基于飞桨PaddlePaddle的地标检索识别夺竞赛双料大奖,获奖方案全解析
近日,百度视觉团队基于飞桨(PaddlePaddle)深度学习平台,自主研发的地标检索/识别解决方案,在 Google Landmark Retrieval 2019[1] 和 Google Landmark Recognition 2019[2] 两个任务中都斩获第二名,并受邀在计算机视觉领域的顶级学术会议 CVPR 2019 上进行技术分享。
Google 今年更新了目前最大的人造和自然地标识别数据集,发布了 Google-Landmarks-v2,数据集中包含超过 400 万张图片,描述了 20 万处类别地标。训练数据没有经过精细人工标注,类别数目严重不均衡,同一个地标的图像受到拍摄角度、遮挡、天气以及光线等影响很大,同时含有大量非地标数据,符合实际情况,非常具有挑战性。基于此数据集,今年总共吸引全球超过 300 支队伍参与了 Google 主办的地标检索识别竞赛。

图 1 一些地标示例图像以及 top5 的检索结果
地标检索任务关注给定一张图像,需要找到给定数据库中所有相同的地标图像。评估数据超过 10 万张待查询图像(test 集合),以及将近 80 万的检索数据库 (index 集合)。
地标识别任务关注给定一张图像,标注该图像是不是地标,如果是地标,需要标注其在 20 万种地标的类别。
评估数据与地标检索任务的待查询图像相同,据比赛完推算,其中有地标的图像不到 2000 张。当前,百度视觉团队的获奖方案已经提交到 arxiv 上,并且在 Github 上开源代码。下面将为大家详细解读。
论文地址:https://arxiv.org/pdf/1906.03990.pdf
开源项目地址:https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/Research/landmark
地标检索解决方案
在地标检索比赛中,我们使用 ImageNet 预训练的模型参数作初始化,然后在 GLD v2(Google LandMark Dataset V2)上进行训练。网络结构上,我们使用了 ResNet 152 [4], ResNet200 [4], SE_ResNeXt152 [5] 和 Inception V4[6] 作为骨干网络。其中 ResNet 系列都是基于论文 [3],使用了 ResNet_VD 的改进版本,这 4 个模型在 ImageNet 上的 1000 分类任务上 top1 的准确率分别为 80.59%,80.93%,81.40% 和 80.77%。这些模型及训练方法都已经在飞桨的 Github 图像分类项目中开源 [7]。

图 2 地标检索任务解决方案流程图
在训练检索特征过程中,为了使特征紧凑,通过一层全连接将骨干网的输出(不包含 softmax 分类全连接层以及之后的网络)映射到 512 维,同时采用 arcmargin loss[8] 替换传统的 softmax loss,调整训练图像分辨率为 448*448,进一步提升模型特征的表达能力。此外,比赛过程中还基于 Npairs Loss[9],以及将 index 集合的 80 万张图像聚类后加入训练,学习更多种不同维度的特征,提升整个系统的泛化能力。所有训练检索特征的代码也已经在飞桨的 Github 度量学习项目中开源 [10]。
在解决方案中,除了基础特征外,检索策略还使用了 Query Expansion(QE)[11] 和 Database Augmentation(DBA) 策略。不同于传统的 QE 和 DBA,在选取平均队列中,进一步加入了 Local feature 重排和分类重排。Local feature 能够拉回一些角度,尺度变换大的 Case,如图 3 所示。

图 3 局部特征效果示例
此外,比赛中,还基于全量数据训练了分类模型,通过分类 rerank 来进一步提升检索指标。分类能够拉回一些跨域的图片,比如一张 test 图片可以拉回相应地标的老照片等。在分类重排的时候,使用了多分类投票的策略,投票选取了 test 和 index 图片的类别,从而每一张 test 图片请求 index 库时候,把相同类别的图片前置。利用分类和 Local feature 进行重排后,能进一步提升 QE 和 DBA 的效果。具体的效果如表 1 所示。
地标检索任务评估指标采用 mAP@100,详细定义参考 Google Landmark Retrieval 2019[1] 官方说明
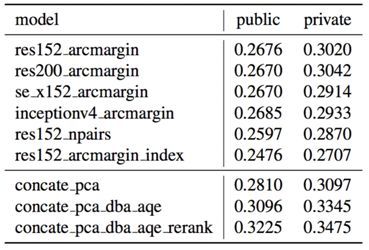
表 1 不同模型和策略的检索效果
地标识别解决方案

图 4 地标识别任务解决方案流程图
地标识别任务解决方案流程如上图,主要包含如下三步:
1. 基于全局检索特征识别地标类别。
在地标识别任务中,利用检索特征,用 11 万的测试集合与 400 万的训练集合进行匹配。基于检索结果中 top5 图片的 label, 对它们进行类别投票,选取 top5 中类别最多的类当作测试图片的预测类别,该类最大得分作为预测得分。这一步后,GAP 指标会达到 private/public:0.10360/0.09455。由于识别比赛使用 GAP(Global Average Precision)作为评估指标(详细定义参考 Google Landmark Recognition 2019[2] 官方说明),如果大量非地标图像得分也很高,则会大幅度的降低 GAP 指标。虽然检索特征的识别效果很好,可以准确识别出地标的类别,但是由于检索任务并没有考虑非地标图的过滤,部分非地标图得分也很高,所以直接使用检索特征,GAP 指标并不理想。地标识别任务的一个关键是如何排除掉大量的非地标图像。
2. 基于通用目标检测器过滤非地标图像
为了过滤非地标图像,在比赛中,基于 Faster RCNN 通用目标检测算法 [12] 和公开的 Open Image Dataset V4 数据集 [13] 训练了一个通用目标检测器。Open Image Dataset V4 包含了超过 170 万的图片数据,500 个类别以及超过 1200 万物体框。百度视觉团队曾经在 Google AI Open Images-Object Detection Track(简称OpenImagesV4Det[14]) 目标检测任务中斩获第一。OpenImagesV4Det 的夺冠方案融合了不同深度学习框架和不同骨干网络多种检测器。而在地标识别比赛中,为了提高预测速度,借鉴 OpenImagesV4Det 比赛中采用的动态采样、多尺度训练以及 soft-nms 等经验,选取 ResNet50 作为骨干网络,重新训练一个单模型目标检测器,该检测器只采用单尺度测试,在 OpenImagesV4Det 比赛 public LB 的指标可以达到 0.55。单模型检测效果达到 OpenImagesV4Det 比赛 top10 水平。这个检测模型的预测代码已经随本解决方案开源,其训练代码计划后续开源在飞桨的检测模型库里。
基于上述目标检测器过滤非地标图像主要有如下两步:
-
目标检测器把所有的 test 集合图像分成了三个部分:地标集合,非地标集合以及模棱两可的图像集合。给定一张图像,利用图像物体之间的关联性,认为只要检测出的结果中包含 Building, Tower, Castle, Sculpture and Skyscraper 类别,那么这张图像就是包含地标的图片。如果检测器中包含 House, Tree, Palm tree, Watercraft, Aircraft, Swimming Pool 和 Fountain,那么就认为该目标是模棱两可,无法判断是不是含有地标,直接忽略。对于非地标集合,如果检测框得分大于 0.3,而且检测框占原图的面积大于 0.6,则认为这张图像是非地标图像。通过这一步,从 11 万多的测试集合中过滤出了 2.8 万的非地标图片。
-
为了进一步过滤非地标图像,解决方案中使用剩下的测试集合图片去检索上述非地标的 2.8 万张图像,如果检索 top3 的图片 score 超过了阈值,那么也认为该图片是非地标。通过这一步,又过滤了 6.4 万的图片。经过上述两步,一共过滤了 9.2 万张图片,GAP 指标达到 private/public:0.30160/0.28335。
3. 多模型融合
在过滤完非地标图片之后,解决方案里使用了多模型融合的策略进一步提升 GAP。
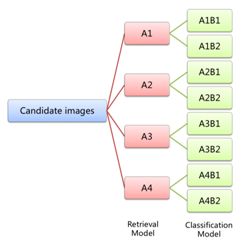
图 5 多模型分区策略
如图 5 所示,先使用 ResNet152 的检索模型对所有被识别为地标的图像进行分区,具体的分区规则为:
-
A1:测试图像去检索 400 万的训练数据库,top5 的类别少于等于 2 类,并且最小的预测分值>= 0.9;
-
A2:类似于 A1,top5 的类别少于等于 2 类,最大的预测分值>=0.85;
-
A3:不同于 A1,A2,A4 以外的图像;
-
A4:所有 Top5 返回图像的类别都完全不相同。
根据检索返回的类别和得分进行分区后,按照 A1 > A2 > A3 > A4 进行排序,GAP 的值达到 private/public:0.31340/0.29426。
对上述每个分区,进一步用分类模型的信息进行细分。
-
B1:检索预测的类别和分类预测的类别相同;
-
B2:不满足 B1 条件的图片。
使用 B 策略对 A 的每个分区内进行重排,识别效果进一步提升,GAP 指标达到 private/public:0.32574/0.30839。
最后,采用针对这个比赛才适用的 trick,即基于测试图像中地标类别出现的频率排序,GAP 达到 private/public: 0.35988/0.37142。比赛后,对上述策略进一步调参,发现 GAP 可以达到 private/public: 0.38231/0.36805。超越目前榜单最高分 private/public: 0.37606/0.32101。感兴趣的读者可以参看论文。这个策略之所以有效,初步推测可能与比赛的真值漏标有关。
总结
本文所介绍的图像识别和特征学习技术已经应用到百度的图像识别检索应用中,为通用图像搜索入口(图搜,手百)提供通用检索识别能力,同时覆盖商品、车型、品牌 logo、景点、植物花卉、公众人物识别等多种垂类的识别。
本次比赛完全基于飞桨深度学习平台实现,飞桨是集深度学习核心框架、工具组件和服务平台为一体的技术领先、功能完备的开源深度学习平台。百度视觉团队联合飞桨在视觉技术上有深厚的积累,目前 PaddleCV 已开源覆盖图像分类、图像目标检测、特征学习、图像分割、OCR、人脸检测、GAN、视频理解等类别,基于真实业务场景验证的、效果领先的优质模型,例如目标检测经典模型 YOLOv3,基于飞桨的实现,增加了 mixup,label_smooth 等处理,精度 (mAP(0.5:0.95)) 相比于原作者提高了 4.7 个绝对百分点,在此基础上加入 synchronize batch normalization, 最终精度相比原作者提高 5.9 个绝对百分点。
百度视觉团队曾首创了 Pyramidbox、Ubiquitous Reweighting Network、Action Proposal Network、StNet 和 Attention Clusters 等算法,在识别人、识别物、捕捉关系三个技术领域均具备业界最领先的技术实力,不仅用于百度内部产品,也通过百度 AI 开放平台持续对外输出,目前已对外开放了包括人脸识别、文字识别(OCR)、图像审核、图像识别、图像搜索等在内的 70 多项基础能力,为开发者和合作伙伴提供全栈式计算机视觉能力,让他们将领先的 AI 能力转换成让复杂的世界更简单的神奇力量,进而推动全行业、全社会的智能化变革。
参考文献
[1] https://www.kaggle.com/c/landmark-retrieval-2019
[2] https://www.kaggle.com/c/landmark-recognition-2019
[3]Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, JunyuanXie, Mu Li, Bag of Tricks for Image Classification with Convolutional NeuralNetworks, In CVPR 2019
[4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR 2016
[5] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. In CVPR 2018
[6] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander AAlemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI 2017
[7]https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification
[8] Jiankang Deng, JiaGuo, NiannanXue, and StefanosZafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv preprint arXiv:1801.07698, 2018.
[9] Kihyuk Sohn, Improved Deep Metric Learning with Multi-class N-pair Loss Objective, In NIPS 2016
[10]https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/metric_learning
[11] OndrejChum,JamesPhilbin,JosefSivic,MichaelIsard,and Andrew Zisserman. Total recall: Automatic query expan- sion with a generative feature model for object retrieval. In ICCV 2007
[12]Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, BharathHariharan, Serge Belongie, Feature Pyramid Networks for Object Detection, In CVPR 2017
[13]https://storage.googleapis.com/openimages/web/factsfigures_v4.html
[14]https://www.kaggle.com/c/google-ai-open-images-object-detection-track
ps:最后给大家推荐一个GPU福利 - Tesla V100免费算力!配合PaddleHub能让模型原地起飞~ 扫码下方二维码申请~

