
作者简介

柴 树 杉
青云QingCloud应用平台研发工程师,开源的多云应用管理平台OpenPitrix开发者,Go 语言代码的贡献者,《Go 语言圣经》翻译者,《Go 语言高级编程》开源免费图书作者。2010年开始参与和组织 Go 语言早期文档翻译,2013年正式转向Go语言开发,CGO资深用户。
目
录
1. CGO的价值
2. 快速入门
3. 类型转换
4. 函数调用
5. CGO内部机制
6. 实践:包装 c.qsort
7. 内存模型
8. Go和C++对象
背景
在2017年年底初步完成了《Go 语言高级编程》的第二章 CGO 编程部分。当时刚好 GopherChina2018 在招聘讲师,我就找谢孟军申请了 CGO 的分享主题。选择 CGO 作为分享主题的原因有二:一是国内外对 CGO 编程的分享主题比较少;二是我想借此机会重新将 CGO 编程的部分的内容彻底梳理一次。第一次分享 CGO 主题是在2011年深圳的珠三角技术沙龙,这是可能是最后一次分享 CGO 的主题,我希望将 CGO 的问题彻底画上一个句号。
CGO 的幻灯片和《Go 语言高级编程》的第二章CGO编程部分基本是一一对应的,因此对于一个分享来说内容就太多了。因为时间的关系,现场分享时只保留了基础和重要的快速入门、类型转换、函数、内存模型等部分。不过这个 ppt的内容已经开源,感兴趣的同学可以直接查看,也可以将《Go 语言高级编程》的 CGO 章节内容作为参考。
《Go语言高级编程》第二章 CGO 编程:
https://github.com/chai2010/advanced-go-programming-book
1.CGO的价值
1. 没有银弹,Go 也不是银弹,无法解决全部问题
2. 通过 CGO 可以继承 C/C++ 将近半个世纪的软件积累,站在巨人的肩膀之上
3. 通过可以用 CGO 可以用 Go 给其他系统写 C 接口的共享库
4. CGO 是 Go 给其他语言直接通讯的桥梁
CGO 是一个保底的后备技术。
可能的 CGO 场景:
2.快速入门
其实 CGO 程序可以非常简单:只要包含一个 import“C” 语句就表示已经启用CGO。当然这这种程序没有多少实际用途。
下是相对简单一点的 CGO 程序:通过 C 语言的输出函数puts输出一段信息。
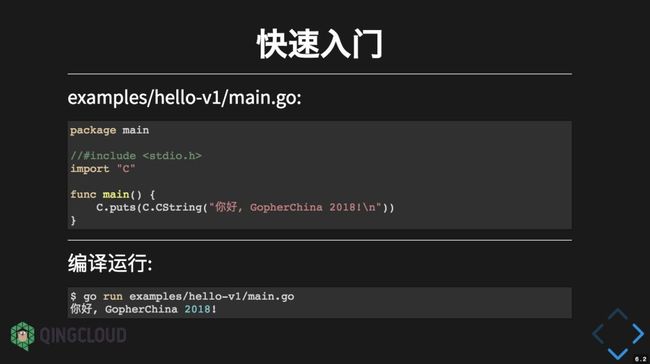
在 import “C" 语句前面增加来语句,通过包含这个头文件,我们可以使用 C 语言的 C.puts 函数实现输出字符串的功能。然后输入 go run main.go 命令就执行就可以执行该 CGO 程序了。当然,构建 CGO 程序的一个前提是要安装 GCC 编译器。
1.1 调用自定义的C函数

刚才是使用 puts 输出字符串,现在可以前进一步:通过自定义的函数实现输出。我们同样在 import "C" 语句之前的注释里面实现自定义的 Sayhello 函数。调用自己定义的函数实现某些功能,这是任何编程语言学习过程中非常重要的一个阶段。
1.2 C代码模块化

模块化是一种重要的编程方法。当程序中的一行语句太长的时候,我们希望将代码拆分为多行;当代码语句多到一定层度,我们就会将代码拆分为函数;如果一个文件中的函数太多,则希望将函数拆分到多个文件中重新组织。以上这些都是采用模块化的思路来简化代码的组织。
对于前面的 SayHello 函数,我们也可以采用模块化的测试来重新组织。首选创建一个 hello.h 头文件,里面包含 SayHello 函数的声明。然后将 SayHello 函数的实现放到 hello.c 文件中。在 CGO 代码中,就可以通过 #include "hello.h" 的方式直接引用 SayHello 函数。
1.3 Go 语言实现 C 模块
创建 hello.h 头文件是模块化编程的一个重要里程碑。对于 SayHello 函数的用户来说,我们只需要知道 SayHello 函数满足 C 语言函数的调用规约即可。至于SayHello 函数是采用 C 语言或 C++ 语言、甚至是其它任何语言实现的,对于SayHello 函数的用户并没有区别。因此,我们可以该 Go 语言重新实现SayHello 函数。
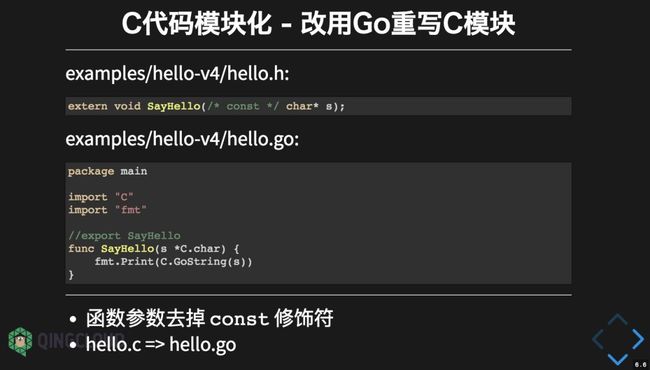
hello.h 头文件包含 SyaHello 函数声明,但是 hello.c 变成了 hello.go,函数本身从 C 语言实现改成了用 Go 语言实现。Go 语言实现的函数和 C 语言版本的函数名字和参数类型几乎是完全一致的(Go 导出的 C 函数不支持 const 修饰),因此对于 SayHello 函数的用户来说并没有太多的差异。现在可以说我是采用 C 语言思维编程的 Go 语言码农。
1.4 手中无剑,心中有剑
在模块化的基础上,我们采用 Go 重新实现了 C 语言规格的 SayHello 函数。现在我们可以尝试打破模块化编程的思路:删除 hello.h 头文件,将全部的 CGO 代码统一到一个 Go 源文件中:
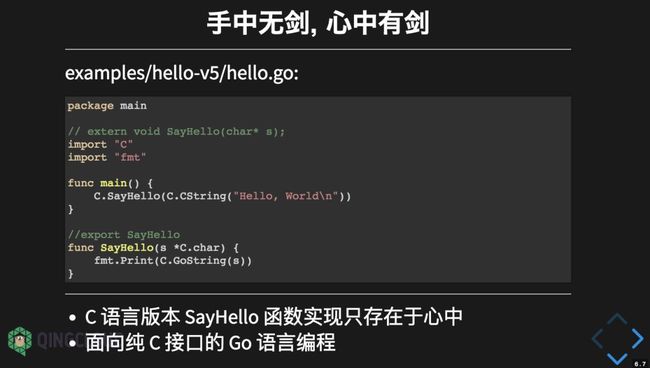
这时候虽然没有了头文件的函数声明,但是 SayHello 函数的声明在我们 Go 语言码农的心中。我们通过 extern 的方式在 CGO 中手工声明 SayHello 函数。然后在 main 函数中调用一个目前还不真是存在的 SayHello 函数进行字符串输出。这个例子其实90%以上是 Go 语言代码,但是编程的思维是 C 语言。
1.5 忘掉心中之剑
前面的实现中,虽然手中无剑,但是心中有剑:在导出 SayHello 函数时,依然采用了 C 语言的字符串格式。为此,在输出 Go 语言字符串时,需要先转换为C 语言格式的字符串;然后在 Go 语言中输出 C 语言字符串时,有需要转回 Go语言字符串;最后还需要释放中间临时创建的 C 语言字符串。这是心中编程思维被 C 语言字符串固化的结果。
我们需要忘掉 C 语言原有的字符串结构:其实从 C 语言角度看来,Go 语言字符串也是一种特殊格式的字符串。
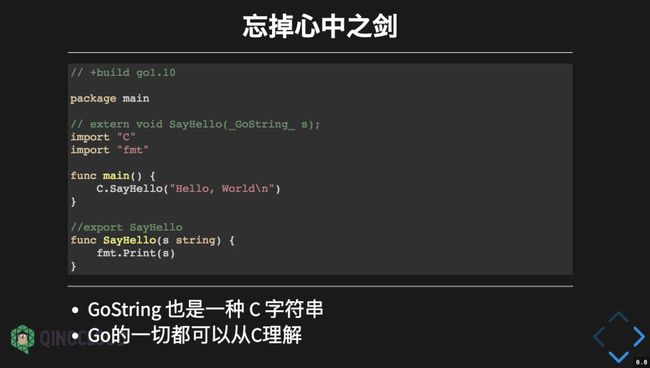
新的实现采用 Go 语言格式的字符串作为 SayHello 函数的参数,中间将不再有额外的字符串转换的开销。
思考题:main 函数和 SayHello 函数是否是运行在同一个 Goroutine?
3.类型转换

有些编程语言的教程中将“数据结构+算法”作为程序的定义。数据结构对应一切变量和变量对应的结构化数据,算法可以近似看作是函数的内在逻辑。因此如何解决不同类型变量之间的数据转换是第一个要解决的问题。
在 C 语言中,对不同类型之间的转换相当灵活,甚至普通整数和函数指针也可以自由直接转换。但是 Go 则对不同类型之间的转换有着非常严格的限制。指针是 C 语言的核心类型,因此 CGO 中围绕指针周边的类型转换也是第一个要解决的问题。
为此 Go 语言提供了一个 unsafe 包,用于提供不安全的类型转换。其实 unsafe包是一个非常安全的包,但是前提是你要彻底理解 unsafe 操作底层的含义。如果离开了 unsafe 包,CGO 编程将寸步难行!
CGO 编程中会涉及到 Go 指针和 C 指针之间的转换,还有数值类型和指针之间的转换。不同类型的指针转换,字符串和切片的转换,基本上主要布局在指针类型、数值类型,字符串和切片。
3.1 指针- unsafe包的灵魂

指针是 C 语言的灵魂,自然也是 unsafe 包的灵魂。unsafe.Pointer 对应 C 语言的 void 类型指针,是 GC 垃圾回收器要管理的对象;uintptr 则是数值化的指针,并不参与 GC 的管理。在 C 语言中 uintptr 和指针并无太大差异,但是在Go 语言中二者确实完全不同的类型。因为 Go 语言的指针可能会因为栈的伸缩而被移动,移动时 GC 会自动维护指针的变化,uintptr 类型的变量将无法实现指针被移动时的自动更新。
3.2 unsafe 包


unsafe 包的每个用法在 C/C++ 语言中都有对应的特性,熟悉 C 语言的用户应该比较容易理解。
3.3 Go 字符串和切片的结构

Go 语言和 C 语言是不同的语言,CGO 是二者连接的桥梁。CGO 也可以实现两者的数据共享,底层的基础正是扁平化的内存。因此有着扁平化内存结构的Go 字符串和 Go 字节切片将是 CGO 中需要频繁处理的类型。字符串和切片的结构在 reflect.StringHeader 和 reflect.SliceHeader 定义,CGO 中会生成对应的 C 语言结构体。
GoString 和 GoSlice 和头部结构是兼容的。这样可以保证字符串和切片是兼容的,如果一个字符串转成切片或者反向转过来,某种优化的时候就是一个指针加一个长度。
3.4 实践:int32 和 C.char 指针相互转换
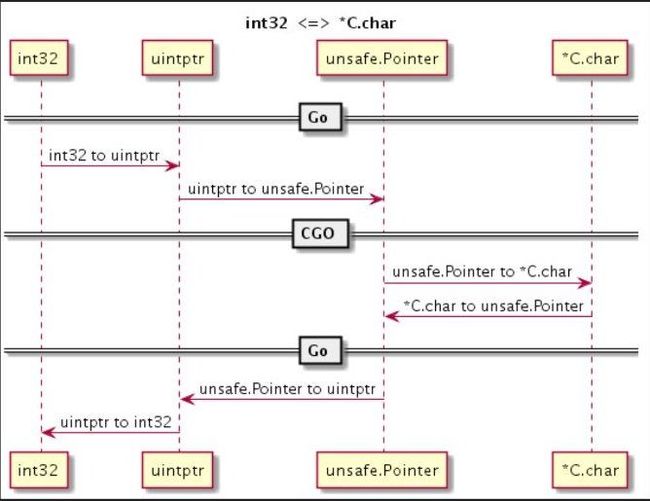
第一种是普通整数类型到指针类型的转换。中间需要数值化的指针类型 unitptr 和通用指针类型 unsafe.Pointer 作为转换中介。基于这个技术,就可以实现任何数值类型到任何指针类型的强制转换。
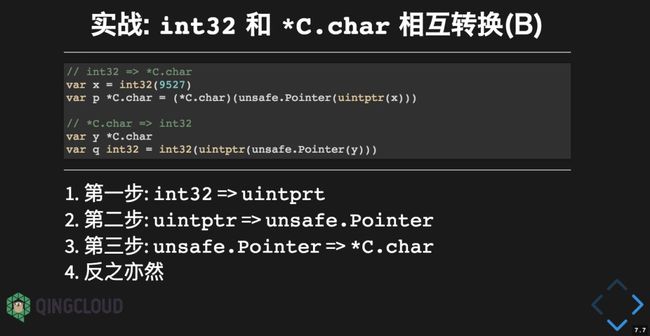
这个代码主要是刚才图的描述。
3.5 X 和 Y 的相互转换

然后是X*和Y*相互转换比较简单,通过 unsafe.Pointer 做中介就可以达成转换。

这个是P到Q的转换,然后可以转成X*和Y*。
3.6 [ ]X 和 [ ]Y 的相互转换

不同类型的切片之间的转换则比较复杂。因为切片是值类型,我们无法对两个不同的值类型对象做转换,因为两个类型在内存的大小可能并不相同。

转换不同的值类型的第一步是将值类型转为指针类型(因为任何类型的指针大小是相同的)。对于切片来说,通过 PX 和 PY 转换为两个指向不同切片类型的指针,切片指针的底层结构都是对应同一个 reflect.SliceHeader 类型。然后通过指针实现不同类型切片头部的复制,就是实现了 X 和 Y 切片的转换。
3.7 实例:float64 数组排序优化

比如要对正规的 float64 数组就行排序。如果CPU没有浮点运算的指令,我们可以将 float64 切片作为 int64 切片来排序(可能会快一点)。具体的原理是:float64 是遵循 IEEE754 标准的浮点数,当浮点数有序时作为整数也是有序的(不考虑非数和正负0的问题)。
在 AMD64 平台,我们用前面的技术将 [ ]float64 转为 [ ]int,然后就可以用sort.Int 对浮点数进行排序了。
4.函数调用
在准备好正确类型的参数之后,函数调用本身的语法比较简单,因为底层繁琐的细节已经由 CGO 处理掉了。函数调用有2个方向:最常见的是 Go 调用 C 函数,然后是 C 函数回调 Go 函数,以及这两种调用的相互嵌套。
4.1 Go调用C函数

Go 调用 C 是通过一个虚拟的C包访问,最终 C.add 会被转为 _Cfunc_add 调用。隐含的推论是 C 包的全部 Go 符号都是私有的,只有在当前包可以访问。因此在不同的 Go 包之间的函数调用中,如果出现 C 包符号跨越构造,基本是无法编译通过的(因为是各自包的私有类型,无法共享)。
C 函数最多只能返回一个值。但是 CGO 中的 C 函数,可以返回两个值:

C 语言标准库有个 errno 全局变量(好像是每个线程一个),用于保存错误状态。因此 C 语言函数的错误状态是用这个全局的 errno 变量返回的(因为 C 函数只能有一个返回值)。为了简化 errno 的读取,CGO 可以将 errno 作为第二个返回值返回。

这个例子中 seterrno 将参数保存到 errno,然后用第二个返回值返回了。第二个返回值虽然是一个 error 接口类型,但是底层其实对应的是 syscall.Errno 类型。
因为有第二个返回值这个奇怪的特性,我们甚至获取一个 void 类型的 C 函数的返回值:

这个 seterrno 的函数是返回 void 类型,但是作为 CGO 来说,第一个返回值是一个占位,虽然是空的,但是可以拿出来。通过这种方式,我们可以查看 void 在CGO 中对应的 Go 实现:内部对应 type_ctype_void [0] byte 类型,这是一个内存大小为0的类型。
虽然没有什么实际用途,但是可以加深对CGO底层实现的理解。
4.2 导出Go 函数
正因为 Go 函数可以导出为 C 函数,CGO 生态才真正地实现了闭环。正如毛主席的群众路线所言:CGO 让 Go 码农从 C 语言中来,也可以回到 C 语言中去。

Go 语言导出 C 函数很简单,通过 export 注释导出 add。要注意的是,导出 C函数的名字要和 Go 函数的名字保持一致,同时函数的参数和返回值类型要尽量采用 C 语言类型。
CGO会 生成一个 _cgo_export.h 头文件,通过该函数就可以引用导出的 C 函数:

虽然使用自动生成的_cgo_export.h 文件会比较简单,但是我们并不推荐这样做。其实我们完全可以先给要导出的函数创建头文件(先设计 API,然后才是API 的实现),也就是在快速入门章节建议的先定义 C 函数接口。然后才是用Go 语言实现了自定义的 C 头文件夹定义的 C 函数。
目前我们可以简单声明导出的函数就可以使用了:

割断对_cgo_export.h 文件的依赖还有一个好处:可以摆脱对 CGO 文件的依赖。最小化依然是每个 C 程序员都要追求的目标,因为这可以极大减少编译时的各自问题。
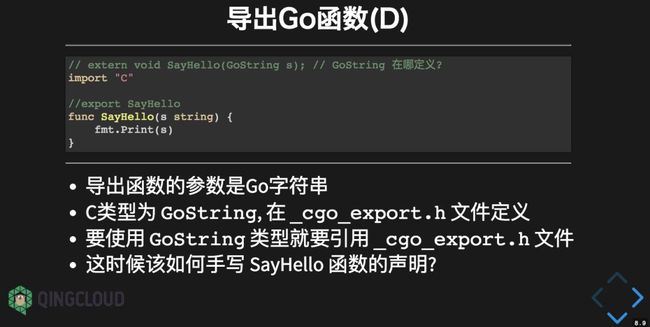
但是这个例子比较特殊,导出 C 函数的参数是 Go 语言字符串类型,在 C 语言中对应的 GoString 类型在_cgo_export.h 文件定义。如果依赖_cgo_export.h 文件,那么间接导致对自身的依赖,也就是出现了环形依赖。
解决的一个办法是通过拆分文件,将 SayHello 函数的定义和使用放到不同的Go 文件中。但是对于这个小小的程序来说,拆分为多个文件就有点小题大做了。
我们不是一个人在战斗,因为世界上也有其它的 Gopher 遇到了同样的问题。因此,Go1.10 新增加了一种_GoString_ 预定义的类型,可用于摆脱为_cgo_export.h 文件的依赖:

这样我们就可以不拆分文件构造一个闭环使用的 CGO 例子。
5.Go 内部机制
cgo会生成很多中间文件,而理清中间文件的类型是理解 cgo 工作的第一步。
5.1 CGO生成的中间文件
每个 CGO文 件会展开为一个 Go 文件和 C 文件,分别以 .cgo1.go和.cgo2.c 为后缀名。

然后 _cgo_gotypes.go 对应 C 导入到 Go 语言中相关函数或变量的桥接代码。而_cgo_export.h 对应导出的 Go 函数和类型,_cgo_export.c 对应相关包装代码的实现。
5.2 内部调用流程 Go->C
先构造一个最简单的调用 C 函数的例子:

虽然 CGO 代码看起来简单,但是内部实现非常复杂,下面是 C.sun 函数详细的调用流程:
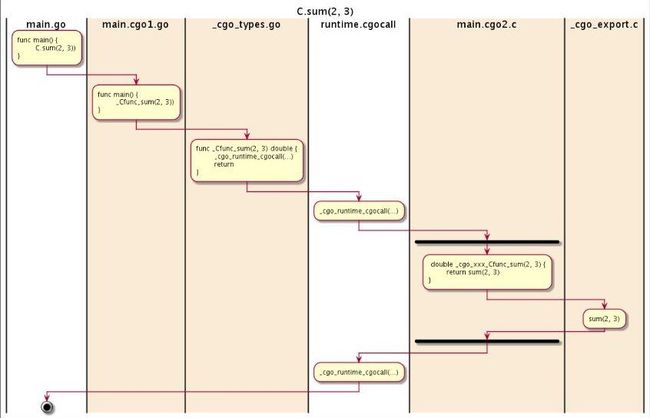
白色的部分,是我们自己写的代码,黄色部分是 CGO 生成的代码,左边两列浅黄色是 Go 语言的空间,右边就是 C 语言运行空间。在中间位置出现了两个黑的横杠隔开了,黑的横杠中间为 C 语言运行空间。
5.3 内部调用流程:C->Go
构造一个 Go 导出 C 函数的例子:

内存调用流程:

对应的函数调用流程图:

途中的细节我们不再赘述,感兴趣的同学可以自行研究。
6.实践:包装 C.qsort

因为时间关系就不展开 qsort 这个例子了,对 CGO 感兴趣的同学可以挑战一下。基于 C 语言的 qsort 函数包装出一个类似标准库中 sort.Slice 的函数来。
相关的细节可以参考 ppt 或《Go 语言高级编程》的第二章对应章节。
7.内存模型
前面讲述的语法部分是属于 CGO 的招式,招式出问题编译器就可以马上纠正。而内存模型则是 CGO 的内功,如果运行时内存出现问题则是大问题,编译器是无法提前发现的。
7.1 结构体对齐

为何有结构体对齐这个问题呢?这是 CPU 对基础类型有对齐要求,只有对齐的数据才能提高效率,甚至是只有对齐的数据才能产生正确的结果。一个原则:结构体数组的每个元素的每个成员必须对齐。
如果 C 代码中没有涉及结构体对齐部分,则可以忽略该内容。

这个左边是32体位的对齐,右边是64位的。
7.2 堆和栈

堆和栈是目前程序的约定概念。Go 语言中虽然有堆有栈,但是我们不知道在哪里。
Go 语言的堆在哪里,不知道,栈在哪里也不知道。函数局部变量是在栈上还是堆上也不知道。甚至 Go 语言的规范中都没有提到堆和栈这种概念!

C语言用户第一次看到 getv 函数,会觉得是一个 BUG:将栈上的变量地址返回了,而函数返回后栈地址将失效!但是,Go 语言并不是C语言,拿C语言的标准来分析 Go 语言的程序显然是不合理的。这和九品芝麻官中拿前朝的上方宝剑来斩今朝的官是一样的可笑。
在 Go 语言中,如果一个变量需要在堆上,那么它就是在堆上;如果一个变量在栈上更好,那么它也可以在栈上。
7.3 GC/动态栈有何影响


动态栈是 Go 语言的特色:不用担心深度递归的函数调用不会爆栈。但是动态内存的代价是(Go1.4+),每个函数的入口需要增加是否增长栈的代码(性能要满一点点);同时栈的移动导致栈上变量地址变化,需要同步更新栈指针,也导致了无法将 Go 对象的指针直接传入C函数(假设内存没有被回收)。
7.4 顺序一致性内存模型

顺序一致性内存模型主要和并发编程有关系,和 CGO 的交集并不多,这里不再展开。
7.5 CGO 指针的使用原则

7.6 C内存到Go 内存


C内存分配后就不会变化,传入Go语言空间后可以放心使用。
7.7 Go 内存临时到c内存

临时作为参数传入C函数的Go内存,在C函数返回前有效,此时Go运行时会锁定被引用的Go内存。但是任何好处都是有代价的,如果C函数1个小时不返回,那么调用C函数的Goroutine将被彻底锁定。
7.8 C长期持有 Go 内存
C中无法长期持有 Go 内存:因为 Go 内存指针可能会发生变化,而 GC 无法管理被C持有的 Go 指针。一个折中的办法是在 Go 语言空间将易变的指针绑定一个不变而且唯一的整数变量ID。


当指针不再需要时,直接释放ID对应的指针资源:
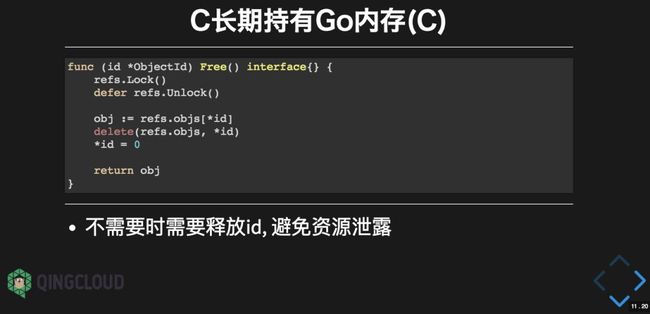
而在导出的C语言函数参数中,可以将ID直接当作指针类型。只是在使用ID类型的指针前,需要将ID解包为真正的 Go 指针。

通过这种方法,可以将 Go 对象指针传入任何语言中引用。
8.Go访问C++对象,Go对象导出为C++对象
因为时间关系,Go 访问 C++对象我就不展开了,都是前面理论的延伸。把 C++转成C接口,通过 Go来 访问 C++对象,反过来就是 Go 对象导出为 C++对象展开成全局的 Go 函数,导出为C语言函数,再把C语言函数包装成 C++对象。
给大家看一个比较有意思的 C++用法,叫还我自由的 C++指针:

如果你是 Go 语言用户,看到这个代码会有似曾相识的感觉。这个 C++类没有成员,我定义了普通整数x,在使用x的时候,强制转移成自定义的Int类型,调用 Twice 方法。
这里的核心技巧是我们手工构造了 this 参数。这正是 Go 语言中方法函数的核心:我们的 Twice 方法也是绑定到了 Int 类型之上。C++语言的一个限制是 this被固化为了指针类型,对于原始对象的大小和指针大小不同,则必须通过指针类型中转。而 Go 语言则是将 this 提取出来,作为一个普通的参数,用户可以根据需要随意选择 this 参数的类型。
如果在手工构造 this 的基础上再进一步,那就是在运行时动态构造 C++的虚表,这也是 Go 语言中 interface 的做法。