表格数据常用操作记录
以前不屑于记录科研生活中常用的一些命令行代码,因为觉得即学即用即可,没必要专门记录,但发现要用的时候还是要百度学习两三个网页才行,十分费时费力,所以我选择花点时间整理下来。
1.读取excel或者csv
X=pd.read_csv("K:/MustToDo/PredictionTask/ex1/CompleteDataset/All.csv",index_col=0)这里解释一下,index_col这个参数表示的是行索引所使用的列序数,当表格数据第一列是索引而没有真实含义时(保存的时候把数据框的原索引一起保存了),指定index_col=0即可,这样读取就不会出现unnamed的字段,还有就是文件地址最好不要含有中文字符。还有编码问题,如果数据框原来显示正常,使用to_csv等内置函数保存后再读取基本没问题,也不用特别设置编码,如果要用excel打开的话最好设置一下编码方式。
2.绘图的整饰元素
图标中有中文的最好加这一句,否则会乱码
chinese =matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simkai.ttf')下面几个是横轴、纵轴、图例、标题的整饰代码
plt.xlim(1992,2015)
plt.ylim(min_y-100,max_y+1e5)
#设置x轴刻度
plt.xticks(np.arange(1992,2017,1))
plt.xlabel()
#设置图例
plt.legend(legends,labels,loc='best',prop=chinese)
plt.title("普通小学分省招生人数折线图",fontproperties=chinese)代码中legends和labels来自:
for colname in transposed_items.columns[1:]:
indices=transposed_items[colname].index
y=[]
x=[]
for index in indices:
if "GDP" in index:
y.append(transposed_items[colname][index])
x.append(int(index[3:]))
min_y=min(min_y,min(y))
max_y=max(max_y,max(y))
print(colname+' && '+index)
print(max_y)
plt.scatter(x,y)
legend,=plt.plot(x,y)
legends.append(legend)
labels.append(colname)这里解释一下:plt.plot()绘图命令类似于搭积木,一层一层往图上面叠放。
3.绘制折线图:
min_y=1e20
max_y=-1
legends=[]
labels=[]
'''
@featureName为列名,即要对某一列特征绘制折线图
@plotName为图名
'''
def plot_line_chart(featureName,plotName):
global min_y,max_y,legends,labels
for colname in transposed_items.columns[1:]:
indices = transposed_items[colname].index
y = []
x = []
for index in indices:
if featureName in index:
y.append(transposed_items[colname][index])
x.append(int(index[len(featureName):]))
min_y = min(min_y, min(y))
max_y = max(max_y, max(y))
print(colname + ' && ' + index)
print(max_y)
plt.scatter(x, y)
legend, = plt.plot(x, y)
legends.append(legend)
labels.append(colname)
plt.xlim(1992, 2019)
plt.xticks(np.arange(1992, 2019, 1))
plt.legend(legends, labels, loc='best', prop=chinese)
plt.title(plotName, fontproperties=chinese)
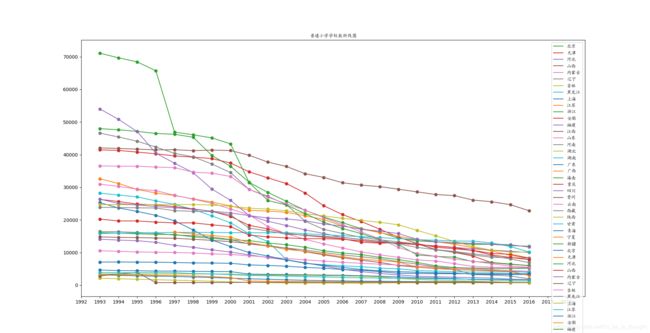

4.绘制箱线图,这里有一个感觉不错的模板,把四分位点和均值、中值都标注在图里了。
def plot_box_graph(feature_name,plotName):
box_list = [items[feature_name + str(year)][1:].dropna() for year in range(1993, 2015)]
plt.boxplot(box_list, patch_artist=True, labels=[i for i in range(1993, 2015)], notch=True,
sym='*', showmeans=True, boxprops={'color': 'black', 'facecolor': '#9999ff'},
flierprops={'marker': 'o', 'markerfacecolor': 'red', 'color': 'black'},
meanprops={'marker': 'D', 'markerfacecolor': 'indianred'},
medianprops={'linestyle': '--', 'color': 'orange'})
plt.title(plotName, fontproperties=chinese)
plt.xlim(1992, 2015)
# 设置x轴刻度
plt.xticks(np.arange(1992, 2015, 1))
这里的boxlist需要解释一下,boxlist的每个元素都是该箱线图的每个box里的一系列数据,后面的都是建议参数不赘述。
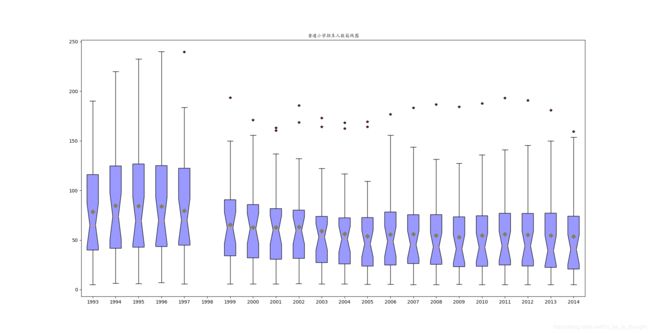
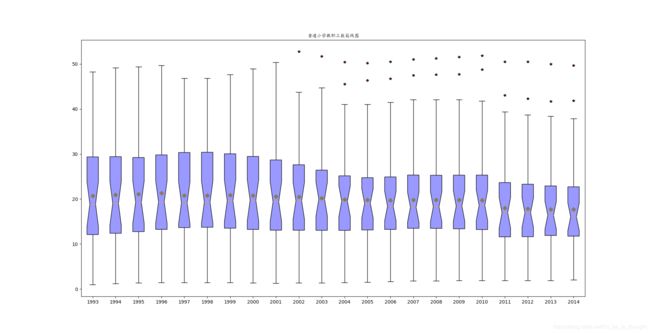
5.即时保存(这个要说三遍)
实验有时做到一半,中间数据结构不太适合保存为csv,可以使用pickle来序列化,读取时直接反序列化读取就是那个中间数据结构。代码如下:
#训练集测试集格式化存储
import pickle as pk
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/X_train.pk','wb') as f:
pk.dump(X_train,f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/X_test.pk','wb') as f:
pk.dump(X_test,f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/y_train.pk','wb') as f:
pk.dump(y_train,f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/y_test.pk','wb') as f:
pk.dump(y_test,f)
#训练集测试集格式化读取
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/X_train.pk','rb') as f:
X_train=pk.load(f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/y_train.pk','rb') as f:
y_train=pk.load(f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/X_test.pk','rb') as f:
X_test=pk.load(f)
with open('K:/MustToDo/PredictionTask/ex1/CompleteDataset/y_test.pk','rb') as f:
y_test=pk.load(f)未完待续。