论文浅尝 | 基于知识库的自然语言理解 03#
本文转载自公众号: 知识工场。
罗康琦,上海交通大学计算机系2019届博士,研究方向为自然语义理解和知识图谱。2012年获得华中科技大学软件工程学士学位,现就职于京东数据科学实验室(Data Science Lab)。他曾在AAAI,IJCAI,EMNLP等国际顶级会议上发表多篇论文。
本章的研究中,我们关注从海量纯文本数据中挖掘出的关系三元组。二元关系是一个三元组的语义核心,它扮演谓语的成分,描述了主语和宾语实体间具有的特定联系。 然而,由于关系具有多义性,以及知识库与自然语言间存在的语义间隔,我们很难直接像实体理解那样,建立关系和知识库谓词的一一对应。因此,我们尝试从多个角度出发,寻找关系与知识库之间存在的复杂匹配。
4.1 关系的主宾语类型搭配挖掘
这一节的研究中,我们旨在寻找不同关系连接的实体所具有的类型偏好,并利用知识库中的实体信息构建丰富的类型层次关系,从而挖掘具有代表性的(主语,宾语)类型搭配,在粗粒度上展现关系的不同含义。
4.1.1 引言
开放式信息抽取( Open Information Extraction )任务的目标是从从开放领域的文本语料库中挖掘命名实体或概念,并抽取出连接这些实体的各种不同的自然语言关系。之所以称为开放式抽取,是因为要挖掘的关系不局限于特定领域也不基于固定的匹配规则。学术界中,较为先进的开放式信息抽取系统[1-4]可以从海量互联网语料库中,以很高的准确率提取百万甚至更高级别数量的关系实例,(  ,
, 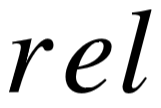 ,
, 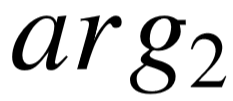 )三元组形式,我们将其称为关系三元组。其中, 为二元关系,一般表示为短语(词级别描述)或依存 语法路径(语法级别描述)。 和 是关系的两个参数,即主语和宾语,同样表现为短语形式。
)三元组形式,我们将其称为关系三元组。其中, 为二元关系,一般表示为短语(词级别描述)或依存 语法路径(语法级别描述)。 和 是关系的两个参数,即主语和宾语,同样表现为短语形式。
开放式信息抽取提供给我们海量关系实例的同时,我们有兴趣将这些实例进行归纳,寻找更加抽象的语义表示。我们关注的重点就是这些关系所具有的不同含义。以关系 “play in” 为例,开放式信息抽取系统可以提供一系列具有 (  , play in,
, play in, ) 形式的三元组。例如 ReVerb 系统[2] 可抽取出三元组 ( Goel Grey, played in, Cabaret ) 以及( Tom Brady, play in, National Football League )。给定某关系已有的三元组实例,我们可以推理 出一系列由类型三元组描述的关系模式,即主宾语类型搭配(
) 形式的三元组。例如 ReVerb 系统[2] 可抽取出三元组 ( Goel Grey, played in, Cabaret ) 以及( Tom Brady, play in, National Football League )。给定某关系已有的三元组实例,我们可以推理 出一系列由类型三元组描述的关系模式,即主宾语类型搭配(  ,playin,
,playin,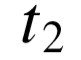 )。其中以及为标准化的实体类型,其来源为含有类型定义的知识库,例如 WordNet [5],Yago [117], Freebase [9] 以及 Probase [118]。每一个关系模式都可以用来表示一组特定的 “play in” 关系实例,其中主宾语分别属于对应的类型。对于上例“play in”,我们可以给出两个可能的模式:( film_actor, play in, film ),以及( pro_athlete, play in, sports_league )。由此可见,二元关系 “play in” 具有明显歧义,不仅可以描述 “运动员—体育联盟” 联系,还可以描述 “演员—电影” 之间的联系。对于歧义较少的关系,我们依然可以推理出不同的主宾语类型搭配,例如关系 “is the mayor of” 可以推理出 ( person, is the mayor of, location ), 以及( politician, is the mayor of, city )等不同模式,在类型上具有不同的粒度,后者显然更加具体。
)。其中以及为标准化的实体类型,其来源为含有类型定义的知识库,例如 WordNet [5],Yago [117], Freebase [9] 以及 Probase [118]。每一个关系模式都可以用来表示一组特定的 “play in” 关系实例,其中主宾语分别属于对应的类型。对于上例“play in”,我们可以给出两个可能的模式:( film_actor, play in, film ),以及( pro_athlete, play in, sports_league )。由此可见,二元关系 “play in” 具有明显歧义,不仅可以描述 “运动员—体育联盟” 联系,还可以描述 “演员—电影” 之间的联系。对于歧义较少的关系,我们依然可以推理出不同的主宾语类型搭配,例如关系 “is the mayor of” 可以推理出 ( person, is the mayor of, location ), 以及( politician, is the mayor of, city )等不同模式,在类型上具有不同的粒度,后者显然更加具体。
对于自然语言理解任务,例如上下文相关的实体消歧,还有开放领域自动问答,关系模式是一个有用的信息。假设我们要对句子 “ Granger played in the NBA ” 进行实体识别。“ Granger ”对应一个人名,但由于只提供了姓氏,因此具有较高歧义。而“ the NBA ” 几乎可以确定是人们熟知的体育联盟。再结合上面列举的 “ play in ” 所具有的关系模式, 实体识别模型便可以获得额外特征,即“ Granger ”更有可能代表运动员,也就使得篮球运动员 “ Danny Granger ” 更容易被正确识别。考虑到这个实体并不非常著名,与之相关的关系实例数量可能较少,但类型特征依然可以提供很大的帮助。
为了生成关系模式,一种已有的方案是基于选择偏好(Selectional Preference)技术[119-121],它可以对关系中的主宾语实体计算各自具代表性的类型。选择偏好技术主要思路来自关系与类型之间的互信息计算[120],这种方式倾向于选择当前关系所独有的类型,换句话说,如果一个类型普遍适用于不同关系中的实体描述,那么它便不容易被选为代表类型。然而在开放式信息抽取中,很多关系实际上是相关的,甚至非常相近,例 如 “ play in ”,“ take part in ” 以及 “ is involved in ” 。这些关系实际上具有相同的语义,因此主宾语的类型搭配也应该相似,而选择偏好技术会因为关系的不同而对这些类型都进行弱化。
因此本章中,给定一个关系和一系列具体的三元组,我们的任务是寻找那些最具体的类型搭配,而同时包含尽可能多的关系实例。我们的方法首先将关系实例中的主宾语映射为知识库中的实体,即为每个三元组生成 ( 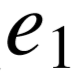 ,
, ) 实体对。接着根据不同实体所属 的类型,寻找可以覆盖尽可能多实体对的类型搭配(
) 实体对。接着根据不同实体所属 的类型,寻找可以覆盖尽可能多实体对的类型搭配( 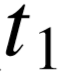 ,
,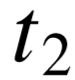 )。最后,当不同的类型搭配覆盖的实体对较为接近或一致时,我们利用知识库中已有的 IsA 关系,扩充知识库中类型之间的层次结构,以此寻找更加具体的类型搭配。
)。最后,当不同的类型搭配覆盖的实体对较为接近或一致时,我们利用知识库中已有的 IsA 关系,扩充知识库中类型之间的层次结构,以此寻找更加具体的类型搭配。
本章的贡献可以总结为以下三个部分:
1. 我们具体定义了基于开放式信息抽取的二元关系模式推理问题;
2. 我们设计了基于 Freebase 和实体链接任务的方法,对一类关系的主宾语所具有的类型分布进行联合建模;
3. 我们在 ReVerb 数据集上进行实验,根据人工标注的类型搭配结果,对不同二元关系生成的最佳模式进行测评。与传统选择偏好方法比较,我们的模型在 MRR 指标上得到了10%的相对提升。
4.1.2 我们的方法
二元关系模式挖掘的系统架构如图4–1所示。整个系统的输入为开放式信息抽取系统中的所有关系三元组,经过实体链接、关系分组以及模式排序三个步骤之后,这些三 元组将会转换为一系列排好序的主宾语类型搭配。每个步骤概括如下,本节将对它们进 行具体描述。
(1)实体链接: 关系三元组中的参数实体均为字符串形式。我们通过模糊字符串匹 配的方式,将主宾语分别映射到知识库中的不同实体。
(2)关系分组: 经过链接之后,关系表达形式相近的三元组将聚集在一起,形成一个大的分组。并且,每一个分组会从内部的不同关系中选择一个,作为整组的代表关系。
(3)关系模式排序: 对分组内的每一个具有链接的关系实例,其主宾语将转换为知识库中对应的类型。根据不同的类型搭配所覆盖的三元组数量,以及各个类型的宽泛或具体程度,对所有候选的关系模式进行排序并输出。
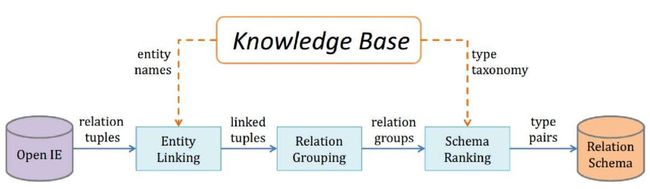
图4–1 二元关系模式挖掘的流程框图。
4.1.2.1 实体链接
在实体链接步骤中,一个关系三元组的主宾语将分别映射到知识库中的实体,形成 带链接的三元组( ,  , ),并配有对应的链接分值。由于每一个三元组所具有的信息较少,并没有提供足够的上下文,因此实体链接过程主要基于主宾语名称以及实体在知识库中名称的模糊匹配。
, ),并配有对应的链接分值。由于每一个三元组所具有的信息较少,并没有提供足够的上下文,因此实体链接过程主要基于主宾语名称以及实体在知识库中名称的模糊匹配。
实体在知识库中存在至多一个标准名称以及多个别名,例如 Freebase 中,实体的标准名称和别名分别对应 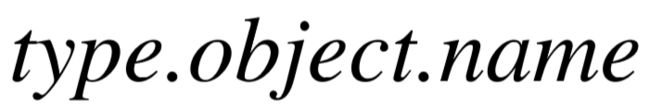 以及
以及 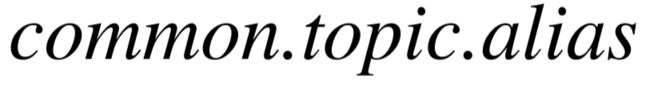 属性。我们利用这些属性值构建了从单词指向不同名称的倒排索引,并进一步生成每个关系参数的候选实体。我们用
属性。我们利用这些属性值构建了从单词指向不同名称的倒排索引,并进一步生成每个关系参数的候选实体。我们用 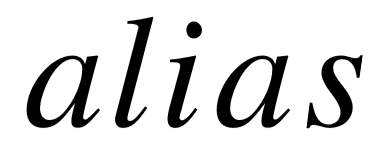 表示知识库中的一个名称(或别名),若将其看做单词的集合( bag-of-words),那么显然单词之间具有不同的重要性。直观上看,若 中某单词
表示知识库中的一个名称(或别名),若将其看做单词的集合( bag-of-words),那么显然单词之间具有不同的重要性。直观上看,若 中某单词  出现在极少数的名称中,那么它对整个名称而言更加重要;反之类似“ of ”,“ the ”等停止词会出现在大多数名称里,那么在模糊匹配的过程中,其权重就很低。因此我们利用文档频率倒数( Inverted Document Frequency )用于拟合单词 的权重:
出现在极少数的名称中,那么它对整个名称而言更加重要;反之类似“ of ”,“ the ”等停止词会出现在大多数名称里,那么在模糊匹配的过程中,其权重就很低。因此我们利用文档频率倒数( Inverted Document Frequency )用于拟合单词 的权重:
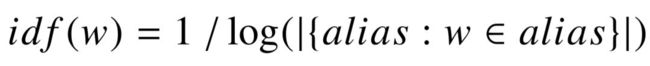
(4-1)
此外,我们直接从知识库的名称中过滤停止词,相当于它们的 idf 分值为 0。为了衡量 关系三元组中的关系参数 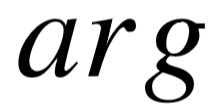 与知识库名称 间的模糊匹配程度,我们计算两者之间的带权重叠分值:
与知识库名称 间的模糊匹配程度,我们计算两者之间的带权重叠分值:
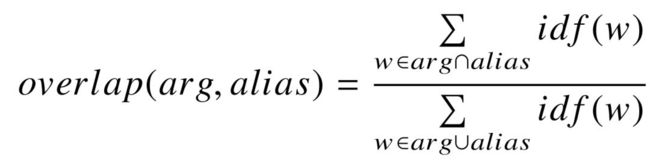
(4-2)
对于候选实体  ,我们分别计算其不同名称与关系参数的模糊匹配分值,最终选取最高分代表实体 与关系参数 的匹配度:
,我们分别计算其不同名称与关系参数的模糊匹配分值,最终选取最高分代表实体 与关系参数 的匹配度:
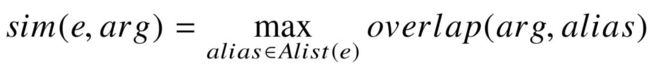
(4-3)
为了控制候选实体的质量,对于由  个单词构成的关系参数(停止词忽略不计),我们仅考虑那些存在至少一个名称具有 −1 个单词重叠,同时模糊匹配度高于阈值
个单词构成的关系参数(停止词忽略不计),我们仅考虑那些存在至少一个名称具有 −1 个单词重叠,同时模糊匹配度高于阈值  的候选实体。对于每个关系三元组中的主宾语,我们分别抽取匹配度排名前 10 的候选实体,用于后续的计算。
的候选实体。对于每个关系三元组中的主宾语,我们分别抽取匹配度排名前 10 的候选实体,用于后续的计算。
对单个关系参数进行匹配计算之后,我们将计算关系三元组 ( 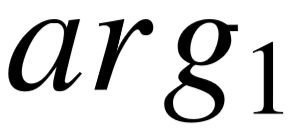 , ,
, , ) 与实体对 ( , ) 之间的联合匹配度。联合匹配度的定义方式有两种。第一种匹配方式较为朴素( Naive ),仅考虑关系中的两个参数与各自实体的匹配程度,主宾语实体互相之间并无直接影响:
) 与实体对 ( , ) 之间的联合匹配度。联合匹配度的定义方式有两种。第一种匹配方式较为朴素( Naive ),仅考虑关系中的两个参数与各自实体的匹配程度,主宾语实体互相之间并无直接影响:
![]()
(4-4)
第二种匹配方式除了考虑 和 各自的匹配分数,还考虑到了这两个实体之间存在的联系,在知识库上体现为连接它们的谓词或谓词序列。我们以  表示 的所有单词,
表示 的所有单词, 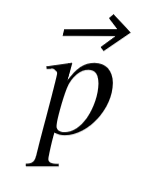 表示知识库中连接 和 的谓词路径,其长度至多为 2 。若实体 与 可以通过长度为1的路径相连,则意味着知识库中存在通过某谓词
表示知识库中连接 和 的谓词路径,其长度至多为 2 。若实体 与 可以通过长度为1的路径相连,则意味着知识库中存在通过某谓词  连接的事实三元组 ( , )。 类似地,若 和 之间通过长度为 2 的路径相连,则意味着存在
连接的事实三元组 ( , )。 类似地,若 和 之间通过长度为 2 的路径相连,则意味着存在 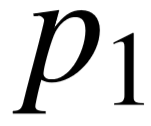 ,
, 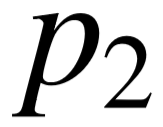 以及中间实体
以及中间实体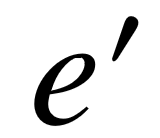 ,使得事实 ( , ) 以及 ( , ) 存在于知识库中。我们利用朴素贝叶斯模型,利用条件概率的形式定义谓词序列 与关系 之间的相关程度:
,使得事实 ( , ) 以及 ( , ) 存在于知识库中。我们利用朴素贝叶斯模型,利用条件概率的形式定义谓词序列 与关系 之间的相关程度:
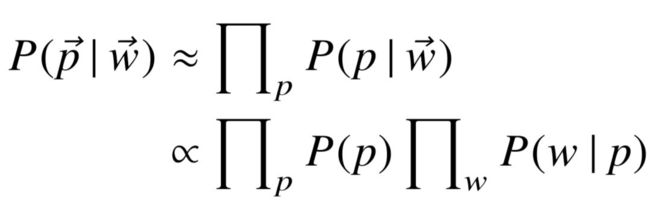
(4-5)
Yao 等人[35] 将知识库谓词序列与关系的对应建模为机器翻译模型,并根据对齐模型 IBM Model 1[122] 学习谓词的先验概率 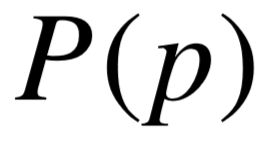 以及转移概率
以及转移概率 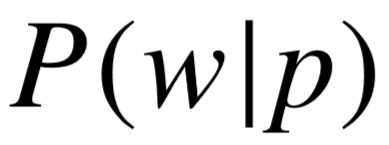 。基于已有工作的概率模型,给定关系后预测谓词序列的条件概率
。基于已有工作的概率模型,给定关系后预测谓词序列的条件概率 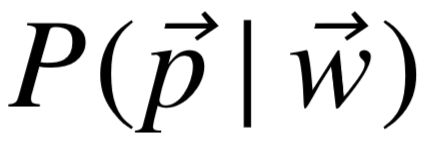 便可计算得出。对于候选实体 和 ,它们之间的谓词序列与关系 越接近,则实体链接结果越有可能正确。因此,我们通过枚举 和 之间所有满足长度条件的谓词序列,计算关系实例与实体对之间的相似度:
便可计算得出。对于候选实体 和 ,它们之间的谓词序列与关系 越接近,则实体链接结果越有可能正确。因此,我们通过枚举 和 之间所有满足长度条件的谓词序列,计算关系实例与实体对之间的相似度:

(4-6)
由于条件概率 的计算涉及到大量连乘,其数值在不同实体对之间的的差别较为明显,这也使得其在公式4–6中具有较高的地位。而当所有候选实体间的谓词序列与当前关系都不相似的时候,条件概率的随机波动反而会带来不小的干扰。因此,我们采用了一种集成( Ensemble )方案:首先定义条件概率阈值  ,对于当前关系实例的所有候选实体对,若其中存在至少一条与关系足够相近的谓词序列,即满足
,对于当前关系实例的所有候选实体对,若其中存在至少一条与关系足够相近的谓词序列,即满足  时,模型使用公式4–6进行整体匹配度计算,否则模型退回到公式4–4,使用朴素的方式寻找最佳实体对。最后,我们选择分数最高的实体对,作为关系三元组的唯一链接结果。
时,模型使用公式4–6进行整体匹配度计算,否则模型退回到公式4–4,使用朴素的方式寻找最佳实体对。最后,我们选择分数最高的实体对,作为关系三元组的唯一链接结果。
4.1.2.2 关系分组
这个步骤对所有已链接的关系三元组进行聚类,拥有相似关系描述的三元组将归为同一分组。每个三元组仅存在于唯一一个分组中。
这个步骤的思路是通过语法转换,将复杂的关系描述进行简化。如果两个不同的关系具有相同的简化形式,那么视为其语义相同,并归为同一分组。首先考虑到形容词、 副词以及情态动词的存在与否,基本上不会改变一个关系中主宾语实体所属的类型,因此我们将这些词从关系描述中移除。此外,大多数关系包含动词,但时态并不一致,因此我们将所有时态统一为现在时。此外,关系中的被动语态将会被保留,不做形式转变。例如经过语法转换之后,下列关系实例将归为同一组:( X, resign from, Y ), ( X, had resigned from, Y ) 以及 ( X, finally resignd from, Y )。最后,每一个分组的代表关系为组内关系的统一简化形式。如上例所示,三个关系实例属于“ resign from ”组。
4.1.2.3 类型搭配排序
给定一个关系分组  ,这一步骤将生成排好序的主宾语类型对,即该关系的代表性模式。以二元关系“ play in ”举例,理想情况下,生成的结果里会包含模式⟨ actor, film ⟩ 以及⟨ pro_athlete, sports_league ⟩。
,这一步骤将生成排好序的主宾语类型对,即该关系的代表性模式。以二元关系“ play in ”举例,理想情况下,生成的结果里会包含模式⟨ actor, film ⟩ 以及⟨ pro_athlete, sports_league ⟩。
对于带链接的三元组 ( , , ),若在知识库中, 具有类型  ,而 具有类型
,而 具有类型 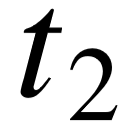 ,那么该三元组为类型搭配⟨ , ⟩的一个支持实例。一个实体有可能从属于多种类型,无论类型宽泛或具体,因此一个三元组可以支持多种类型搭配。对关系分组 中的所有实例进行处理,我们可以得到每一种类型搭配所对应的支持集合:
,那么该三元组为类型搭配⟨ , ⟩的一个支持实例。一个实体有可能从属于多种类型,无论类型宽泛或具体,因此一个三元组可以支持多种类型搭配。对关系分组 中的所有实例进行处理,我们可以得到每一种类型搭配所对应的支持集合:
![]()
(4-7)
得到所有可能的类型搭配之后,我们可以根据支持集合的大小进行排序。由于每个实体从属于多种类型,因此显然更加宽泛的类型搭配通常会被排在前列。但是,对于人类或是机器理解一个自然语言关系,宽泛的关系模式所具有的信息量相对不足,尤其是当两种类型对具有几乎一致的支持集合时,往往更具体的类型对具有更好的代表性。例如对于关系“ X die in Y ”,在开放式信息抽取和实体链接均不产生错误的情况下,类型对 ⟨ person, location ⟩和⟨ deceased_person, location ⟩将对应完全一致的支持集合。后者对关系的描述更加具体,在不丢失支持实例的同时,尽可能缩小主语在知识库中的范围。
由此可见,对候选类型对的排序需要考虑每个类型的相对粒度。接下来的目标就是提取知识库中类型之间的包含关系,建立更加完整的层次结构。我们定义所有属于类型  的实体为
的实体为  。理想情况中,若 包含于 ,那么所有 中的实体都从属于 ,即
。理想情况中,若 包含于 ,那么所有 中的实体都从属于 ,即 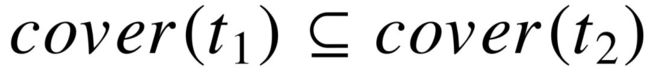 . 这样的包含规则称为“严格类型包含”。例如在 Freebase 中,类型 person 所包含的其它类型包括 actor,politician 以及 deceased_person 等。
. 这样的包含规则称为“严格类型包含”。例如在 Freebase 中,类型 person 所包含的其它类型包括 actor,politician 以及 deceased_person 等。
然而,严格类型包含在知识库中并不多见,主要原因是知识库的类型定义和人类对自然界的归纳存在一定差别,以 Freebase 中的 award_winner 为例,类型中绝大多数实体都为自然人,但依然包含少量的组织实体在内。基于严格类型包含的规则,award_winner 与 person 之间毫无包含关系,但事实上,考虑到非自然人实体仅存在极少数,两个类别之间在很大程度上依然构成从属关系。另一方面,由于实体的类型涉及到人工标记,一 旦出现类型标记错误,就有可能导致类型之间无法满足严格包含条件。
为了能更好地建立类型层次关系,我们使用一种更加松弛的类型包含定义方式。具体而言,若 中足够数量的实体从属于 ,那么就认为包含关系成立。因此,我们定义 包含于 的度,即对应实体包含的比例:

(4-8)
若 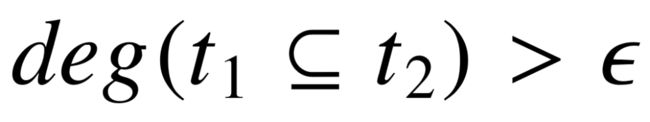 ,则 包含于 。阈值 ϵ 表示松弛程度,若 ϵ = 1,则松弛包含退化 为严格包含。若 ϵ 太小,那么类型之间将具有非常丰富的层次关系,但其有效性则会下降。最后,遍历知识库中所有的类型,我们就可以得到特定松弛程度下的类型层次图。
,则 包含于 。阈值 ϵ 表示松弛程度,若 ϵ = 1,则松弛包含退化 为严格包含。若 ϵ 太小,那么类型之间将具有非常丰富的层次关系,但其有效性则会下降。最后,遍历知识库中所有的类型,我们就可以得到特定松弛程度下的类型层次图。
随着类型层次关系建立完毕,我们就可以定义不同类型搭配之间的包含关系。若类型对⟨ , ⟩被另一个类型对⟨  ,
,  ⟩,则意味着以下条件之一成立:i) ⊆ , ⊆ ;ii) ⊆ , = ;iii) ⊆t4, = 。最终的类型对排名体现为支持集合大小和类型对包含关系的共同作用。以支持集合降序排列为基础,若类型对
⟩,则意味着以下条件之一成立:i) ⊆ , ⊆ ;ii) ⊆ , = ;iii) ⊆t4, = 。最终的类型对排名体现为支持集合大小和类型对包含关系的共同作用。以支持集合降序排列为基础,若类型对  = ⟨ , ⟩包含于另一个类型对
= ⟨ , ⟩包含于另一个类型对  ,且各自的支持集合大小 (
,且各自的支持集合大小 ( 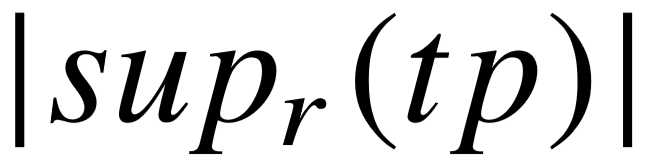 ) 几乎一致,那么 将排在 之前。我们同样可以根据重叠关系实例的覆盖程度,来定义两个支持集合是否几乎一致:
) 几乎一致,那么 将排在 之前。我们同样可以根据重叠关系实例的覆盖程度,来定义两个支持集合是否几乎一致:
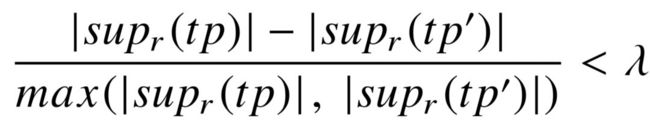
(4-9)
其中  为判断集合中的元素是否一致的阈值。
为判断集合中的元素是否一致的阈值。
4.1.3 实验
4.1.3.1 实验设置
我们在实验中使用的知识库为 Freebase [9]在2014年2月16日的版本,包含了大约 40,000,000 个不同实体,以及 1,700 个主要类型。实验中使用的开放式信息抽取系统为 ReVerb [2],ReVerb 数据集提供了多种版本,我们使用的版本包含了置信度最高的 14,000,000 个关系三元组。
ReVerb 抽取的三元组中,部分关系参数无法链接到 Freebase 中的某一个实体,例如三元组 ( Metro Manila, consists of, 12 cities ),其宾语显然不是一个实体,而是用自然语言描述的类型。这部分三元组不是我们的研究对象,需要进行过滤。考虑到在自然语言中,概念通常对应非专有单词,并且多为小写,因此我们根据 WordNet 收集了常用的非专有单词。若一个三元组中包含纯小写,或纯粹由非专有单词构成的主宾语,那么该 三元组将被过滤。除此之外,ReVerb 三元组中还具有时间或日期作为关系参数的情况, 例如“ Jan. 16th,1981 ”作为宾语,但同样不对应 Freebase 的某个实体。为应对这种情况,我们使用 SUTime [123] 工具识别时间或日期,将它们替换为具有 type.datetime 类型的虚拟实体。经过清理之后,系统共收集了 3,234,208 个三元组,对应 171,168 个不同的关系分组。
实验中具体使用的参数值为:τ = 0.667,ρ = 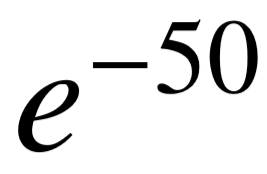 ,ϵ = 0.6 以及 λ = 5%。关系分组步骤中,我们使用 Stanford Parser [124] 对每个关系进行词性标注、语法分析以及时态转换。
,ϵ = 0.6 以及 λ = 5%。关系分组步骤中,我们使用 Stanford Parser [124] 对每个关系进行词性标注、语法分析以及时态转换。
4.1.3.2 结果分析
我们首先对实体链接进行评测。由于 ReVerb 没有提供主宾语的链接结果,我们从所有关系实例中随机挑选 200 个三元组,并人工标注这些主宾语所链接的实体。我们对比实体链接过程的朴素方法和集成方法,使用准确率( Precision ),召回率( Recall ), F1 分值,以及 MRR [125]作为评价指标。MRR 为平均排名倒数( Mean Reciprocal Rank ), 即统计正确的链接结果在输出列表中的排名,再计算所有三元组上排名倒数值的平均。 当一个三元组的主宾语均链接正确时,我们才认为该三元组链接正确。实验结果比较如表4–1所示。不同于常规文本的实体链接,由于每个三元组的上下文极少,链接具有一定难度。基于集成的链接方法引入了关系与实体间语义的匹配模型,使主宾语的链接实体互相影响,链接过程的准确率和召回率均得到稳定提升。

表4–1 ReVerb 三元组的实体链接实验结果。
接下来我们衡量二元关系的主宾语搭配结果,主要关注具有较多实例的关系分组。我们首先从包含至少500个三元组的关系分组中,随机选择50个分组,对于每个分组,我们挑选出支持集合数量最大的100个类型对作为评测的对象。我们将这些类型对分配给3位对 Freebase 类型有了解的标注者,每个标注者根据自己的理解,判断类型对是否适合于描述对应关系,并标注0到3的分值。将三位标注者的打分进行平均,即可得到这50个关系分组的类型对排序。
我们使用点对点互信息( Pointwise Mutual Information )[126] 作为基线模型,该模型在选择偏好任务中被使用,例如文献[119]。 PMI 模型使用以下公式定义一个关系 与类型对 的关联度:

(4-10)
其中  代表联合概率,即关系分组为 ,且支持 的三元组占所有三元组的比重, ∗ 代表任意关系或类型对。
代表联合概率,即关系分组为 ,且支持 的三元组占所有三元组的比重, ∗ 代表任意关系或类型对。
我们使用 MRR 分数进行评测,衡量不同方法生成的最佳关系模式在标注列表中的位置。如表4–2所示,和基线模型进行比较,我们的方法在 MRR 指标上获得了10.1%的相对提升。
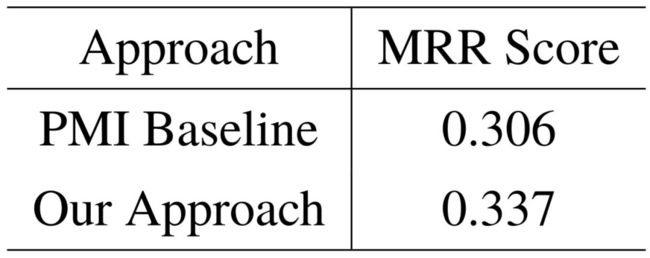
表4–2 二元关系模式推理的评测结果。
最后,表4–3列举了一些具体的关系分组,以及我们系统抽取的关系模式。我们可以看出,当构建了 Freebase 的类型层次结构之后,系统能够同时得到粗粒度和细粒度的类型信息,因此最终生成的类型对具有更加丰富的信息量。
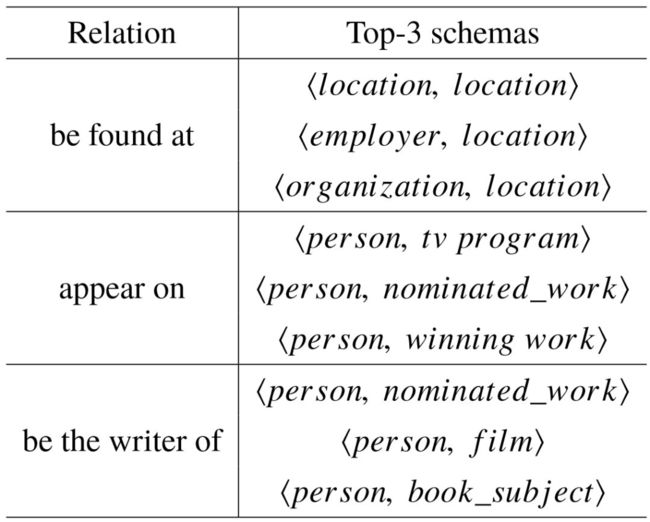
表4–3 生成的二元关系模式举例。
4.2 关系的结构化语义挖掘
上一节的研究目标是挖掘一个关系所存在的主宾语类型搭配,用于区分不同的语义。本节的研究重点放在了深入理解关系本身,用结构化的符号代替字符形式的描述。 我们提出了基于模式图的语义表示方法,与传统路径规则相比,图结构具有的分支可以更好地支持复杂语义,具有良好可解释性的同时,也可被用于知识库补全任务中。
4.2.1 概述
以 DBPedia、Freebase 等为代表的开放领域知识库包含了预先定义好的标准化的知识库谓词,用于连接知识库中的实体、类型和概念。知识库中的事实采用三元组形式表示,与关系三元组保持一致。本节中,我们假定每个关系三元组均已完成了实体链接步骤,用( 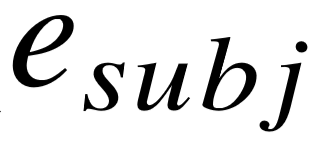 , ,
, , 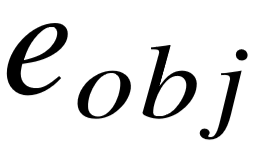 )来表示。那么很显然,事实三元组和关系三元组的区别仅体现在谓 语成分上。因此,利用知识库谓词来表示自然语言关系的语义,是一个很自然的想法, 若能将开放式信息抽取中的每一个关系实例都映射为知识库中的三元组,那么机器将很容易理解海量非结构化文本中蕴含的结构化信息。这种基于直接对应的思路非常直观,但是对于现有的知识库,例如 Freebase [9],即便其中包含十亿级别的事实三元组,仍然会面临两个主要的挑战。
)来表示。那么很显然,事实三元组和关系三元组的区别仅体现在谓 语成分上。因此,利用知识库谓词来表示自然语言关系的语义,是一个很自然的想法, 若能将开放式信息抽取中的每一个关系实例都映射为知识库中的三元组,那么机器将很容易理解海量非结构化文本中蕴含的结构化信息。这种基于直接对应的思路非常直观,但是对于现有的知识库,例如 Freebase [9],即便其中包含十亿级别的事实三元组,仍然会面临两个主要的挑战。
首先,知识库和自然语言关系之间存在着语义鸿沟。以关系“ has grandfather ” 为例,Freebase 中并不存在一个谓词能与之完全匹配,但存在一些和它相关的谓词,例如 parents 以及 gender 。这是因为知识库的构建过程较为严谨,为了避免歧义,每一种谓词的语义都更加单一,同时为了避免信息冗余,能通过其它谓词进行描述的语义,通常不会对应一个单独的谓词。
其次,知识库的构建还远不够完整。即便拥有海量的事实三元组,但依然存在很多长尾的谓词,并没有多少事实与之相关。这个挑战也引入了另一个开放的研究课题,即知识库补全( Knowledge Base Completion )[25,26,127]。该课题的目标是,给定知识库中的目标谓词,根据其拥有的少量事实三元组进行学习,为其补充新的事实,这些新事实的主语和宾语均为知识库中已存在的实体。换言之,在已有的实体之间连接更多的谓词, 使知识库更加稠密。
为了应对以上两个挑战,我们关注的重点在于能否利用知识库中已经存在的谓词, 描述一个自然语言关系所具有的语义。已有的相关研究方法主要可以分为两大类。第一类方法为知识库的向量表示学习。这种方法类似于词向量技术,利用知识库中的三元组作为训练数据,学习每个实体以及谓词在连续空间中的特征表示,使得每个三元组的两个实体和谓词表示之间满足特定的代数关系。将开放式信息抽取的关系三元组与知识库已有的事实三元组合并,这类方法可以获取每一个目标关系的隐含语义。但考虑到知识库表示学习中涉及到的参数数量非常庞大,这种方法需要大量的训练数据以应对长尾实体,同时训练的时间开销也不可忽略。已有的研究工作主要集中在了较小的知识库上,例如 FB15K [29,128]。
另一类方法为规则推导,每个目标谓词或关系的语义表达由明确的规则构建而成。这里的规则等价于知识库的子结构,用于连接自然语言关系中的主语和宾语实体。其中最基本的结构为路径的形式,即通过一个或多个谓词组成序列,连接主语和宾语。规则推导方法的优势在于高度可解释性。一方面,知识库的子结构可以转换为知识库上的查询语言例如 SPARQL ,因此可以通过在知识库上运行查询的方式,明确得知特定的两个实体之间是否可能存在某种关系。另一方面,相比知识库向量学习方式,基于规则推导的方法允许使用多条规则描述同一个关系,更好地适应自然语言中的多义性。此外,必要的情况下,人类可以对输出的规则进行微调。
根据以上论述,本节的研究建立在规则推导的基础之上。因此,我们将传统的基于路径的规则进行扩展,而是以树形结构的形式,不仅连接主语和宾语,同时还连接了其余相关实体,用于表示目标关系所具有的隐藏语义限制。这种树形结构是具有相同边结构的知识库中具体子图的抽象表示,我们将其称为模式图( Schema Graph )。图4–2是二元关系“ has grandfather ” 的模式图,通过谓词路径 [ parents, parents ] 表示主宾语之间的祖孙关系,同时利用 gender 限制宾语的性别,以此精确描述关系语义。

图4–2 二元关系“ has grandfather ”的语义表示。
具体而言,给定自然语言中的关系r 以及抽取出的三元组 ( , , ),本章的研究任务是在知识库中挖掘出一系列与之相关的模式图,并且用概率分布的形式,描述用特定模式图代表该关系语义的可能性。在进行模式图推理的过程中,我们主要会面临以下三个技术性挑战:
首先,候选模式图的数量非常庞大。传统的规则推导中只考虑谓词路径,虽然候选路径的数量随长度呈指数增长,但在知识库中能够连接两个特定实体的路径仅有少数, 因此简单遍历可以得到所有的候选路径。然而,具有树形结构的模式图中,不仅存在额外的谓词作为分支,而且包括用于语义限制的实体, 任何一个实体的改变,都会产生一个新的模式图。若使用暴力枚举生成模式图,时间复杂度上无法承受,同时还会生成大量偏离语义的模式图。
其次,模式图推理需要做好粒度上的平衡。当一个模式图缺少足够的语义限制,它虽然能匹配已知的三元组,但也可能混淆了错误的三元组。反之,若一个模式图包含了不必要的语义限制,就很可能无法匹配已知的三元组。很显然,太具体或宽泛的模式图都无法精确表示一个关系的语义,但是如何兼顾这两点,并通过概率分布描述不同粒度候选的语义匹配程度,这成为了模式图推理过程中的另一个难点。
最后,模式图推理模型仅有三元组作为训练数据,不存在标注好的模式图,同时没有明确给出不符合特定关系的错误三元组数据,这给学习过程增添了难度。一种规避方法是使用封闭世界假设( Closed World Assumption ),即假定所有未见过的三元组都是错误的。但考虑到知识库本身远不够完整,封闭世界假设会带来大量的错误反例,这并不是一个最好的解决方案。
本章提出的基于模式图的规则推导模型旨在解决应对以上三个挑战,其主要贡献可 以分为以下四个部分:
1. 我们定义了自然语言关系的模式图。和传统规则推导模型相比,模式图是谓词路径形式的规则扩展,通过挖掘隐藏的关联实体,在路径之上构建分支,准确描述关系的复杂语义;
2. 我们提出了一种基于局部搜索的启发式方法,通过高效的剪枝策略,快速生成 关系所对应的候选模式图;
3. 我们提出了一种基于数据驱动的方法,将模式推理问题转化为查询任务进行建模,并在不明确生成负面训练数据的情况下,学习候选模式图之间的概率分布,实现不同粒度模式图的统一比较;
4. 我们对自然语言关系以及知识库中已有的谓词进行了知识库补全任务的测评, 包括主宾语预测和三元组分类两个子任务,我们的模型在这两个测评任务上均显著优于已有方法。具体生成的模式图结果表明,我们提出的模型能够挖掘出具体且精确的语义。
4.2.2 相关工作
随着大规模结构化知识库的提出与广泛使用,知识库补全任务成为了近年来的热门研究课题。该任务旨在对知识库中已有的谓词进行建模,通过预测潜在的 ( , , ) 三元组,实现扩充知识库的最终目的。到目前位置,在该课题上的研究方法主要分为两类: 基于知识库表示学习和基于规则推导。
知识库表示学习受到词向量技术[59,60]的启发,将知识库中的实体类比为单词,每个实体具有一个向量表示,对应连续语义空间上的一个点。作为连接不同实体的桥梁,知识库中的每个谓词都对应着各自的向量或矩阵表示。通过定义不同的向量或矩阵之间的运算方式,这类方法可以计算每个三元组的置信度,以此实现对实体及谓词的表示学习。
RESCAL 模型[28]是一个基础的知识库向量模型,它基于实体向量和谓词矩阵表示的双线性运算。HOLE 模型[82]是 RESCAL 模型的改进,使用向量循环平移的技巧计算实体间的组合语义向量,大幅度降低了谓词的表示维度。在众多知识库表示学习的方法中,有一组方法称为隐距离模型,它们对三元组置信度的计算方式主要基于连续空间中的距离度量:将主宾语向量经过某种方式的映射(翻译)之后,距离越小,置信度越高。 最典型的研究工作为 TransE ,其核心思路在于尽可能使每个三元组 ( h, r, t ) 对应的向量计算满足 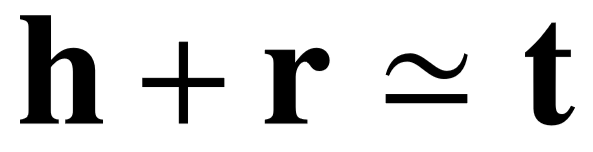 ,即利用谓词向量将连续空间中的主语进行平移,使其尽量与宾语重合。 为了能更好地表示多对多的关系,相关文献 [30,31] 对 TransE 模型进行了改良。Wang 等人提出了 TEKE 模型[129],它对已有的翻译模型进行改良,充分利用结构化文本的知识,寻找三元组中单词级别的共现,并利用共现上下文微调实体和谓词的向量表示。
,即利用谓词向量将连续空间中的主语进行平移,使其尽量与宾语重合。 为了能更好地表示多对多的关系,相关文献 [30,31] 对 TransE 模型进行了改良。Wang 等人提出了 TEKE 模型[129],它对已有的翻译模型进行改良,充分利用结构化文本的知识,寻找三元组中单词级别的共现,并利用共现上下文微调实体和谓词的向量表示。
基于规则推导的方法旨在用逻辑规则的形式表达谓词的语义。例如 parent( 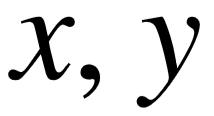 ) ∧ parent(
) ∧ parent(  ) → grandparent(
) → grandparent( 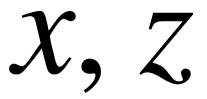 ) 是一个常识性的规则,我们可以通过规则的左侧部分,在知识库中寻找出更多的祖孙间的关系。Jiang 等人的工作[23]基于马尔科夫逻辑,通过挖掘的规则对自动构建的知识库进行信息过滤。其它一些方法使用概率软逻辑或关联规则挖掘完成类似的任务[130,131]。Galárraga 等人提出的 AMIE [22]以及 AMIE+[132]系统则直接根据知识库的三元组寻找置信度较高的一阶逻辑规则。最新的一些研究着眼于在知识库中寻找路径形式的规则,通过挖掘大量可能的路径,作为表示语义的特征。Lao 等人提出了 PRA 模型[25],通过在谓词路径上的随机游走策略,衡量其连接一对实体的好坏程度,目标关系的语义等同于不同路径特征的带权组合。Gardner 等人对 PRA 模型进行改进,提出了 SFE 模型[26],除了捕捉连接主宾语的路径以外,还从主宾语各自的知识库子图中挖掘独立的特征,同时谓词路径的定义更加宽泛,允许在其中使用通配符表示任意谓词。此外,Wang 等人提出了 CPRA 模型[79],这是对 PRA 模型的另一种改进,通过挖掘目标关系中的相关性,使得相似关系之间的路径挖掘结果可以互相影响。 然而,通过开放式信息抽取获得的三元组数量相对有限,不同的关系之间几乎不存在重叠的实体对,在这种场景下,CPRA 模型效果等价于原始的 PRA 模型。
) 是一个常识性的规则,我们可以通过规则的左侧部分,在知识库中寻找出更多的祖孙间的关系。Jiang 等人的工作[23]基于马尔科夫逻辑,通过挖掘的规则对自动构建的知识库进行信息过滤。其它一些方法使用概率软逻辑或关联规则挖掘完成类似的任务[130,131]。Galárraga 等人提出的 AMIE [22]以及 AMIE+[132]系统则直接根据知识库的三元组寻找置信度较高的一阶逻辑规则。最新的一些研究着眼于在知识库中寻找路径形式的规则,通过挖掘大量可能的路径,作为表示语义的特征。Lao 等人提出了 PRA 模型[25],通过在谓词路径上的随机游走策略,衡量其连接一对实体的好坏程度,目标关系的语义等同于不同路径特征的带权组合。Gardner 等人对 PRA 模型进行改进,提出了 SFE 模型[26],除了捕捉连接主宾语的路径以外,还从主宾语各自的知识库子图中挖掘独立的特征,同时谓词路径的定义更加宽泛,允许在其中使用通配符表示任意谓词。此外,Wang 等人提出了 CPRA 模型[79],这是对 PRA 模型的另一种改进,通过挖掘目标关系中的相关性,使得相似关系之间的路径挖掘结果可以互相影响。 然而,通过开放式信息抽取获得的三元组数量相对有限,不同的关系之间几乎不存在重叠的实体对,在这种场景下,CPRA 模型效果等价于原始的 PRA 模型。
一些相关的研究尝试在知识库向量学习的基础之上加入一定的逻辑规则。Guo 等人提出了 KALE 模型[133],其主要思想是将规则转换为多个三元组之间的与或非逻辑操作,因此基于翻译模型计算的三元组置信度得以在逻辑规则级别产生交互。TRESCAL 模型[134]在经典的 RESCAL 模型中加入了知识库的类型限制。而 Wang 等人的工作[135]使用整数线性规划技术,将知识库向量表示和规则挖掘进行统一。
狭义的知识库补全任务只考虑知识库中的谓词,我们的工作将知识库补全的场景进行了扩展。考虑到为了降低知识库结构与自然语言描述的差距,知识库补全任务也可以针对自然语言中的二元关系。开放式信息抽取与这样的任务相契合,既提供了全新谓词,又有一定量的三元组用于补全学习。一些已有的工作也关注了自然语言关系到知识库的映射。Zou 等人的工作[136]使用了非监督学习的方式,利用 TF-IDF 特征寻找关系到谓词路径的匹配。Zhang 等人的工作[24]利用马尔科夫逻辑网络[137],学习自然语言关系对应于不同候选谓词路径的概率。这些方法对关系的表示局限于路径的形式,无法准确地描述一个形式简单但具有组合语义的关系。我们的工作旨在理解具有复杂语义的关系,挖掘其包含的隐含限制条件,并通过具有 “路径 + 分支” 结构的模式图进行语义建模。
4.2.3 任务定义
在本章中,我们定义知识库为 KB = { E, L, P }三部分组成,具体如下:E 为知识库 KB 中所有实体集合;L 为 KB 中所有不同谓词的集合; P 为 KB 中所有事实三元组集合,每一个三元组表示为 ( , ),其中 , ∈ E,并且 ∈ L. 此外,知识库中存在用 于描述一个实体所拥有类型的谓词 IsA,为了简化描述,本章中我们将不同类型也看做实体,同属于集合 E 中。
一个模式图 S 同样由三部分构成,S = { 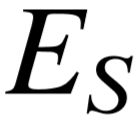 , X,
, X,  },具体如下: ⊆ E,为模式图中出现的具体的实体集合;
},具体如下: ⊆ E,为模式图中出现的具体的实体集合; 为实体变量的集合,每一个变量
为实体变量的集合,每一个变量 ∈ 在模式图中等同于占位符,为特定实体
∈ 在模式图中等同于占位符,为特定实体  ∈ E 的抽象;模式图中包含两个特殊变量,即
∈ E 的抽象;模式图中包含两个特殊变量,即  ,
,  ∈ ,分别代表目标关系的主语和宾语实体;
∈ ,分别代表目标关系的主语和宾语实体;  为模式图中的抽象三元组集合,每一个抽象三元组为 (
为模式图中的抽象三元组集合,每一个抽象三元组为 (  ,
, 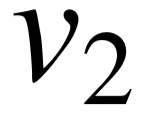 ),其中 ∈ , ∈ ∪ 以及
),其中 ∈ , ∈ ∪ 以及  ∈ L。此外,模式图 S 具有以下性质:
∈ L。此外,模式图 S 具有以下性质:
• S 的表现形式为有向树形结构,且根节点一定为主语的实体变量 ;
• 连接主语变量 和宾语变量 的谓词路径,称为模式图 S 的骨架;
• 骨架之外的所有抽象三元组称为模式图的限制(或分支);
• 一个仅具有骨架而不包含任何限制的模式图,称为简单模式图,等价于谓词路径。

图4–3 模式图的一般形式。
图4–3显示了模式图的一般形式。可以发现,其中的每一条边都至少连接了一个实体变量。模式图代表着知识库中,满足相同特定结构的一系列具体子图。这些具体子图称为实例图( Grounded Garph ),作为模式图的实例化形式,所有的实体变量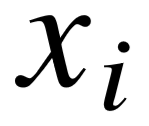 被替换为特定的实体
被替换为特定的实体 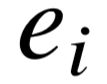 ∈ E,且每一个抽象三元组 ( , ) 在实例化之后均对应存在于知识库中的事实 ( , ) ∈ 。例如图4–2中的模式图,其不同的实例图囊括了知识库中所有已知的(个人,双亲,双亲父亲)知识。对于实例图中的主宾语对 (
∈ E,且每一个抽象三元组 ( , ) 在实例化之后均对应存在于知识库中的事实 ( , ) ∈ 。例如图4–2中的模式图,其不同的实例图囊括了知识库中所有已知的(个人,双亲,双亲父亲)知识。对于实例图中的主宾语对 ( 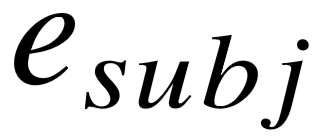 ,
,  ),我们称其为模式图的一个支持实例。
),我们称其为模式图的一个支持实例。
根据以上符号定义,给定知识库 KB,自然语言关系 以及多个关系三元组{( , , )},我们对关系的深度语义挖掘任务为,推导出一系列描述其语义的候选模式图,并学习模式图上的概率分布,以此表示自然语言关系所具有的多义性。
4.2.4 我们的方法
本节主要介绍将自然语言关系映射为模式图的具体方式。给定关系 以及其一系列 关系实例作为训练数据,我们首先依据给定的主宾语对( , ),从它们支持的所有模式图中寻找可能性较高的候选模式图,然后对具有不同粒度的模式图进行重要性衡量。由于没有直接的<关系,模式图>对作为训练数据,我们提出了一种基于远距离监督学习的方式,学习所有候选图上的概率分布。
4.2.4.1 候选模式图生成
根据已有的关系实例,我们提出了一种高效的搜索算法,在知识库上挖掘可能表示关系语义的候选模式图。其基本思路在于,首先通过主宾语对寻找仅由骨架(谓词路径) 构成的简单模式图,带有限制的模式图生成则以简单模式图为起点,不断寻找与关系三元组契合的限制,并通过递归的形式将新的限制连接到已有的候选上,一步步生成具有复杂结构的模式图。
简单模式图的生成基于实体对在知识库中的直接连接。我们使用双向广度优先搜索,为每个实体对提取由主语连接到宾语的所有谓词路径。考虑到一个自然语言关系通常由短语构成,通常不会具有太多的语义跳跃,因此我们对谓词路径长度进行限制,避免生成大量无意义的路径。基于前人的工作[24],我们限制谓词路径最长不超过3。此外,为了尽可能保证每一个候选图的质量,我们需要排除那些仅由偶然数据生成,实则偏离语义的候选图。一个有效的识别方式利用了候选图的支持率,即支持候选图的实体 对占目标关系所有已知实体对的比例,记做 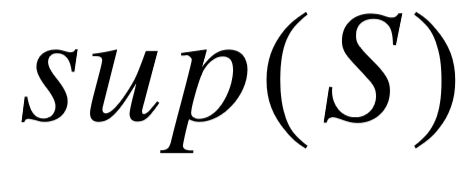 。我们在生成过程中指定支持率阈值
。我们在生成过程中指定支持率阈值  ,并移除那些支持率 小于 的模式图。综上,对谓词路径和支持率的限制,可以使候选生成步骤过滤大量的干扰模式图。
,并移除那些支持率 小于 的模式图。综上,对谓词路径和支持率的限制,可以使候选生成步骤过滤大量的干扰模式图。
在生成仅包含骨架的简单模式图之后,我们采用深度优先搜索的方式获取更多更加具体的模式图。如图4–4所示,“ has grandfater ”关系可以生成多种不同的简单模式图,在此基础上,我们逐步添加表示复杂语义的分支,让模式图更加具体。这个步骤的挑战在于,即便骨架长度得到限制,模式图扩展的搜索空间仍然异常庞大。为了提高效率,我们使用优先队列维护搜索过程中获取的高质量模式图,并进行剪枝操作,压缩候选图的搜索空间。具体步骤的伪代码流程如算法4–1所示。Q 为存放模式图的优先队列,初始化为空,最大容量为 B,搜索过程中始终维护具有最大支持率的前 B 个候选图(第8行)。 使用支持率作为剪枝依据的原因有二:一方面如同骨架生成中的论述,支持率高的模式图更不容易偏离语义,而支持率过低的候选图更有可能引入了不必要的限制,导致无法匹配大量已知三元组;另一方面,随着候选图上添加的限制越多,支持率一定呈非严格单调递减趋势,因此这种单调性特征可以直接用于剪枝。函数 Schema Expansion 以模式图 S 为输入,返回值为一个模式图集合,其中每个模式图均为在 S 上加入一条新的限制所形成的更复杂的候选,例如图4–4中的 ( , gender, Male ),( , profession, Politician )等。

图4–4 “ has father ” 模式图挖掘示例。

为了使候选模式图之间具有多样性,我们期望最终保留的 B 个候选图中能包含多种不同的骨架,因为不同骨架的模式图通常代表更大的语义差别。因此在实际的搜索过程中,我们根据不同骨架的支持率,将整个大小为 B 的优先队列按比例分为多块,每个骨架上的深度搜索将使用各自独立的优先队列。这样的做法可以提高并行工作效率,同时保证候选集合不被某个高支持率的骨架主导。
4.2.4.2 模式图概率推理
当关系的候选图生成完成之后,下一步需要从中推理出最具有代表性的那些模式图。我们的目标是将关系的表示多义性表示为每个候选模式图 S 的条件概率  ,这样不同粒度的模式图之间可以直接比较。由于没有直接的 < 关系,模式图 > 训练数据,我们对概率分布的学习方式依靠三元组数据作为驱动,将学习过程建模为知识库查询场景上的一个最优化问题:给定的一个关系实例中的主语(或宾语)实体,寻找最为合适的模式图概率分布,使得依照此分布在给定实体周围进行知识库查询时,能尽可能返回对应的宾语(或主语)实体。
,这样不同粒度的模式图之间可以直接比较。由于没有直接的 < 关系,模式图 > 训练数据,我们对概率分布的学习方式依靠三元组数据作为驱动,将学习过程建模为知识库查询场景上的一个最优化问题:给定的一个关系实例中的主语(或宾语)实体,寻找最为合适的模式图概率分布,使得依照此分布在给定实体周围进行知识库查询时,能尽可能返回对应的宾语(或主语)实体。
为了能够在不同粒度的候选模式图之间得到平衡,我们使用最大化似然估计的方式定义目标函数,寻找最优的模式图概率分布,使得查询过程返回正确实体的概率最高。 似然函数定义如下:

(4-11)
其中,向 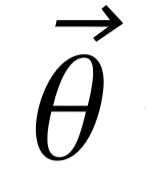 表示候选模式图的概率分布,即
表示候选模式图的概率分布,即  对应条件概率
对应条件概率  ,且满足
,且满足  = 1。
= 1。 ,
,  分别表示关系的第
分别表示关系的第  个实例中的主语和宾语。
个实例中的主语和宾语。
接下来,我们通过两阶段的生成过程,对概率  进行建模:首先根据模式图上的多项分布,随机挑选出一个模式图 S ∼
进行建模:首先根据模式图上的多项分布,随机挑选出一个模式图 S ∼ 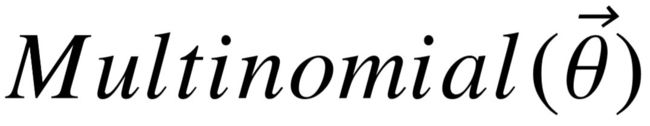 ,然后对模式图 S 进行查询(即在知识库上进行实例化),在所有主语为
,然后对模式图 S 进行查询(即在知识库上进行实例化),在所有主语为 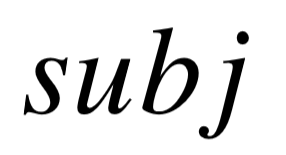 的实例图中,随机挑选其中的一个实例图,将其宾语实体返回。第一个阶段中,模式图的选取与主语 条件独立,第二个阶段由于固定了模式图,因而与 也条件独立。考虑这些条件独立之后,
的实例图中,随机挑选其中的一个实例图,将其宾语实体返回。第一个阶段中,模式图的选取与主语 条件独立,第二个阶段由于固定了模式图,因而与 也条件独立。考虑这些条件独立之后,  的生成过程定义如下:
的生成过程定义如下:

(4-12)
概率 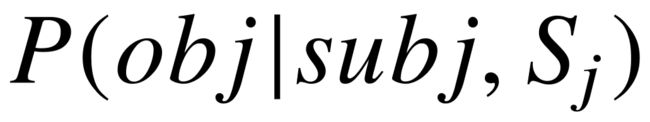 的值对应模式图
的值对应模式图  在知识库上的查询结果:令
在知识库上的查询结果:令  代表模式图 的实例图中,所有主语实体为 的对应宾语集合,以均匀分布从中挑选 一个实体
代表模式图 的实例图中,所有主语实体为 的对应宾语集合,以均匀分布从中挑选 一个实体 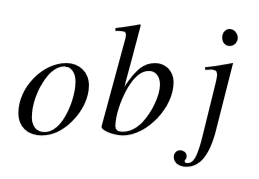 ,公式展开如下:
,公式展开如下:

(4-13)
公式中的 α 为平滑参数,在目标宾语无法通过 得到时,我们将概率定位很小的数值, 防止整个似然函数值变为 0。观察可知,对于过于宽泛的模式图 , 集合数量很大,从中随机选择到目标宾语的概率会因此降低;而对于过于具体的模式图,会使得较多的实体对无法被支持,因此同样会对似然带来降低。由此可见,基于两阶段生成的概率建模方式,可以实现宽泛与具体模式图之间的平衡,找到最适合的语义结构。此 外,  的定义为公式4–12的对称版,代表着给定宾语实体,查询得到目标主语的概率。
的定义为公式4–12的对称版,代表着给定宾语实体,查询得到目标主语的概率。
综上,我们将模式图推理问题转化为了基于最大似然估计的最优化任务,并利用梯度下降算法对模型参数 进行更新,使目标函数  值最大。具体使用的梯度下降算法为 RMSProp [138]。
值最大。具体使用的梯度下降算法为 RMSProp [138]。
4.2.5 实验
本节中,我们首先对推理出的模式图进行直接的质量测评,然后使用主宾语预测和三元组分类这两个任务定量评估模式图的语义表达能力,最后我们分析一些错误例子,讨论当前模型的不足之处。
4.2.5.1 实验设置
知识库:为了和已有的知识库向量表示方法进行公平比较,我们在实验中使用了两个 Freebase 的子集:FB3m 以及 FB15k 。FB15k 由 Bordes 等人提出[29],它包含了 14,951 个实体,1345 种不同谓词,以及 483,142 个事实三元组。FB15k 的三元组被分为了训练集、验证集、测试集三部分,我们仅选用训练集部分作为使用的知识库。与此同时,我 们从 Freebase 2015年6月的版本抽取出最主要的 3,000,000 个不同的实体,并提取这些实体之间的联系,构成 FB3m 子集。FB3m 包含大约 50,000,000 个三元组,是 FB15 k的100倍。和完整的 Freebase 相比,FB3m 更加轻量化,但依然包含了大量有价值的信息。
关系数据集:我们使用了三个不同的关系数据集进行知识库补全的相关实验。在自然语言场景中,目标关系来源于开放式信息抽取系统 PATTY [4],包含了大约 200,000 种不同的自然语言关系,以及百万级别以上的三元组。由于 PATTY 使用维基百科作为语料库,三元组中的所有实体均为维基百科页面,因此每个实体均自动链接至 Freebase。 我们从 PATTY 中抽取子集“ PATTY-100 ”以及“  ”用于实验,PATTY-100 数据集与 FB15k 相匹配,其包含了100个具有较多数量三元组的关系,且三元组中所有实体均存在于 FB15k 中,平均每个关系包含180个关系实例。相对应地, 与 FB3m 相匹配,同样包含100个自然语言关系,平均每个关系包含388个实例。两个数据集中,每一个关系的三元组均被分为训练集、验证集、测试集(64%: 16%: 20%)。第三个关系数据集属于知识库场景,我们从 FB15k 的“ people ”、“ location ”以及“ sports ”三个领 域内挑选出37个热门谓词,并将它们的所有三元组抽取出,组合为数据集“ FB15k-37 ” 。每一个三元组出现在训练集、验证集、测试集的位置与FB15k 保持一致。FB15k-37 是 FB122 [133]的一个子集,保证其中每一个关系在测试集中都具有至少10个三元组。
”用于实验,PATTY-100 数据集与 FB15k 相匹配,其包含了100个具有较多数量三元组的关系,且三元组中所有实体均存在于 FB15k 中,平均每个关系包含180个关系实例。相对应地, 与 FB3m 相匹配,同样包含100个自然语言关系,平均每个关系包含388个实例。两个数据集中,每一个关系的三元组均被分为训练集、验证集、测试集(64%: 16%: 20%)。第三个关系数据集属于知识库场景,我们从 FB15k 的“ people ”、“ location ”以及“ sports ”三个领 域内挑选出37个热门谓词,并将它们的所有三元组抽取出,组合为数据集“ FB15k-37 ” 。每一个三元组出现在训练集、验证集、测试集的位置与FB15k 保持一致。FB15k-37 是 FB122 [133]的一个子集,保证其中每一个关系在测试集中都具有至少10个三元组。
用于比较的已有方法:对于知识库向量表示的方法,我们与 TransE [29],KALE [133],TEKE [129] 以及 HOLE [82]进行比较。对于规则推导的方法,我们与 SFE [26]以及 AMIE+ [132]这两个系统进行比较。我们考虑使用 CPRA 模型[79]作为另一个比较方法。但在 PATTY 相关的数据集中,不同关系之间几乎不存在相同的实体对,因此 CPRA 模型将会退化为传统的 PRA 模型[25],被更优秀的 SFE 严格取代。这些模型在2.2节或4.2.2节中已有论述。
模型实现细节:我们评估了模型的两个变种,分别为生成带限制的模式图的 OursSC ,以及仅生成简单模式图的 Ours-SK 。以下是具体调参细节:
• 候选模式图的数量,即优先队列容量 B 设为5000;
• 模式图骨架长度限制 τ 设为3,我们的方法可以支持更长的骨架,但具体测试中无明显的效果提升,同时候选生成时间显著增长,这里不展开讨论;
• 支持率阈值 γ 调参范围为{ 5%,10%,15%,20% };
• 平滑参数 α 调参范围为{ 1e-6,1e-5,1e-4 };
• 学习率 η 调参范围为{ 0.02,0.05,0.1 }。
用于比较的系统中,具有开源代码的方法包括 AMIE+ ,SFE 以及 HOLE 。KALE 的代码由作者提供,TransE 基于 HOLE 的代码运行,并且我们在 TransE 的基础上自行实现了 TEKE 模型。以上基于知识库向量表示的模型均使用最大间隔损失进行训练,对于 KALE 模型,学习率调参范围为 { 0.02, 0.05, 0.1 },最大间隔参数范围为{ 0.1, 0.12, 0.15, 0.2 };对于TransE,TEKE 以及 HOLE ,学习率调参范围为{ 0.05,0.1,0.2 },最大间隔参数范围为{ 0.5,1.0,1.5,2.0,2.5 }。
4.2.5.2 模式图质量测评
这一部分的实验中,我们主要关注具有明确结构的模式图是否可以弥补 Freebase 和 之间的语义差距。我们首先通过具体的例子观察不同的规则推导方法,即 Ours-SC,Ours-SK,AMIE+ 以及 SFE 所生成的代表性结构。我们从 数据集中挑选出四个具有一定复杂性的关系,并在较大结构的 FB3m 上学习各自的规则。对于 Ours-SC 和 Ours-SK,我们使用选择概率最高的模式图作为代表性结构。SFE 模型中,每个规则(谓词路径)都对应一个特征,我们选择特征权重最高的规则作为代表性结构。 AMIE+ 依靠准确率对规则进行排序,因此我们挑选准确率最高的规则,若多个规则准确率相同,我们则从中手动选择最合适的规则。

图4–5 不同的规则推导系统对四个复杂关系生成的代表性结构。
图4–5列出了四个自然语言关系,以及不同系统生成的最佳结构。其中,圆点表示实体或变量,左右两个黑色圆点分别代表 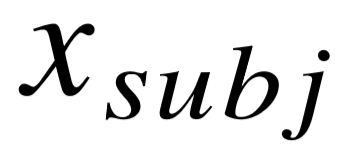 和
和  。方块代表知识库中的类型,菱形则代表用于维护多元关系的辅助节点。从这些例子中可以发现,Ours-SC 的模式图所具有的分支结构,可以带来更加精确的语义。对比仅生成骨架的 Ours-SK ,带有限制的查询图在每个例子上都表达了几乎完全正确的语义。另一方面,AMIE+ 和 SFE 输出的最佳结构不尽如人意。AMIE+ 按照准确率对规则排序,因此总是倾向于更具体的规则,但牺牲了召回率。同时随着规则长度提升至 4 甚至更高,AMIE+ 系统消耗了大量内存,无法返回任何结果。SFE 生成的规则中包含 [ Any-Rel ] 代表任意谓词,因此可以生成更多灵活的路径作为特征,但显然其中的大部分都不具有清晰的语义,人类难以直接理解。
。方块代表知识库中的类型,菱形则代表用于维护多元关系的辅助节点。从这些例子中可以发现,Ours-SC 的模式图所具有的分支结构,可以带来更加精确的语义。对比仅生成骨架的 Ours-SK ,带有限制的查询图在每个例子上都表达了几乎完全正确的语义。另一方面,AMIE+ 和 SFE 输出的最佳结构不尽如人意。AMIE+ 按照准确率对规则排序,因此总是倾向于更具体的规则,但牺牲了召回率。同时随着规则长度提升至 4 甚至更高,AMIE+ 系统消耗了大量内存,无法返回任何结果。SFE 生成的规则中包含 [ Any-Rel ] 代表任意谓词,因此可以生成更多灵活的路径作为特征,但显然其中的大部分都不具有清晰的语义,人类难以直接理解。
作为补充实验,我们对 Ours-SC 和 Ours-SK 生成的模式图进行了人工测评。对每一个自然语言关系,我们从中抽取出至多前 5 个概率值至少为 0.05 的模式图,并由三位标注者进行人工打分,分值选择范围为{ 0,0.5,1 },分别代表“不相关模式图”(骨架层次已出现语义偏离),“部分匹配”(骨架语义正确,但其余限制需要改善)以及“完全匹 配”(骨架和限制的语义均无明显偏差)。我们将三位标注者的打分进行平均,得到每一 个模式图的标注分值,并计算排名前 n 的所有模式图的平均分值,记做AvgSc@n 。三位标注者之间的 Kappa 系数为 0.541,具有稳定的相关性。表4–4列出了不同的 AvgSc@n 分值,Ours-SC 在骨架的基础上挖掘额外的语义限制,将结果提高了约13%。

表4–4 模式图列表的 AvgSc@n 测评结果。
4.2.5.3 主宾语预测任务测评
主宾语预测任务的目标是预测三元组 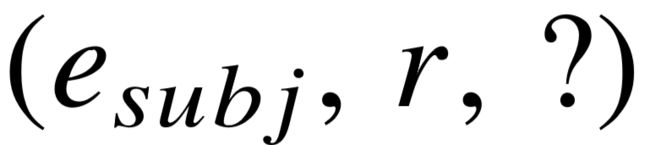 或
或  所缺失的宾语或主语。测试集中的每一个三元组都对应两个这样的预测任务。公式4–12代表着给定一端实体,生成另一端未知实体的概率,因此对每一个带有未知实体的待预测三元组,我们根据该公式计算生成不同实体的概率,并衡量答案实体的概率排名高低。我们在实验中使用了两个评价指标,分别为 MRR 和 Hits@n ,前者衡量答案实体在所有预测任务中的平均排名,后者关注在多少比例的预测任务中,答案实体的概率排在前 n 位。不同的实验方法通过验证集的 MRR 分值进行独立调参。
所缺失的宾语或主语。测试集中的每一个三元组都对应两个这样的预测任务。公式4–12代表着给定一端实体,生成另一端未知实体的概率,因此对每一个带有未知实体的待预测三元组,我们根据该公式计算生成不同实体的概率,并衡量答案实体的概率排名高低。我们在实验中使用了两个评价指标,分别为 MRR 和 Hits@n ,前者衡量答案实体在所有预测任务中的平均排名,后者关注在多少比例的预测任务中,答案实体的概率排在前 n 位。不同的实验方法通过验证集的 MRR 分值进行独立调参。
以上对排名高低的衡量暗含着一个假设:除了答案实体之外,其余实体均为错误实体。然而考虑到关系可能具有的一对多性质,对于一个待预测的三元组,除了答案实体之外,还可能存在其它实体与给定的已知实体匹配,严格来讲,这些实体虽然不同于唯一的答案,但也不应该算作错误。因此,我们使用和 TransE [29]相同的设定,在测评中引入两种不同的模式,分别为原始模式和过滤模式:在过滤模式中,计算每个预测的答案实体排名时,均忽略不同于答案的其余正确实体,因此过滤模式下,排名值可能会提高;而原始模式则不做任何的过滤。
我们使用 FB15k 作为知识库进行实验,并与其余模型进行比较。在接下来的实验中, 为了方便比较,我们的模型同一参数 γ = 10%,α = 1e−4,以及 η = 0.1,对应着 PATTY100 验证集上,在过滤模式下的最高 MRR 结果。表4–5和表4–6分别展示了在 PATTY-100 和 FB15k-37 数据集上的实验结果。在两个数据集上,SFE 模型的代码均碰到了内存问题,因此表格中没有列出对应的结果。对于 PATTY-100 中的关系,我们基于模式图的语义表示方法,其效果优于其它用于比较的规则推导与知识库向量表示模型,以及仅生成简单模式图的变种。在 FB15k-37 数据集上,Ours-SC与 Ours-SK 的结果十分接近,这主要是因为知识库上的一部分谓词具有等价形式,例如  和
和 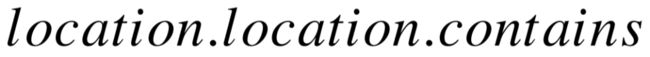 互为相反关系,对于这些关系,只需要依靠骨架结构就可以精确描述语义。对比两张表格可以发现,对于所有不同的模型和实验模式,自然语言关系上的主宾语预测结果都低于对应的知识库谓词上的结果。主要原因有两点:1) FB15k-37 上的每一个谓词平均包含接近千级别的训练三元组,而 PATTY-100 中的每个关系平均只有115个训练数据;2)自然语言关系具有更多歧义,开放式信息抽取的结果会包含多种语义,而且还要考虑抽取错误的情况,相比之下,知识库上的谓词及三元组的制定经过了部分人工干预,因此歧义更少。
互为相反关系,对于这些关系,只需要依靠骨架结构就可以精确描述语义。对比两张表格可以发现,对于所有不同的模型和实验模式,自然语言关系上的主宾语预测结果都低于对应的知识库谓词上的结果。主要原因有两点:1) FB15k-37 上的每一个谓词平均包含接近千级别的训练三元组,而 PATTY-100 中的每个关系平均只有115个训练数据;2)自然语言关系具有更多歧义,开放式信息抽取的结果会包含多种语义,而且还要考虑抽取错误的情况,相比之下,知识库上的谓词及三元组的制定经过了部分人工干预,因此歧义更少。

表4–5 在 PATTY-100 上进行主宾语预测的测评结果。

表4–6 在 FB15k-37 上进行主宾语预测任务的测评结果。
4.2.5.4 三元组分类任务测评
三元组分类任务的目标是预测一个未知三元组 ( , , ) 是否描述了一个正确的客观事实。考虑到这是个二分类任务,测试数据中需要包含负样本三元组,因此我们使用和 KALE [133] 相同的生成策略,对测试集和验证集中的每个三元组生成10个不同的负样本,其中5个三元组替换了主语,另外5个替换了宾语。为了保证负样本不至于显得 过于错误,我们保证用于替换的主语(或宾语)都曾出现在目标关系的某个已知三元组的同样位置上。
对于每一个目标关系,我们通过公式4–11计算各个未知三元组的似然值,以此作为置信度对所有测试集的所有正负样本进行排序。我们使用 FB15k 作为知识库进行了实验,并使用 MAP( Mean Average Precision )作为测评指标,衡量不同的模型在三元组分类任务上的效果。表4–7列出了 PATTY-100 和 FB15k-37 数据集上的效果,我们的模型在两个数据集上均大幅度优于其它方法。此外我们发现,仅生成简单模式图的方法效果要优于生成完整模式图的做法。我们对实验数据进行了分析,造成这个现象的原因源于负样本生成方式的天然缺陷。例如对于“ father of ”关系,我们期望负样本中能包含表示母子关系的实例,识别这种负样本需要较高难度,必须依靠额外限制才能和正样本进行区分。然而,负样本的生成方式决定了主语只能替换为某个随机小孩的父亲,判断三元组正确与否主要依靠骨架的正确性,因而很难体现模式图的额外限制为给语义理解带来的优势,减少候选模式图的数量和复杂度反而能得到更好的效果。
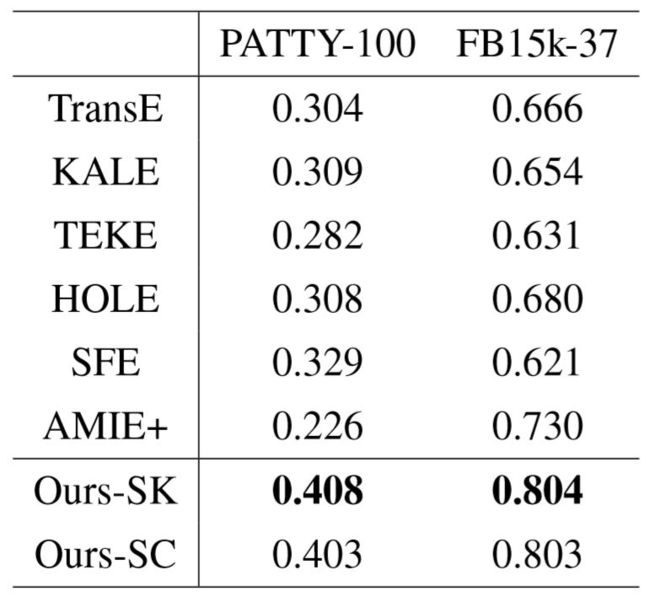
表4–7 三元组分类任务的 MAP 测评结果。
4.2.5.5 错误分析
对于一些自然语言关系,我们的模型可能难以寻找出较为正确的模式图。我们对结果进行了分析,并总结出以下几类主要错误。
1. 开放式信息抽取提供的关系三元组存在错误。考虑到 PATTY 主要利用依存语法分析对句子进行关系识别,语法分析本身的偏差将导致生成错误的三元组。例如对于关系 “ served as ”,给定句子 “ Dennison served as the 24th Governor of Ohio and as U.S. PostmasterGeneral... ”,PATTY 提取的实体对( William Dennison Jr.,Ohio )有误,正确的宾语应为“Governor of Ohio”。
2. PATTY 数据集中,每个关系实际代表着一个关系同义集,即由多个具有相似结构的关系组成的组合,这导致部分关系同义集混入了语法相似但语义不同的关系,产生本不存在的歧义。以 PATTY 中的关系同义集“ ’s wife ”为例,其中混入了少部分可能由 “ the wife of ” 产生的三元组,其中主语为妻子,宾语反而为丈夫。在混入的三元组干扰下,模型会误以为该关系的准确语义为不带有性别限制的配偶关系,因此正确的模式图很难获得较高的概率。
3. 对于部分关系,知识库本身缺乏用于描述其语义的谓词。对于一些琐碎的自然语言关系例如“ talk to ”,知识库显然不包含这类事实。但即便对于一些不那么琐碎的关系, 知识库依然可能缺乏必要的谓词。例如关系“ ( singer ) performed in ( LOC ) ”描述的是歌手和演唱会举办地的联系,但Freebase 中并不包含类似于 place_visited 或 hold_concerts_in 的谓词,因此难以通过已有知识表示目标关系的语义。
4. 由于搜索空间的限制,部分有意义的模式图无法在候选生成步骤被过滤。例如关系“ ( actor ) starring with ( actor ) ”,由于 Freebase 通过辅助节点( Mediator )维护多元关系,这使得最合适的骨架长度为4,并不满足候选生成的骨架长度限制,因此模型无法得到这样的模式图。
4.3 本章小结
本章的研究着眼于自然语言中的二元关系,根据关系已有的三元组实例,推理出其所具有的语义。第一部分的工作将关系模式定义为知识库中的主宾语类型搭配,并利用知识库的类型层次结构实现模式推理。我们提出的方法基于一个直观的思路,即尽可能使用具体的模式匹配更多的已知实例。在 ReVerb 上进行的人工测评实验表明,此方法推理出的最具有代表性的模式具有较高的准确度,效果优于传统的选择偏好模型。
第二部分的工作直接挖掘关系语义和结构化知识之间的匹配。为了使语义理解具有良好的可解释性,我们提出了基于模式图的规则推导模型,模式图是对传统路径规则的泛化,以 “路径 + 分支” 的结构描述具有更多限制的复杂语义。该模型将关系语义表示为多个模式图的概率分布,以适应关系的多义性。我们对 PATTY 中的热门关系进行模式图推理,多个具体例子表明,基于模式图的结构表示有能力描述更加细化的关系语义,而且质量优于其它已有的规则推导模型。此外,基于模式图的语义表示还可用于知识库补全任务中,在主宾语预测和三元组分类两个子任务上,效果优于其它规则推导及知识库向量模型。
后续的研究主要包括两部分:数据预处理方面,关系三元组的实体链接需要优化, 主语和宾语都可能存在不可链接实体,需要进行识别从而过滤杂乱三元组;语义理解模型方面,本章的两个工作均基于数据驱动,对于已知三元组较少的长尾关系,模型效果会明显降低,如何利用关系本身的短语信息作为额外特征进行推理,是值得研究的方向。
参考文献:
(文中提及的部分参考文献在01#02#)




了解更多信息请点击知识工场网站主页:http://kw.fudan.edu.cn/
合作意向、反馈建议请联系:
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。