周志华-机器学习-笔记(一)-模型评估与选择(上)
经验误差与过拟合
任何一个学习器都会有误差,我们把分类错误的样品数占样品总数的比例称为“错误率”(error rate)。把学习器在训练集上的误差称为“训练误差”(training error)或“经验误差”(empirical error),在新样品上的误差成为“泛化误差”(generalization error)。事实上,我们期望泛化误差小的学习器。
“过拟合”(overfitting)是现对于“欠拟合”(underfitting)的概念,下面图片就是对这两个概念的对比。
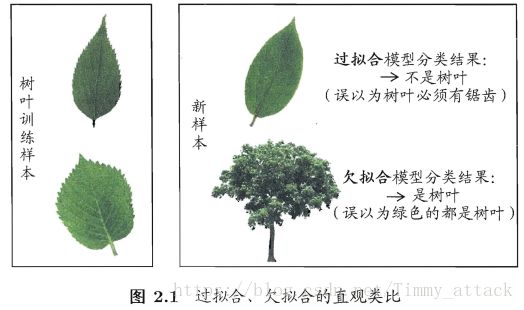
在实际问题中,对于欠拟合问题比较容易克服,例如在决策树学习中扩展分支、在神经网络学习中增加训练轮数等。而过拟合则很麻烦。
在现实任务中,我们往往有很多种学习算法可以选择,甚至对同一个学习算法使用不同配置参数时,也会产生不同的模型。这时就涉及到机器学习中的“模型选择”(model selection)问题。理想的解决方案是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。
评估方法
一般来说,我们只有一个包含m个样例的数据集D={(x1,y1),(x2,y2),…,(xm,ym)},但我们既需要训练,又要测试。所以常用的做法是,将数据集D划分出训练集S和测试集T。对此常用3种方法:
留出法
“留出法”直接将数据集D划分为两个互斥的集合,大的集合作为训练集S,小的集合作为测试集T,即S和T的并集为D,交集为空集。
此处有两个需要注意的问题:
一是,训练集和测试集的划分要尽可能保持数据分布的一致性,避免引入额外的偏差而对最终的结果产生影响。通常采用“分层采样”(stratified sampling)来保留类别比例。若D包含500个正例、500个反例,则分层采样S得到350个正例、350个反例,而T得到150个正例、150个反例。
二是,即便给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据集D进行分割。例如,上面的例子中,可以把350个正例放到训练集也可以放到测试集。所以,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
交叉验证法
“交叉验证法”(cross validation)先将数据集D通过分层采用划分为k个大小相似的互斥子集,每个子集都尽可能保持数据分布的一致性。然后,每次用k-1个子集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/测试集,用来进行k次训练和测试,取这k个测试结果的均值。
通常把交叉验证法称为“k折交叉验证”(k-fold cross validation)。k最常取值是10,此时称为10折交叉验证;其他常用取值是5、20等。下图给出10折交叉验证的示意图:

为了减少因样品划分不同而引入的差别,k折交叉验证通常要随即使用不同的划分重复p次,最终的评估结果是这次p次k折交叉验证结果的均值。例如常见的有“10次10折交叉验证”
当数据集D中包含m个样本,若令k=m,则得到交叉验证法的一个特例:留一发(Leave-One-Out,简称LOO)。留一法中被实际评估的模型与期望评估的用D训练出的模型很相似。但留一法的缺点是数据集大时,训练开销难以忍受。
自助法
“自助法”(bootstrapping)在数据集较小、难以有效划分训练/测试集时很有用。它既可以减少训练样本规模不同造成的影响,同时还能比较高效地进行实验估计。
给定包含m个演变的数据集D,我们对它进行采样产生数据集D`:每次随即从D中挑选一个样品,将其拷贝放到D`然后再将该样片放回初始数据集D中,使该样片可以被下次采样时可能采到。这样的结果是,D中有一部分样片会在D`中重复出现,有部分样片却不出现。样片在m次采样中始终不被采到的概率是:

于是乎,通过自助采样,我们就拥有训练集D`,并且将D-D`作为测试集。这样,实际评估的模型与期望评估的模型都使用m个训练样本,而仍有1/3的没有出现在训练集的样片进行测试。这样的测试结果,亦称“包外估计”(out-of-bag estimate)。
调参与最终模型
大多数学习算法都有些参数需要设定,参数配置不同,学得模型的性能往往有显著差别。
在模型选择完成后,学习算法和参数配置已经选定,此时用数据集D重新训练模型。这个模型在训练过程中使用了所有m个样片,这才是我们最终提交给用户的模型。
性能评估
性能评估(performance measure)就是衡量模型泛化能力的评价标准。分类任务的性能度量有常用的几种:
“错误率和精度”、“查准率、查全率与F1”、“ROC与AUC”、“代价敏感错误率与代价曲线”
查准率、查全率与F1
查准率与查全率

通俗来说,查准率P是学习器预测的准确程度;查全率R是正例中被预测正确的比例。
F1度量
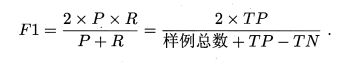
在一些应用中,对查准率和查全率的重视程度有所不同。但我们需要表达出查准率/查全率的不同偏好时,我们采用F1度量的一般形式—— Fβ F β
其中 β>0 β > 0 度量了查全率对查准率的相对重要性。 β=1 β = 1 时退化为标准的F1; β>1 β > 1 时查全率有更大影响; β<1 β < 1 时查准率有更大影响。
很多时候我们进行多次训练/测试,或者在多个数据集上进行训练/测试,就会有多个二分类混淆矩阵,希望估计算法的“全局”性能,一种直接的做法是算出各混淆矩阵的查准率和查全率,记为 (P1,R1) ( P 1 , R 1 ) , (P2,R2) ( P 2 , R 2 ) ,…, (Pn,Rn) ( P n , R n ) ,计算其平均值就得到“宏查准率”(macro-P),“宏查全率”(macro-R),“宏F1”(macro-F1):

另一种做法是将混淆矩阵的对应元素进行平均,得到TP、FP、TN、FN的平均值,分别记为 TP¯¯¯¯¯¯¯ T P ¯ 、 FP¯¯¯¯¯¯¯¯ F P ¯ 、 TP=N¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ T P = N ¯ 、 FN¯¯¯¯¯¯¯¯ F N ¯ ,再算出“微查准率”(micro-P)、“微查全率”(micro-R)、“微F1”(micro-F1):
ROC与AUC
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,它与P-R曲线相似,但ROC曲线的横轴是“假正例率”(False Positive Rate),纵轴是(True Positive Rate),两者分别定义为:
以下给出一个示意图。

AUC(Area Unser ROC Curce)
绘图过程:给定 m+ m + 个正例和 m− m − 个反例,根据学习器预测结果对样例进行排序,然后将分类阀值设为最大,即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)处标记一个点。然后,将分类阀值依次设为每个样例的预测值,即依次将每个样例划分为正例。
代价敏感错误率与代价曲线
由于不同的错误所造成的损失不同,故为了衡量不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)。
以二分类的“代价矩阵”(cost matrix)为例, costij c o s t i j 表示将第 i i 类样本预测为第 j j 类样本的代价。如下图:

若将表2.2中的第0类作为正类、第1类作为反类,令 D+ D + 与 D− D − 分别代表样例集D的正例子集和反例子集,则“代价敏感”(cost-sensitive)错误率为
(若令 costij c o s t i j 中的 i i 、 j j 取值不限于0、1,则可定义出多分类任务的代价敏感性能度量。)
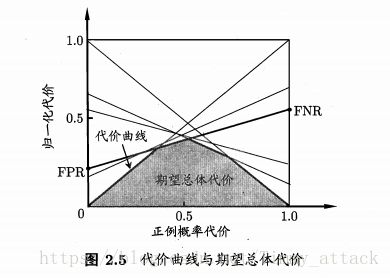
在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而“代价曲线”(cost curve)则可达到该目的。代价曲线图横轴是取值为[0,1]的 正例概率代价:
(其中 p p 是样例为正例的概率)
纵轴是取值为[0,1]的 归一化代价:
(其中 FPR F P R 是假正例率 FPR=FPTN+FP F P R = F P T N + F P , FNR=1−FPR F N R = 1 − F P R 是假反例率; costnorm是归一化(normalization)后的值 c o s t n o r m 是 归 一 化 ( n o r m a l i z a t i o n ) 后 的 值 )
代价曲线的绘制:ROC曲线上每一个点对应了代价平面上的一条线段,设ROC曲线上点的坐标为 (TPR,FPR) ( T P R , F P R ) ,则可相应计算出FNR,然后在代价平面上绘制一条从 (0,FPR) ( 0 , F P R ) 到(1,FNR)的线段,线段下的面积即代表了该条件下的期望总体代价;如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如下: