Hive——基于Hadoop的数据仓库概念
- Hive的元数据
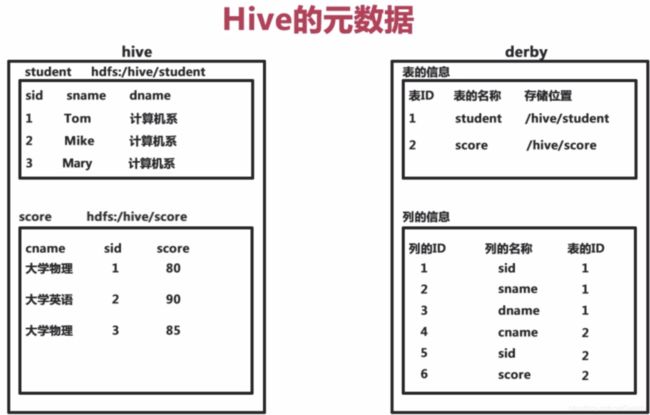
Hive将元数据存储在数据库中,支持mysql。Hive中的元数据包括表的名字、表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录。Hive中的表实际上就是HDFS中的一个目录或者文件。
- Hive中HQL的执行过程
Hive驱动:解析器(词法分析)和、编译器(生成执行计划)和优化器(生成最佳执行计划)完成HQL查询语句从词法分析、语法分析、编译与优化以及查询计划(Plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hive的安装模式
嵌入模式:元数据被存储在Hive自带的Derby数据库中,只允许创建一个连接,多用于Demo
本地模式:元数据被存储在MySQL数据库中,MySQL与Hive运行在同一个物理系统
远程模式:元数据被存储在MySQL数据库中,MySQL与Hive运行在不同的物理系统中
在安装路径的bin路径下输入./hive命令就可以创建Derby数据库且进入hive 的命令行格式。在某个目录下调用hive命令(添加classpath之后)就会在当前目录下创建一个Derby数据库。
- Hive的管理
CLI(命令行方式):直接输入hive(已配置classpath)或者输入hive --service cli hive -S 进入静默模式,没有调试信息显示
hive -e '操作语句' 可以不进入hive命令行模式
用quit;或者exit;
// 查看数据仓库中的表
show tables;
// 查看数据仓库中内置的函数
show functions;
-- cli中表示后面的文字为注释
// 查看表的结构
desc 表名
// 也可以使用hdfs的命令
dfs -ls 目录
// 执行linux命令
!命令
// 执行HQL语句
select *** from ***
// 执行SQL脚本
source 文件.sql
Web界面方式:启动方式: hive --service hwi & 端口号9999 通过浏览器http://
###################Web界面方式未完成 需重新看视频配置
远程服务启动方式:hive --service hiveserver & 端口号10000
- Hive的数据类型(建表)
基本数据类型: varchar(20)是最大20可以不满20 char(20)是所有的都为20
复杂数据类型:Array Map Struct
数组:array
集合:Map 包含key-value键值对,通过key来访问元素 map
也可以array
结构类型: struct
时间类型:Date Timestamp
Date和Timestamp的区别 可以用cast函数进行相互转换(官方API)
Date :YYYY-MM-DD
select unix_timestamp();可以得到当前时间戳的偏移量(长整型)
- Hive的数据存储
基于HDFS(HDFS中的txt文件或者csv数据对应于Hive中表的数据);在Hive中表没有专门的数据存储格式;存储结构主要包括数据库、文件、表和视图;可以直接加载文本文件(txt、csv等);创建表时,指定Hive数据的列分隔符与行分隔符,默认为制表符为列分隔符。
- Hive的数据模型
内部表(Table):与数据库中的table类似,每一个Table都在Hive中有一个相应的目录存储数据,所有的Table数据都保存在这个目录中;删除表时,元数据和数据都会被删除。
create table t1
(tid int, tname string, age int);
默认目录为/user/hive/warehouse
也可以更改目录
create table t1
(tid int, tname string, age int)
location '/mytable/hive';
也可以指明列与列之间的分隔符
//这样可以导入csv文件 (csv是用逗号作为分隔符的)
create table t1
(tid int, tname string, age int)
row format delimited fields terminated by ',';
可以用查询语句结果来创建表
create table t1
as
select *from sample_data; 这样创建的数据是没有分隔符的
create table t1
row format delimited fields terminated by ','
as
select *from sample_data; 这样创建的数据是没有分隔符的
添加列
alter table t1 add columns(gender string);
修改列名和属性可以查询文档
删除表 移入了HDFS的回收站
drop table t1;分区表(Partition)
Partition对应于数据库的Partition列的密集索引,在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。提高查询的效率。 用explain+语句可以查看执行计划。
创建分区表
create table partition_table
(sid int, sname string)
partitioned by (gender string)
插入到分区表
insert into table partition_table partition(gender='M') select sid,sname from t1 where gender='M';
外部表(External Table)
指向已经在HDFS中存在的数据,可以创建Partition;和内部表在元数据的组织上是相同的,但实际数据的存储则有较大差异,外部表只有一个过程,加载数据和创建表同时完成(内部表是先创建再加载),并不会移动到数据仓库目录中,只是与外部数据建立一个连接,删除表的时候只是删除连接。
创建外部表
create external table external_student
(sid int, sname string)
location '/input'桶表(Bucket Table):对数据进行哈希取值,然后放到不同的文件中存储。
创建桶表
create table bucket_table
(sid int, sname string)
clustered by(sname) into 5 buckets;
以sname进行哈希取值,放入5个桶里视图(View):是一种虚表,是一种逻辑概念,可以跨越多张表。视图建立在已有表的基础上,视图赖以建立的表成为基表,可以简化复杂的查询。感觉相当于联合查询??
创建视图
create view empinfo
as
select e.empno, e.ename, e.sal*12 annlsal, d.dname
from emp e, dept d
where e.deptno = d.deptno;