FCN语义分割训练数据(以siftflow和voc2012数据集为例)
截至目前,现已经跑通了siftflow-fcn32s,voc-fcn32s,并制作好了自己的数据集,现在就等大批数据的到来,进而针对数据进行参数fine-tuning,现对我训练的训练流程和训练过程中遇到的问题,做出总结和记录,从而对以后的学习作铺垫。
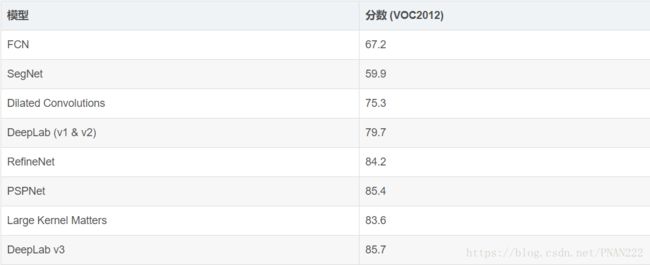
通过这篇分析语义分割的文章可以知道,FCN作为2014年的网络,现在看来确实有些老旧了,从下表可以看出FCN的表现得分也不是最高的,但是不管黑猫白猫,能捉住老鼠的就是好猫,能应用到项目中的,解决问题就是ok的。
chapter 1 基础环境安装和搭建
首先,必要的环境是ubuntu操作系统,FCN使用的框架是caffe,所以还要完成caffe的搭建。在搭建cffe环境的时候,建议直接使用干净的系统进行配置,因为常用的深度学习框架除了caffe还有就是tensorflow,而两者之间是不兼容的,当然可以借助于Anaconda环境进行共存,但是由于FCN是对caffe的直接调用且应用的是python2,所以还是建议前期不要借助于anaconda进行安装,从装显卡驱动,装CUDA8.0,装cudnn6.0,再到opencv3.1,最后编译caffe,安装caffe,一气呵成!
参考资料:https://blog.csdn.net/pnan222/article/details/81003725
后期亲测,虽然都说安装了caffe之后再安装tensorflow会出现软链接错误的问题,如果不使用anaconda的话,只能舍去其中一个来成全另一个,但是通过anaconda,借助于conda进行安装,在虚拟的环境下,应用conda install重新安装新的cuda和cudnn(尽量不要优先选择pip,因为pip安装不会重装cuda和cudnn,还是会出现软链接错误),这样就不会出现两个框架公用一个cuda和cudnn的错误,则不会出现软链接错误。
chapter 2 应用训练好的module实现语义分割
1.在GitHub上下载作者开源的FCN代码,链接如下:https://github.com/shelhamer/fcn.berkeleyvision.org ;
相关文献的链接如下:
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
FCN在多个数据集上都进行了训练,比如:Pascal VOC模型,nyudv2模型,siftflow模型,Pascal-Context模型。
2.下载源码之后解压,首先就是要先应用用作者已经训练好的模型,对满足要求的数据进行预测,看一下效果。通过阅读源码和文章可以知道,训练FCN的过程是:要先根据Vgg16的model,训练FCN32s,再应用得到的FCN32s的model,训练FCN16s,再应用得到的FCN16s的model,训练FCN8s,得到最后的model,应用该model对网络正向传播,可以得到较好的表现结果。
下载voc-fcn32s,voc-fcn16s和voc-fcn8s的caffemodel,并应用于网络正向传播进行预测,作者已经训练好的model可以在每个数据集中进行下载,下载方式为进入对应目录下,找到一个名为caffemodel-url的文件,该文件保存的就是对应model的下载链接,通过链接即可以下载到model,并将model放在对应的目录下,由于fcn8s是最终表现效果最好的model,所以应用的也是该model。
接下来就是修改fcn.berkeleyvision.org目录下的infer.py文件了,以下是我的文件,仅供参考。
import sys
sys.path.append('/home/pzn/caffe/python')
import numpy as np
from PIL import Image
import caffe
import vis
# the demo image is "2007_000129" from PASCAL VOC
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('demo/image.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
# visualize segmentation in PASCAL VOC colors
voc_palette = vis.make_palette(21)
out_im = Image.fromarray(vis.color_seg(out, voc_palette))
out_im.save('demo/output.png')
masked_im = Image.fromarray(vis.vis_seg(im, out, voc_palette))
masked_im.save('demo/visualization.jpg')其中,加入
import sys
sys.path.append('/home/pzn/caffe/python')的目的是为了可以应用sudo的方式调用已经配置好的caffe框架。
最终,设置好自己的图片路径、deploy.prototxt和model路径后,在terminal中键入:
sudo python infer.py即可以进行网络正向传播,得到分割后的结果。
原图:

分割后图像:

可视化后的图像:

完成!
chapter 3 应用FCN在siftflow和voc2012数据集上训练权重
由于数据集不需要自己准备,可以方便的用别人的数据集先把网络给跑通,并熟悉网络的结构、参数和用法。
Part 1 在siftflow数据集上进行训练同时解决loss不收敛问题
由于训练最开始时需要VGG-16的预训练模型,可以去该地址的如下图所示的地方
下载所需要的训练模型,并将其重命名为vgg16-fcn.caffemodel,并将其放在fcn.berkeleyvision.org/ilsvrc-nets/的目录下,以供训练时使用。
1.siftflow数据集,下载地址,共包含33类,类别入下所示:
Semantic and geometric segmentation classes for scenes.
Semantic: 0 is void and 1–33 are classes.
01 awning 雨篷
02 balcony 阳台
03 bird
04 boat
05 bridge
06 building
07 bus
08 car
09 cow 母牛;奶牛
10 crosswalk 人行横道
11 desert 沙漠
12 door
13 fence
14 field 牧场
15 grass 草坪
16 moon
17 mountain
18 person
19 plant
20 pole 杆
21 river
22 road
23 rock
24 sand
25 sea
26 sidewalk 人行道
27 sign 指示牌
28 sky
29 staircase 楼梯
30 streetlight
31 sun
32 tree
33 window
Geometric: -1 is void and 1–3 are classes.
01 sky
02 horizontal
03 vertical
N.B. Three classes (cow, desert, and moon) are absent from the test set, so
they are excluded from evaluation. The highway_bost181 and street_urb506 images
are missing annotations so these are likewise excluded from evaluation.下载好数据集之后,可将其解压至fcn.berkeleyvision.org/data/目录下,并将文件夹重命名为sift-flow。特别注意的是,由于原目录下已经包含一个命名为sift-flow的文件夹,但是原文件夹中的内容仍需要被copy进新的文件夹下来使用,所以千万不要提前将其删除掉,提前重命名以下即可。
2. 训练文件准备
关于常用文件一些解释:
caffemodel-url中是训练之前预加载的权值模型的下载地址,打开这个文件,并下载这个模型;
deploy.protptxt是训练好模型之后,进行图片预测的网络模型;
net.py是生成网络模型的文件,暂时用不到;
solve.py和solve.prototxt是网络训练之前一些数据路径和参数的设置;
train.prototxt和val.prototxt不用说了,一个是训练模型,一个是训练过程中测试的模型。
step1:修改solver.prototxt。其中,snapshot: 10000,表示每训练10000次保存一次model文件;snapshot_prefix:"/home/pzn/pang1/fcn.berkeleyvision.org/siftflow-fcn32s/train/" 表示把model保存到相应的文件夹下,如果没有,自行新建文件夹即可。我的solver.prototxt文件如下:
train_net: "trainval.prototxt"
test_net: "test.prototxt"
test_iter: 200
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-10
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 30000
weight_decay: 0.0005
snapshot:10000
snapshot_prefix:"/home/pzn/pang1/fcn.berkeleyvision.org/siftflow-fcn32s/train/"
test_initialization: falsestep2:修改slove.py。特别地,在训练fcn32s时,为了避免loss不下降,要通过transplant的方式来获取vgg16的网络权重;后期训练fcn16s和fcn8s的时候,直接可以拿上一级的model来即可,不需要transplant。我的slove.py文件,仅供参考:
import sys
sys.path.append('/home/pzn/caffe/python')
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
# init
caffe.set_mode_gpu()
#caffe.set_device(int(sys.argv[0]))
caffe.set_device(0)
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
solver = caffe.SGDSolver('solver.prototxt')
vgg_net=caffe.Net(vgg_proto,vgg_weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
test = np.loadtxt('../data/sift-flow/test.txt', dtype=str)
for _ in range(5):
solver.step(2000)
# N.B. metrics on the semantic labels are off b.c. of missing classes;
# score manually from the histogram instead for proper evaluation
score.seg_tests(solver, False, test, layer='score_sem', gt='sem')
score.seg_tests(solver, False, test, layer='score_geo', gt='geo') 下载
VGG_ILSVRC_16_layers_deploy.prototxt链接: https://pan.baidu.com/s/1QA691IgCiBC-LTU449jb8g 密码: irxa
step3:开始训练
cd siftflow-fcn32s/
sudo python slove.py如果报错No module named surgery,score,siftflow_layers等,则需要把fcn根目录下的相应的.py文件copy到siftflow-fcn32s目录下即可。
我的训练结果如下:
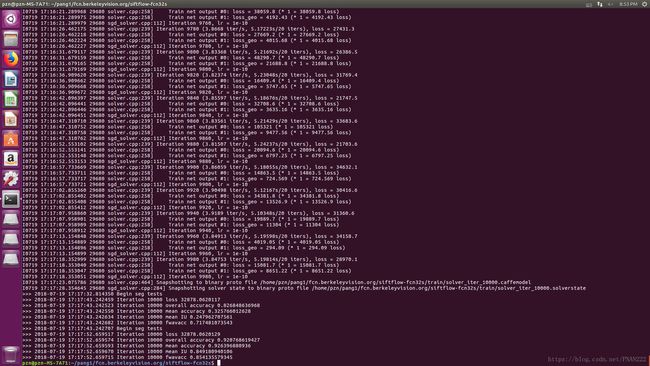
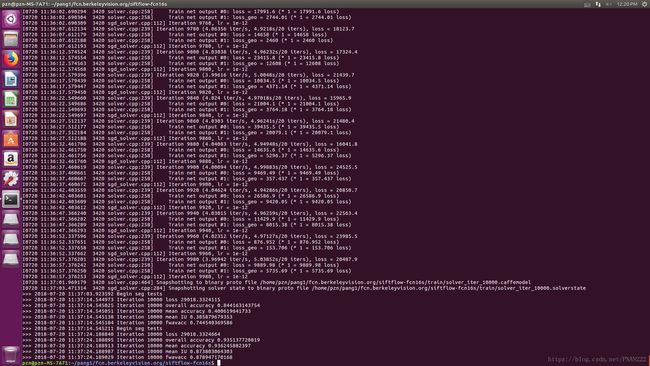
step4:利用训练好的model进行网络正向传播测试
关于infer.py,强烈建议每个数据集对应一个infer.py,尽量不要共用fcn根目录下的infer.py的文件,就像尽量不要共用slove.py一样,否则在训练多个数据集之后,网络正向传播时会乱掉。
我的infer.py文件,仅供参考:
import sys
sys.path.append('/home/pzn/caffe/python')
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import caffe
import vis
# the demo image is "2007_000129" from PASCAL VOC
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('../demo/siftflowyuantu/coast_nat1091.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
# net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
net = caffe.Net('../siftflow-fcn32s/deploy.prototxt', '../siftflow-fcn32s/train/solver_iter_10000.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score_sem'].data[0].argmax(axis=0) #注意修改
#plt.imshow(out,cmap='gray');
plt.imshow(out)
#plt.show()
plt.axis('off')
plt.savefig('../demo/outputsiftflow/coast_nat1091_op.png')
'''
# visualize segmentation in PASCAL VOC colors
voc_palette = vis.make_palette(21)
out_im = Image.fromarray(vis.color_seg(out, voc_palette))
out_im.save('demo/output.png')
masked_im = Image.fromarray(vis.vis_seg(im, out, voc_palette))
masked_im.save('demo/visualization.jpg')
'''
'''
coast_bea1
coast_n286045
coast_nat1091
coast_natu975
forest_natc52
mountain_n213081
mountain_nat426
opencountry_land660
street_par151
street_urb885
tallbuilding_art1004
'''网络正向传播时需要的deploy.prototxt文件,可以直接下载:
链接: https://pan.baidu.com/s/1MJLitNDl9EU3O3Acj2DOWA 密码: 6gdn
制作方式如下:
首先,根据你利用的模型,例如模型是siftflow32s的,那么你就去siftflow32s的文件夹,里面有train.prototxt文件,将文件打开,全选,复制,新建一个名为deploy.prototxt文件,粘贴进去,然后ctrl+F 寻找所有名为loss的layer 只要有loss 无论是loss还是geo_loss 将这个layer统统删除,然后删除输入层,在fcn中就是第一个python层,即删除:
layer {
name: "data"
type: "Python"
top: "data"
top: "sem"
top: "geo"
python_param {
module: "siftflow_layers"
layer: "SIFTFlowSegDataLayer"
param_str: "{\'siftflow_dir\': \'../data/sift-flow\', \'seed\': 1337, \'split\': \'trainval\'}"
}
}
然后在文件顶部加上:
layer {
name: "input"
type: "Input"
top: "data"
input_param {
# These dimensions are purely for sake of example;
# see infer.py for how to reshape the net to the given input size.
shape { dim: 1 dim: 3 dim: 256 dim: 256 }
}
}其中shape{dim:1 dim:3 dim:256 dim:256}中的dim可以随意设置,此处虽然为1 3 256 256,但是caffe会根据所读取的图片进行重新设置dim。
最终,对demo.jpg最终测试可以发现测试后的分割结果并不尽人意,那是因为原来的demo属于voc数据集中的数据,而此数据集为siftflow,并不符合demo的特征,所以分割效果差是理所应当的。采用siftflow数据集中的数据进行测试效果才会更好。
结果图:
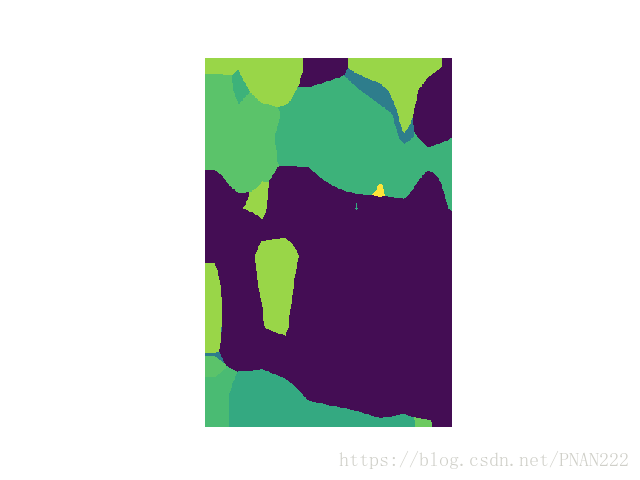
因为不是自己的数据集,跑通了siftflow-fcn32s就好,siftflow-fcn16s和siftflow-fcn8s以此类推,最终8s的model是最好的。
Part 2 在VOC2012数据集上进行训练
VOC数据集,下载地址,共包含21类(包括背景),voc数据集中的颜色类别
类别名称 R G B
background 0 0 0 背景
aeroplane 128 0 0 飞机
bicycle 0 128 0
bird 128 128 0
boat 0 0 128
bottle 128 0 128 瓶子
bus 0 128 128
car 128 128 128
cat 64 0 0
chair 192 0 0
cow 64 128 0
diningtable 192 128 0 餐桌
dog 64 0 128
horse 192 0 128
motorbike 64 128 128
person 192 128 128
pottedplant 0 64 0 盆栽
sheep 128 64 0
sofa 0 192 0
train 128 192 0
tvmonitor 0 64 128 显示器数据集结构如下:
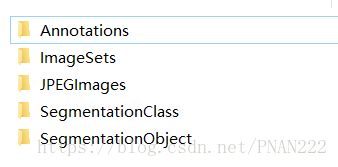
JPEGImages中存放的是所有的原图信息,包括训练图片和测试图片;
Annotation中存放的是xml格式的标签数据,每张图片对应一个xml文件,作为目标检测中的labels,用于目标检测;
ImageSets下的Main文件夹下存放的是train.txt,val.txt,trainval.txt等文件,用于训练过程中遍历和读取图片;
ImageSets下的Segmentation下存放的是用于语义分割的train.txt,seg11valid.txt(验证集,直接把val.txt重命名即可),trainval.txt文件,用于用于训练过程中遍历和读取图片。
SegmentationClass中存放的是.png格式的索引图,作为语义分割中的labels,用于语义分割。
参考了许多大神的blog,大家都在说在训练自己的数据时,要把benchmark数据集和VOC数据集结合起来,把benchmark作为测试集,voc数据集作为验证集,但是在初次跑别人的benchmark时,我就各种跑不通,因为在bechmark数据集中语义级标注的数据中,train.txt和validition数据集写的不是很一致,导致出现有原图但是没有标签,有标签,但是原图可能找不到等类似的情况,其中,报错最厉害的一个错误是:
File "D:\python\lib\site-packages\scipy\io\matlab\miobase.py", line 224, in ge
t_matfile_version
raise MatReadError("Mat file appears to be empty")
scipy.io.matlab.miobase.MatReadError: Mat file appears to be empty报错截图:一迭代到8700-9000次左右就报这个错误也是很无奈。
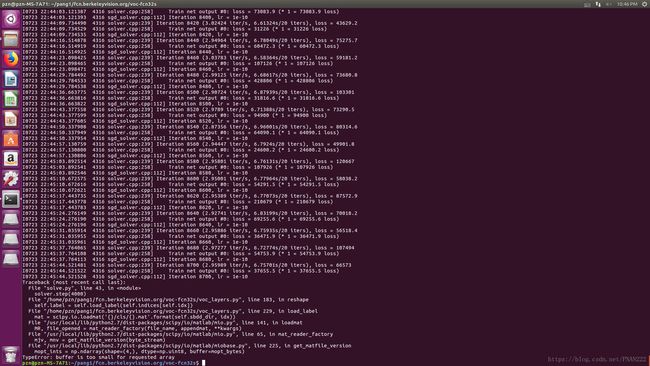
多方抢救无效后,参考别的小组做faster-RCNN的数据制作方式,我想到了只用VOC2012数据集的方式来解决问题。
在两个(benchmark和voc)数据集合并使用时会遇到的错误和建议的解决方案:
训练FCN的过程中,当报错某个(些).mat文件找不到时,最好的方式不是找到这个mat文件,因为会因为非法引入的mat文件破坏掉结构,从而导致产生其他的错误。
相反,最好的方式而是修改训练时的train.txt,舍掉这些找不到数据的原图像的读入,有舍才有得,方为上上策。
所以,只应用VOC数据集,直接跑语义分割的数据,应用的文件参考如下:
首先是solve.py文件:
# -*- coding: utf-8 -*-
import sys
sys.path.append('/home/pzn/caffe/python')
import caffe
import surgery, score
import matplotlib.pyplot as plt
import numpy as np
import os
import math
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
#weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
# init
#caffe.set_device(int(sys.argv[1]))
caffe.set_mode_gpu()
caffe.set_device(0)
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
solver = caffe.SGDSolver('solver.prototxt')
vgg_net=caffe.Net(vgg_proto,vgg_weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
val = np.loadtxt('/home/pzn/pang1/fcn.berkeleyvision.org/data/pascal/VOCdevkit/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str)
for _ in range(500):
solver.step(100)
score.seg_tests(solver, False, val, layer='score')然后是slover.prototxt文件:
train_net: "/home/pzn/pang1/fcn.berkeleyvision.org/voc-fcn32s/train.prototxt"
test_net: "/home/pzn/pang1/fcn.berkeleyvision.org/voc-fcn32s/val.prototxt"
test_iter: 736
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-10
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 100
snapshot_prefix: "/home/pzn/pang1/fcn.berkeleyvision.org/voc-fcn32s/train/"
solver_mode: GPU
device_id: 0
test_initialization: false再就是train.prototxt和val.prototxt的开头需要修改:
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "VOCSegDataLayer"
param_str: "{\'voc_dir\': \'../data/pascal/VOCdevkit/VOC2012\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
}
}layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "VOCSegDataLayer"
param_str: "{\'voc_dir\': \'../data/pascal/VOCdevkit/VOC2012\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
}
}修改之后,则可以运行:
sudo python slove.py若网络一旦跑起来无异常,则说明配置成功!
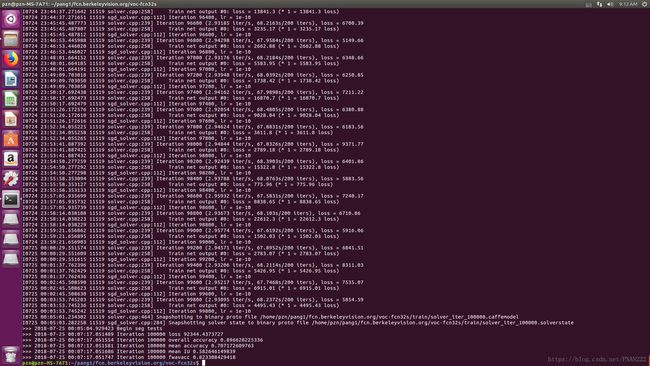
接下来就是训练自己的数据啦!