TensorFlow+深度学习笔记5
TensorFlow+深度学习笔记5
标签(空格分隔): TensorFlow+深度学习笔记
本周掌握的内容:
- 理解了GAN网络的历史、结构、重要性;
- 学习了pix2pix论文,并在facades数据集上面完成模型训练和测试。
- 在pix2pix的基础上重新阅读了zi2zi代码,并完成模型测试。
Task 6:Generation and Segmentation
方向:图像生成
学习清单:
- 学习理解 GAN
- 学习 pix2pix 论文,并重现论文实验
参考资料:
- 深度 | 生成对抗网络初学入门:一文读懂GAN的基本原理(附资源)
- 干货 | 直观理解GAN背后的原理:以人脸图像生成为例
- 生成式对抗网络GAN研究进展(二)——原始GAN
- pix2pix论文以及代码
GAN网络架构
GAN基本原理
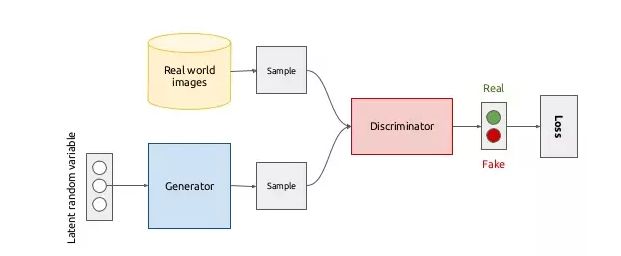
上图来自机器之心
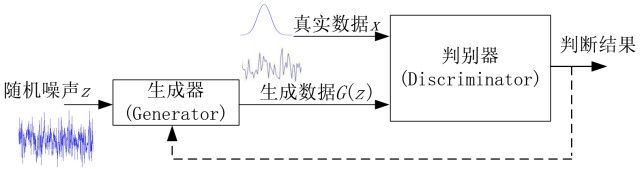
对抗生成网络主要由生成部分G,和判别部分D组成。训练过程描述如下
1. 输入噪声z(隐藏变量)
2. 通过生成器Generator 得到生成数据G(z)
3. 从真实数据集中取一部分真实数据 x
4. 将两者混合 x + G(z)
5. 将数据喂入判别器Discriminator ,给定标签 x = 1, G(z) = 0(简单的二类分类器)
6. 按照分类结果,回传loss
在整个过程中, D(判别器)要尽可能的使 D(x) -> 1,D(G(z)) -> 0 。而 G(生成器)则要使得 D(G(z)) -> 1,即让生成的图片尽可能以假乱真。整个训练过程就像是两个玩家在相互对抗,也正是这个名字Adversarial的来源。
机器学习的模型可大体分为两类,生成模型(Generative Model)和判别模(Discriminative Model)。GAN就是将Generator和Discriminator紧密结合起来(两者相互讨论,相互进化)。
生成模型可以被看作是一队伪造者,试图伪造货币,不被人发觉,然而辨别模型可被视作一队警察,努力监察假的货币。游戏当中的竞争使得这两队不断的改善方法,直到无法从真实的物品中辨别出伪造的。
在理想最优状态,生成器将知道如何生成真实的人脸图片,辨别器也会知道人脸的组成部分。
链接2提供了一个有趣的对话来理解生成器和判别器的关系:
初级状态:
G:我有一张人脸图片,它跟你以前见过的相比,足够真实吗?
D:比较真实但也比较像是你生成的图片。(对真实图片,辨别器产生 0.4 的概率) 我不太确定但我猜你给我的应该是一张生成的图片。
G:你猜对了!是我生成的一张图片。我应该怎样调整来让它更真实呢?
D:让我想一下 (实际上在大脑里在做反向传播运算) 我认为你应该往图片里添加一对眼睛,人脸图片通常会包含眼睛。
(技术上来说:我认为你应该增加第 0 号像素的灰度值增加 1,第 1 号像素的灰度值减少 5 个,…, 第 4095 个像素的灰度值增加 8 个)
G:收到 (反向传播那些梯度给所有的权重)
较优状态:
G:我有一张人脸图片,它跟你以前见过的人脸图片相比足够真实吗?
D:这张图片真的很真实 (对真实图片,辨别器会产生 0.5 的概率) 但是这张图片是不是真的,我完全没有头绪。因为显而易见的是,你在生成真实图片上做的太好了。
G:这是我生成的一张图片。我知道这已经是真实的了但是我想要更多,我应该如何调整来使它变的更真实?
D:让我想一下 (实际上大脑里在做反向传播) 我认为你的图片已经有了我认为需要有的部分。我看起来非常真实。显然你的图片包含眼睛,嘴巴,耳朵,头发,图片里是一张年轻男孩的脸。我不认为我有建议的东西。但是如果你想的话,可以把年轻男孩的胡须去掉。
(技术上来说,我认为你第 0 个像素灰度值增加 6,第 1 个像素灰度值减少 7,…,第 4095 个像素灰度值增加 2。)
G:收到 (反向传播那些梯度给所有的权重)
最优状态:
生成器会生成真实的图片,辨别器不再能辨别生成的图片。它们在无人监督的情况下也都能理解胡须,眼睛,嘴巴,头发,年轻的脸庞。已经达到了一种平衡。
理论的GAN模型很不稳定,训练难度比较大。一些改进的GAN使得训练变得相对简单和稳定(所以对抗网络的稳定训练,依然是一个研究的热点和方向):
深度卷积生成对抗网络(DCGAN)
相对于原生GAN,DCGAN最大的特点就是使用了卷积层:
下图是DCGAN生成器的网络结构:
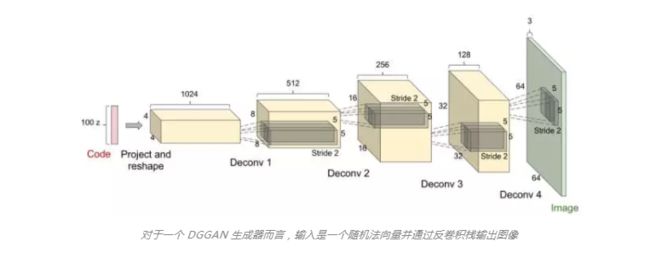
从输入的100维噪声到输出的64*64*3的图像,这中间经历了“反卷积过程”(卷积操作的逆过程)
下图是DCGAN判别器的网络结构:
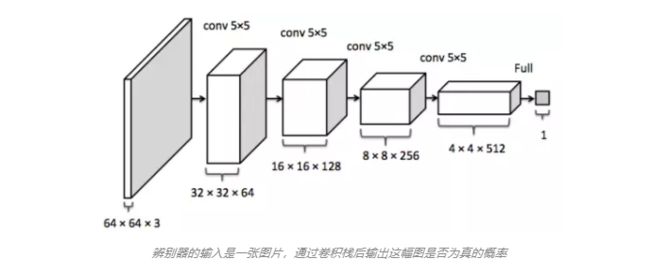
可以参考链接DCGAN对抗卷积神经网络总结条件 GAN(Conditional GAN)
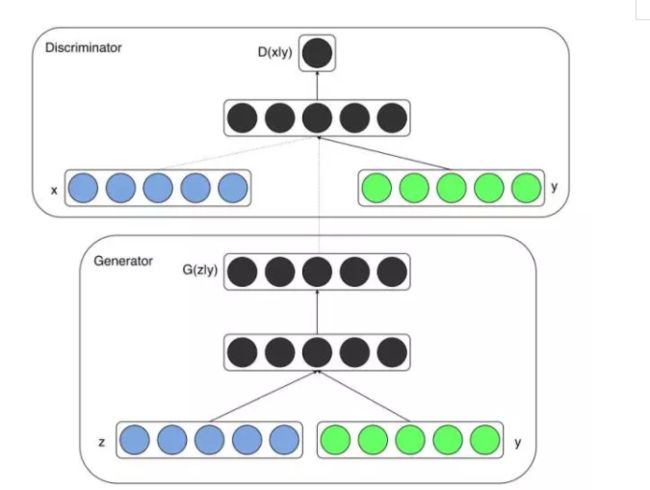
这里的x代表真实数据,z代表噪声,绿色的y是标签。
这部分参考了两个连接Conditional Generative Adversarial Nets论文笔记、Conditional Generative Adversarial Nets
论文作者的两个实验所使用的数据都是带有标签的,并且根据有无监督学习的定义来看,conditional GAN属于有监督学习(原生GAN没有加入标签数据y,属于无监督学习)。
原生的GAN训练起来太过自由,不够稳定。使用y这个额外的条件变量,对生成器对数据的生成具有指导作用,解决了训练太过自由的问题。
GAN优缺点
优点:
- 根据实际的结果,它们看上去可以比其它模型产生了更好的样本
- 生成对抗式网络框架能训练任何一种生成器网络
- 不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
缺点:
- 解决不收敛(non-convergence)的问题
- 难以训练:崩溃问题(collapse problem)
- 无需预先建模,模型过于自由不可控。
论文学习报告
1 论文工作与贡献
这篇文章研究了conditional adversarial networks是否可以作为一种解决image-to-image转换问题的通用方法。最后的结论是conditional adversarial networks可以作为解决这类问题的通用方法。
image-to-image转换问题可以理解为给定一张输入图像,得到满足需求的输出图像(例如输入图像是低分辨率,输出图像是高分辨率;输入图像是手绘线条图,输出图像是油画等等)。然而对于不同的输出目的,需要不同的解决方法(使用不同的神经网络、选择不同的损失函数来达到目的)。但是本篇论文所使用的conditional adversarial networks可以解决所有问题,只需要给足够的训练数据,网络就能够学习训练数据的特征分布得到相应模型,使用这个模型我们就能够预测(生成)符合训练数据特征的图像。
在学习笔记1中我运行了一个基于CNN风格转变的代码,也知道CNN可以被大量使用来解决此类问题(image-to-image转换问题),但是这并不是完全自动的算法,还是需要告诉CNN如何才能得到符合我们目的的结果(选择合适的损失函数,使用不同的损失函数可能得到不同的结果,模糊的,锐化的等等)。
本文使用的conditional adversarial networks可以使我们站在更高的维度去解决这个问题,我们只需要告诉网络:“使生成的图像要和真实的图像难以区分”,这时网络就能够自动学习损失函数(而不需要我们手动选择和比较)生成符合要求的图像。但是使用原生的GAN,就会导致很多问题(训练太自由、不稳定等等),本文给GAN加了约束条件,变成了条件GAN,这是对原生GAN的一种改进,是把无监督的GAN变成有监督模型的一种改进。最终取得了很好的结果。
论文的贡献主要有以下两点:
- 证明了对于绝大多数image-to-image转换问题,条件GAN是一种通用的方法,可以得到符合要求的结果
- 提出了一个简单的网络框架,并且得到了很好的结果,并分析了几个比较重要的体系结构。
2 相关工作
1 结构性损失(structured loss):
在传统的方法中,每一个输出的像素都和输入图像的其它像素是条件独立的(unstructured loss),然而conditional GANs学习到的是structured loss。有大量的文献使用了这种loss:

conditional GAN与前面提到的工作的不同之处在于它的loss是学习来的,并且从理论上说conditional GAN还可以惩罚输出图像和目标图像之间的特征差异。
2 使用GAN(条件或非条件):
本文并不是第一次做conditional GAN的相关工作,在此之前已经有过大量的工作:

此外还有一些使用非条件GAN的工作:

但是这些工作都有一个共同的特点:它们不具备泛化性,也就是说它们的方法都只能用来解决某一方面的问题(超分辨率、图像修复等等)。但是本文的方法具有很强的通用性,可以解决多种问题。
此外本文使用的GAN还有一些不同:生成器使用U-Net体系结构,判别器使用PatchGAN。这里的Patch很好理解,Patch的英文翻译是“补丁,小块”,在这里我们可以理解为图像的某一个部分(比如25*25的图像,它的左上角3*3的部分图像就是它的一个Patch)。判别器使用PatchGAN,这也就呼应了前面提到的structured loss,很显然每一个输出像素都和Patch的其它像素是有联系的。本文还研究了不同patch size对结果的影响。
3 论文提出的网络架构与方法原理
方法原理:
生成器G:
![]()
其中x是输入图像,z是随机噪声,y是输出图像。生成器G的目的就是使得生成的y导致判别器难以分别其真假。
判别器D:
判别器的目的就是要尽可能分辨出假的图像。

cGAN的目标:

生成器G要使得上式最小化,判别器D则要使其最大化,最终达到一个平衡。
文章为了测试判别器的重要性,除去了判别器中的参数x:
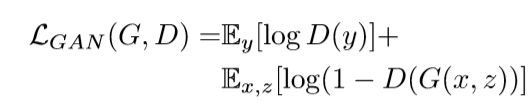
第一个式子证明了使用越传统的loss(例如L2),就越容易最小化;第二个式子也得出相同的结论。然而生成器G的任务不仅需要尽可能欺骗判别器D,还要使得L2尽可能小。作者探索了这个问题,将L2替换成L1,最终使用的objective如下:
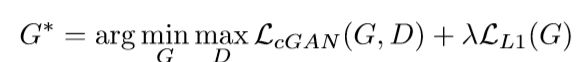
此外文章还讨论了是否使用噪声z带来的影响。如何除去z,将产生确定性输出,因此不能匹配除δ函数以外的任何分布。作者最终使用的噪声是dropout处理后的噪声,并且取得了很好的效果。
网络架构:
作者使用的生成器G和判别器D的体系结构来自于文章UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
,生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块。
生成器:
很多之前的工作都是使用这样的结构:encoder-decoder。如下:
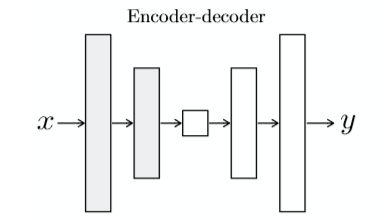
就是将输入图像一直下采样,直到一个“瓶颈层”,然后开始上采样,最终得到的输出和原始输入有相同的大小。这个操作导致大量的low-level图像信息传输到输出图像。为了规避这个瓶颈,文章使用了U-Net结构:
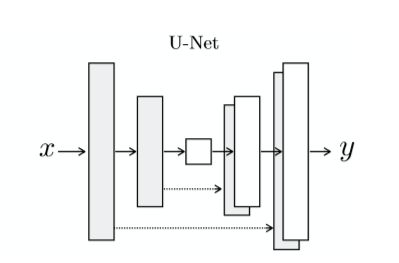
以“瓶颈层”为界限,下采样层和上采样层对应有skip connection。
判别器:
对于低频图像信息,L1或L2都能很好地捕获,所以不需要寻找其它方法来完成这个工作。低频图像信息是图像的大致轮廓(模糊的图像)。
对于高频图像信息,使用PatchGAN结构,这里判别器只需判断每一个patch的真假,判别器使用一个N*N的filter在输入图像上采样,采样的结果就是一个patch,然后判断这个patch的真假。最终在对输入图像进行卷积式地采样工作结束后,将所有patch的结果做一个平均,得到的平均值就是这张图像的真假结果。文章还证明了即使filter的N值很小也可以得到很好的结果,这侧面展示了一个优点:使用较小的N值使得所需参数更少,计算更快,可以将算法使用在任意大小的图像上面。
优化:
文章有4个优化点,如下对每个优化点使用不同颜色标出:

4 论文实验细节
泛化性:
为了证明文章使用结构的泛化性,作者在多个数据集上面做了测试:

作者发现使用比较少的数据集也能生成像样的结果,作者使用的是facades数据集(我做测试的时候也使用的是这个)。在单个Pascal Titan X GPU训练不到两个小时就结束了(我训练模型的时候用了4个小时,也是在单个GPU上训练,这次我加入了控制GPU资源使用的代码,因为tensorflow默认占用全部资源,相关链接见笔记1),最后测试的时候生成一张新图像一秒钟就可以搞定(我的也是这样,非常快)。
评价指标:
作者使用的评价指标有两个
- AMT perceptual studies
- “FCN-score”
分析objective function:
文章对所使用的objective function的每一个部分的重要性做了分析,并对无条件和有条件输入的判别器进行对比。

可以看出L1得到比较模糊的图像,cGAN得到比较锐化的图像,当objective function中的参数 λ = 100的时候得到L1+cGAN的结果。
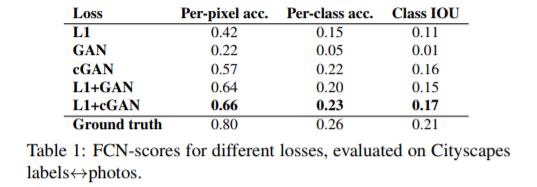
作者使用FCN-score来评价上面的图像,发现L1+cGAN的分数最高。此外文章还指出使用cGAN而不是GAN,会使得得到的结果色彩更加鲜艳。此外L1得到的结果更加趋向模糊和灰度(颜色和原图相比不够鲜艳)。
分析生成器:
文章分析了U-Net的特点,得到了如下的结果:

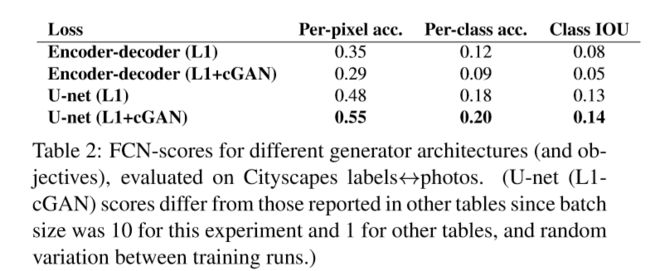
可以看到U-Net使得结果效果更好
分析判别器:
文章使用不同的patch size做了实验(从1到286),结果如下:

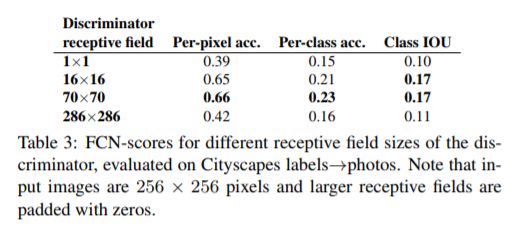
最后作者指出本文所使用的patch size为70,loss为L1+cGAN。
此外文章还讨论了语义分割的相关问题。
实验结论:
文章最后得到的结论是作者所使用的网络结构具有很强的泛化性,能够解决很多image-to-image转换问题。
代码讲解
前面的笔记已经分析了很多卷积操作、池化操作等等比较基础的代码,这次我将详细介绍作者代码的生成器和判别器部分,其它细节将略过。
#生成器
def create_generator(generator_inputs, generator_outputs_channels):
layers = []
# encoder_1: [batch, 256, 256, in_channels] => [batch, 128, 128, ngf]
# 这部分是卷积操作a.ngf参数是outputs_channels
with tf.variable_scope("encoder_1"):
output = gen_conv(generator_inputs, a.ngf)
layers.append(output)
#生成器的encoder部分,这里是下采样操作,但是可以看出outputs_channels在增加
layer_specs = [
a.ngf * 2, # encoder_2: [batch, 128, 128, ngf] => [batch, 64, 64, ngf * 2]
a.ngf * 4, # encoder_3: [batch, 64, 64, ngf * 2] => [batch, 32, 32, ngf * 4]
a.ngf * 8, # encoder_4: [batch, 32, 32, ngf * 4] => [batch, 16, 16, ngf * 8]
a.ngf * 8, # encoder_5: [batch, 16, 16, ngf * 8] => [batch, 8, 8, ngf * 8]
a.ngf * 8, # encoder_6: [batch, 8, 8, ngf * 8] => [batch, 4, 4, ngf * 8]
a.ngf * 8, # encoder_7: [batch, 4, 4, ngf * 8] => [batch, 2, 2, ngf * 8]
a.ngf * 8, # encoder_8: [batch, 2, 2, ngf * 8] => [batch, 1, 1, ngf * 8]
]
#进行encoder操作,印证了论文所说的生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块
for out_channels in layer_specs:
with tf.variable_scope("encoder_%d" % (len(layers) + 1)):
#激活操作
rectified = lrelu(layers[-1], 0.2)
# [batch, in_height, in_width, in_channels] => [batch, in_height/2, in_width/2, out_channels]
convolved = gen_conv(rectified, out_channels)
output = batchnorm(convolved)
layers.append(output)
#生成器的decoder部分,这里是上采样操作
layer_specs = [
(a.ngf * 8, 0.5), # decoder_8: [batch, 1, 1, ngf * 8] => [batch, 2, 2, ngf * 8 * 2]
(a.ngf * 8, 0.5), # decoder_7: [batch, 2, 2, ngf * 8 * 2] => [batch, 4, 4, ngf * 8 * 2]
(a.ngf * 8, 0.5), # decoder_6: [batch, 4, 4, ngf * 8 * 2] => [batch, 8, 8, ngf * 8 * 2]
(a.ngf * 8, 0.0), # decoder_5: [batch, 8, 8, ngf * 8 * 2] => [batch, 16, 16, ngf * 8 * 2]
(a.ngf * 4, 0.0), # decoder_4: [batch, 16, 16, ngf * 8 * 2] => [batch, 32, 32, ngf * 4 * 2]
(a.ngf * 2, 0.0), # decoder_3: [batch, 32, 32, ngf * 4 * 2] => [batch, 64, 64, ngf * 2 * 2]
(a.ngf, 0.0), # decoder_2: [batch, 64, 64, ngf * 2 * 2] => [batch, 128, 128, ngf * 2]
]
#进行decoder操作,印证了论文所说的生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块
#此外这里也证实了作者使用的是U-Net结构,对应的encoder层和decoder层之间有skip connection
num_encoder_layers = len(layers)
for decoder_layer, (out_channels, dropout) in enumerate(layer_specs):
skip_layer = num_encoder_layers - decoder_layer - 1
with tf.variable_scope("decoder_%d" % (skip_layer + 1)):
if decoder_layer == 0:
# first decoder layer doesn't have skip connections
# since it is directly connected to the skip_layer
input = layers[-1]
else:
input = tf.concat([layers[-1], layers[skip_layer]], axis=3)
rectified = tf.nn.relu(input)
# [batch, in_height, in_width, in_channels] => [batch, in_height*2, in_width*2, out_channels]
output = gen_deconv(rectified, out_channels)
output = batchnorm(output)
if dropout > 0.0:
output = tf.nn.dropout(output, keep_prob=1 - dropout)
layers.append(output)
# decoder_1: [batch, 128, 128, ngf * 2] => [batch, 256, 256, generator_outputs_channels]
with tf.variable_scope("decoder_1"):
input = tf.concat([layers[-1], layers[0]], axis=3)
rectified = tf.nn.relu(input)
output = gen_deconv(rectified, generator_outputs_channels)
output = tf.tanh(output)
layers.append(output)
return layers[-1]
#创建模型
def create_model(inputs, targets):
#判别器
#使用PatchGAN结构,这里判别器只需判断每一个patch的真假,判别器使用一个N*N的filter在输入图像采样,
#采样的结果就是一个patch,然后判断这个patch的真假。最终在对输入图像进行卷积式地采样工作结束后,将所
#对所有patch的结果做一个平均,得到的平均值就是这张图像的真假结果。
def create_discriminator(discrim_inputs, discrim_targets):
n_layers = 3
layers = []
# 2x [batch, height, width, in_channels] => [batch, height, width, in_channels * 2]
input = tf.concat([discrim_inputs, discrim_targets], axis=3)
# layer_1: [batch, 256, 256, in_channels * 2] => [batch, 128, 128, ndf]
# 第1层:印证了论文所说的生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块
with tf.variable_scope("layer_1"):
convolved = discrim_conv(input, a.ndf, stride=2)
rectified = lrelu(convolved, 0.2)
layers.append(rectified)
# layer_2: [batch, 128, 128, ndf] => [batch, 64, 64, ndf * 2]
# layer_3: [batch, 64, 64, ndf * 2] => [batch, 32, 32, ndf * 4]
# layer_4: [batch, 32, 32, ndf * 4] => [batch, 31, 31, ndf * 8]
# 第2,3,4层:印证了论文所说的生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块
for i in range(n_layers):
with tf.variable_scope("layer_%d" % (len(layers) + 1)):
out_channels = a.ndf * min(2**(i+1), 8)
stride = 1 if i == n_layers - 1 else 2 # last layer here has stride 1
convolved = discrim_conv(layers[-1], out_channels, stride=stride)
normalized = batchnorm(convolved)
rectified = lrelu(normalized, 0.2)
layers.append(rectified)
# layer_5: [batch, 31, 31, ndf * 8] => [batch, 30, 30, 1]
# 第5层:印证了论文所说的生成器G和判别器D都使用convolution-BatchNorm-ReLu这样的模块
with tf.variable_scope("layer_%d" % (len(layers) + 1)):
convolved = discrim_conv(rectified, out_channels=1, stride=1)
output = tf.sigmoid(convolved)
layers.append(output)
return layers[-1]
#开始创建模型
with tf.variable_scope("generator"):
out_channels = int(targets.get_shape()[-1])
outputs = create_generator(inputs, out_channels)
# create two copies of discriminator, one for real pairs and one for fake pairs
# they share the same underlying variables
# 下面是定义各种损失函数
with tf.name_scope("real_discriminator"):
with tf.variable_scope("discriminator"):
# 2x [batch, height, width, channels] => [batch, 30, 30, 1]
predict_real = create_discriminator(inputs, targets)
with tf.name_scope("fake_discriminator"):
with tf.variable_scope("discriminator", reuse=True):
# 2x [batch, height, width, channels] => [batch, 30, 30, 1]
predict_fake = create_discriminator(inputs, outputs)
with tf.name_scope("discriminator_loss"):
# minimizing -tf.log will try to get inputs to 1
# predict_real => 1
# predict_fake => 0
discrim_loss = tf.reduce_mean(-(tf.log(predict_real + EPS) + tf.log(1 - predict_fake + EPS)))
with tf.name_scope("generator_loss"):
# predict_fake => 1
# abs(targets - outputs) => 0
gen_loss_GAN = tf.reduce_mean(-tf.log(predict_fake + EPS))
gen_loss_L1 = tf.reduce_mean(tf.abs(targets - outputs))
gen_loss = gen_loss_GAN * a.gan_weight + gen_loss_L1 * a.l1_weight
with tf.name_scope("discriminator_train"):
discrim_tvars = [var for var in tf.trainable_variables() if var.name.startswith("discriminator")]
discrim_optim = tf.train.AdamOptimizer(a.lr, a.beta1)
discrim_grads_and_vars = discrim_optim.compute_gradients(discrim_loss, var_list=discrim_tvars)
discrim_train = discrim_optim.apply_gradients(discrim_grads_and_vars)
with tf.name_scope("generator_train"):
with tf.control_dependencies([discrim_train]):
gen_tvars = [var for var in tf.trainable_variables() if var.name.startswith("generator")]
gen_optim = tf.train.AdamOptimizer(a.lr, a.beta1)
gen_grads_and_vars = gen_optim.compute_gradients(gen_loss, var_list=gen_tvars)
gen_train = gen_optim.apply_gradients(gen_grads_and_vars)
#这个函数用于更新参数,就是采用滑动平均的方法更新参数。
ema = tf.train.ExponentialMovingAverage(decay=0.99)
update_losses = ema.apply([discrim_loss, gen_loss_GAN, gen_loss_L1])
global_step = tf.train.get_or_create_global_step()
incr_global_step = tf.assign(global_step, global_step+1)
#返回各种数据
return Model(
predict_real=predict_real,
predict_fake=predict_fake,
discrim_loss=ema.average(discrim_loss),
discrim_grads_and_vars=discrim_grads_and_vars,
gen_loss_GAN=ema.average(gen_loss_GAN),
gen_loss_L1=ema.average(gen_loss_L1),
gen_grads_and_vars=gen_grads_and_vars,
outputs=outputs,
train=tf.group(update_losses, incr_global_step, gen_train),
)论文实验重现详细记录
pix2pix
运行代码的时候出现这个问题:

这是因为作者的代码是基于比较高的tensorflow版本完成的,解决的方法有两个:

最终成功运行:
部分实验结果如下:
epoch=200的部分结果:训练了约4个小时
epoch=400的部分结果:训练了约8个小时

zi2zi
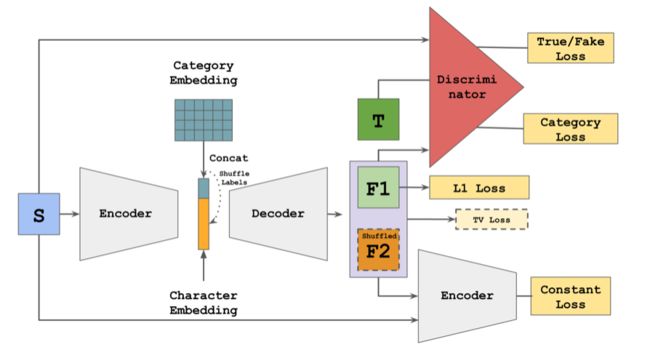
Github上有另一个比较有趣的项目,是字体风格化的转变,在认真学习完GAN之后我再去看了一遍,zi2zi的网络结构是从pix2pix继承下来的(加入了Category Embedding部分,这个部分是从Google的一篇关于语言翻译的文章中得到的灵感):
我再次运行了一下代码,得到如下结果(奇数列是ground truth,偶数列是得到的结果):



可见GAN确实强大