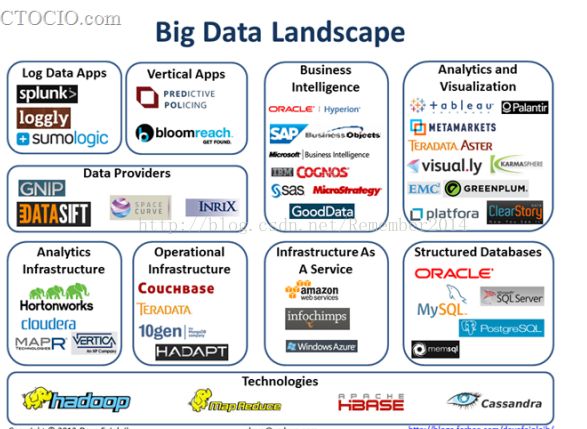
1、认识大数据
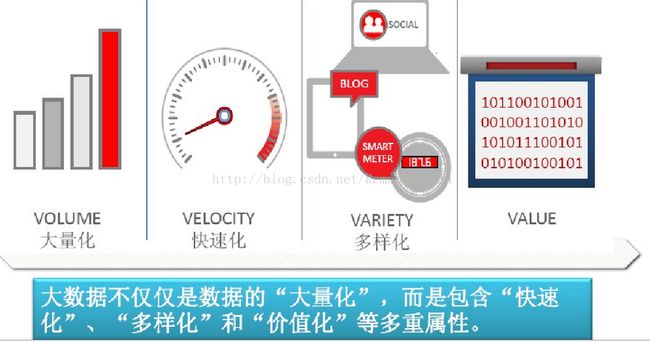
大数据技术的战略意义不在于掌握庞大的数据量,而在于对这些数据进行专业化处理。
数据一直都在以每年50%的速度增长,也就是说每两年就增长一倍。
大数据是由结构化和非结构化数据组成的
– 10%的结构化数据,存储在数据库中
– 90%的非结构化数据,它们与人类信息密切相关
数据结构(参阅c语言数据结构)
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,良好的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
1、结构化数据即行数据,存储在数据库里,可以用二维表(行列形式)结构来逻辑表达实现的数据
2、非结构化数据库主要是针对非结构化数据而产生的,与以往流行的关系数据库相比,其最大区别在于它突破了关系数据库结构定义不易改变和数据定长的限制,支持重复字段、子字段以及变长字段,在处理连续信息(包括全文信息)和非结构化信息(包括各种多媒体信息)中有着传统关系型数据库所无法比拟的优势。非结构化数据(全文文本、图象、声音、影视、超媒体等信息)。
3、半结构化数据,就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。
数据模型:
结构化数据:二维表(关系型)
半结构化数据:树、图
非结构化数据:无
舍恩伯格的《大数据时代》描述大数据的三个特征:
( 1}全样而非抽样;
( 2)效率而非精确;
( 3)相关而非因果。
数据容量单位:
1 Byte= 8 bit
1 KB = 1,024 Bytes
1 MB = 1,024 KB = 1,048,576 Bytes
1 GB = 1,024 MB = 1,048,576 KB
1 TB = 1,024 GB = 1,048,576 MB
1 PB = 1,024 TB = 1,048,576 GB
1 EB = 1,024 PB = 1,048,576 TB
1 ZB = 1,024 EB = 1,048,576 PB
1 YB = 1,024 ZB = 1,048,576 EB
1 BB = 1,024 YB = 1,048,576 ZB
1 NB = 1,024 BB = 1,048,576 YB
1 DB = 1,024 NB = 1,048,576 BB
大数据与大规模数据、海量数据的差别
从对象角度看,大数据是大小超出典型数据库软件采集、储存、管理和分析等能力的数据集合。大数据并非大量数据的简单无意义的堆积,数据量大并不意味着一定具有可观的利用前景。数据间是否具有结构性和关联性,是 “大数据”与“大规模数据”的重要差别。
从技术角度看,大数据技术是从各种各样类型的大数据中,快速获得有价值信息的技术及其集成。“大数据”与“大规模数据”、“海量数据”等类似概念间的最大区别,就在于“大数据”这一概念中包含着对数据对象的处理行为。为了能够完成这一行为,从大数据对象中快速挖掘更多有价值的信息,使大数据“活起来”,就需要综合运用灵活的、多学科的方法,包括数据聚类、数据挖掘、分布式处理等,而这就需要拥有对各类技术、各类软硬件的集成应用能力。可见,大数据技术是使大数据中所蕴含的价值得以发掘和展现的重要工具。
从应用角度看,大数据是对特定的大数据集合、集成应用大数据技术、获得有价值信息的行为。正由于与具体应用紧密联系,甚至是一对一的联系,才使得“应用”成为大数据不可或缺的内涵之一。
大数据与云计算
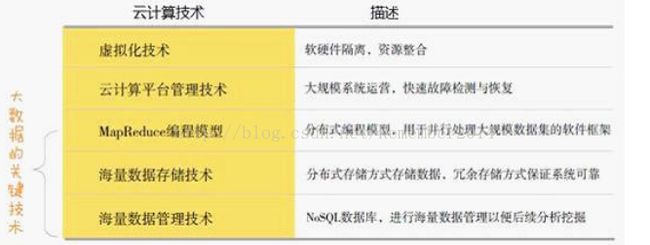
云计算关键技术中的海量数据存储技术、海量数据管理技术、MapReduce编程模型,都是大数据技术的基础。
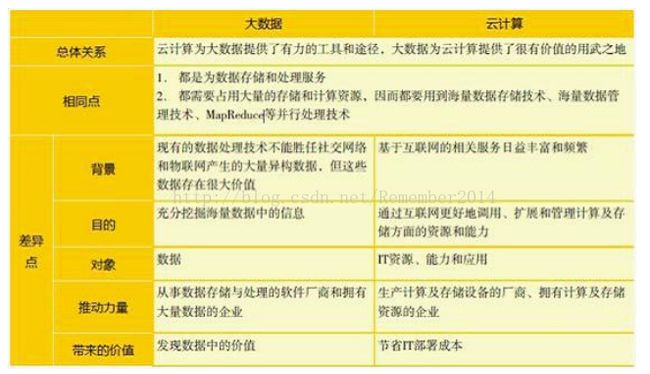
大数据技术与云计算有相同,也有差异
大数据与物联网
物联网就是“物物相连的互联网”。物联网通过智能感知、识别技术与普适计算、泛在网络的融合应用,被称为继计算机、互联网之后世界信息产业发展的第三次浪潮
• 物联网架构可分为三层,包括感知层、网络层和应用层
• 物联网,移动互联网再加上传统互联网,每天都在产生海量数据,而大数据又通过云计算的形式,将这些数据筛选处理分析,提取出有用的信息,这就是大数据分析。
大数据存储和管理技术
主要包括分布式缓存、基于MPP的分布式数据库、分布式文件系统、各种NoSQL分布式存储方案等
分布式缓存使用CARP( Caching Array Routing Protocol)技术,可以产生一种高效率无接缝式的缓存,使用上让多台缓存服务器形同一台,并且不会造成数据重复存放的情况。分布式缓存提供的数据内存缓存可以分布于大量单独的物理机器中。换句话说,分布式缓存所管理的机器实际上就是一个集群。它负责维护集群中成员列表的更新,并负责执行各种操作,比如说在集群成员发生故障时执行故障转移,以及在机器重新加入集群时执行故障恢复。
分布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都有DBMS的一份完整拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的大型数据库。
Spanner是一个可扩展、多版本、全球分布式并支持同步复制的分布式数据库。它是Google的第一个可以全球扩展并且支持外部一致性事务的分布式数据库。 Spanner能做到这些,离不开一个用GPS和原子钟实现的时间API。这个API能将数据中心之间的时间同步精确到10ms以内。因此, Spanner有几个给力的功能:无锁读事务、 原子模式修改、读历史数据无阻塞。
分布式文件系统,不得不提的是Google的GFS。基于大量安装有Linux操作系统的普通PC构成的集群系统,整个集群系统由一台 Master(通常有几台备份)和若干台TrunkServer构成。 GFS中文件被分成固定大小的Trunk分别存储在不同的TrunkServer 上,每个Trunk有多份(通常为3份)拷贝,也存储在不同的TrunkServer上。 Master负责维护GFS中的 Metadata,即文件名及其Trunk信息。客户端先从Master上得到文件的Metadata,根据要读取的数据在文件中的位置与相应的 TrunkServer通信,获取文件数据。
NoSQL数据库,指的是非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
现今的计算机体系结构在数据存储方面要求具备庞大的水平扩展性(horizontal scalability,是指能够连接多个软硬件的特性,这样可以将多个服务器从逻辑上看成一个实体),而NoSQL致力于改变这一现状。目前Google的 BigTable 和Amazon 的Dynamo使用的就是NoSQL型数据库。