下:
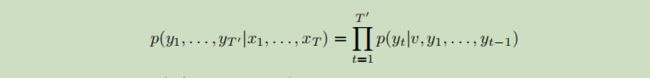
在这个方程中,每个p(yt|v,y1,…,yt−1)分布都表示为词汇表中所有单词的softmax。请注意,我们需要在每个句子的结尾都有一个特殊的句尾符号“”,这使得模型能够在所有可能长度的序列上定义一个分布。总体方案如上图所示。其中所示的LSTM计算“A”、“B”、“C”、“”的表示,然后使用这种表示计算“W”、“X”、“Y”、“Z”、“”的概率。
(1) Encoder阶段:
Encoder过程很简单,直接使用RNN(一般用LSTM)进行语义向量生成:
ht=f(xt,ht−1)
c=ϕ(h1,…,hT)
其中f是非线性激活函数, ht−1
是上一隐节点输出, xt
是当前时刻的输入。向量c通常为RNN中的最后一个隐节点(h, Hidden state),或者是多个隐节点的加权和。
(2) Decoder阶段
该模型的decoder过程是使用另一个RNN通过当前隐状态 ht
来预测当前的输出符号 yt ,这里的 ht 和 yt
都与其前一个隐状态和输出有关:
ht=f(ht−1,yt−1,c)
P(yt|yt−1,…,y1,c)=g(ht,yt−1,c)
三、了解注意力机制
在seq2seq网络中存在的问题:即压缩损失了大量的信息
如下图:由于rnn的特性,网络最后的节点几乎包含了前面节点的全部信息。因此解码部分的很大一部分信息是来源于eat后面的单元,因此损失了前面节点的大量信息。
通俗的来说,注意力机制很像图像领域中的ROI区域,即部分的内容主要由部分来决定。如下图:这里的knowledge很大程度上是又知识得到的,那么我们在设置权重的时候,便可以将知识的权重设置的高一些,而其他的权重设置的低一些。这便是attention机制。

四、seq2seq应用领域
1、机器翻译
机器翻译(Neural Machine Translation)是 NLP 中最经典的任务,也是最活跃的研究领域之一,Seq2Seq 提出之后,最早应用于 nmt 任务。当前,主流的在线翻译系统都是基于深度学习模型来构建的,包括 Google、百度等,整体效果取得了非常显著的进步(当然,在刚刚推出的时候还是有很多槽点的)。每年都有特别多的paper在 Seq2Seq 模型上提出一些改进方案。
2、文本摘要
文本摘要也是一个非常经典的 NLP 任务,应用场景非常广泛。我们通常将文本摘要方法分为两类,extractive 抽取式摘要和 abstractive 生成式摘要。前者是从一篇文档或者多篇文档中通过排序找出最有信息量的句子,组合成摘要;后者类似人类编辑一样,通过理解全文的内容,然后用简练的话将全文概括出来。
基于 Seq2Seq+attention 模型在 nmt 任务中的成功,2016 年有很多的工作都是套用 Seq2Seq+attention 来做 abstractive 摘要任务,取得了一定的突破。
3、对话生成
Seq2Seq 模型提出之后,就有很多的工作将其应用在 Chatbot 任务上,希望可以通过海量的数据来训练模型,做出一个智能体,可以回答任何开放性的问题;而另外一拨人,研究如何将 Seq2Seq 模型配合当前的知识库来做面向具体任务的 Chatbot,在一个非常垂直的领域(比如:购买电影票等)也取得了一定的进展。
4、其他
此外还有很多其他的应用,如诗词生成,风格转换,代码补全等,应用范围十分广泛。
(具体用seq2seq实现序列转化的代码请见下一篇文章)