YOLO V1的过程解读
you only look once!!!
一、所需基本姿势
1、YOLO将图片分成S*S的grid cell,每个grid cell对应B个bounding box,论文S=7,B=2,故有98个bbox。
2、YOLO中每一个Object只对应一个中心点,该中心点只唯一出现在一个grid cell中
3、Object中心点落在的那个grid cell负责把该Object回归出,彻底不是选取proposal再看看这个合不合适的模式
二、TRAINING
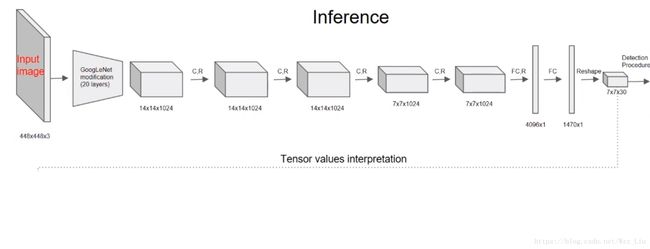
如图输入为448*448*3,经过类似GoogLenet的只有1*1和3*3的卷积后,得到7*7*30的feature,显然7*7对应每一个grid cell,而30个channel呢?

如图,30个channel对应2个bbox的5个位置信息和confidence,confidence是它是否是Object的概率乘上最大的IoU(当有Object的中心点在该grid cell上,则Pr(Object)=1,否者为0);再加上20个class的feature。
loss分析
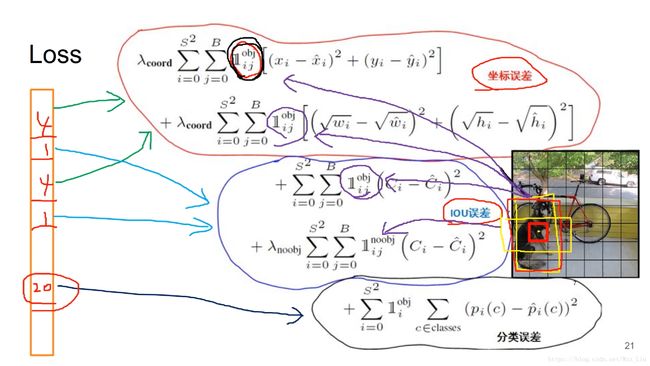
loss分3部分,坐标+confidence+class的loss
第一部分坐标loss,类似1的符号表示只找一个对每一个Object负责的bbox(大概类似1的符号就这意思吧 - - ),如图对狗来说,只有中心点所在的grid cell的竖向的黄框对其负责,前面两个求和,表示对所有bbox进行了遍历。
注:为什么要对w和h加上根号?因为大物体的w和h比小物体大得多,权衡两者,使大物体和小物体对loss贡献相一致(效果然并卵 - -),lamda的选择也是考虑到对loss的贡献率(论文更为重视坐标loss,lamda取很大,为5)
第二部分IoU loss,C就是confidence值,第一个等式也是要找只找一个对每一个Object负责的bbox,第二个等式变成了no obj了,说明遍历了所有除第一个等式找到的bbox外的所有bbox,且加上了一个lamda系数,为的是不让负例太多了!
第三部分是class loss,遍历所有bbox,但只对c∈classes的bbox(第二个求和符号的意义)计算了分类loss
OK!
三、TESTING
网络训练好后,输入一张图片,得到98个bbox的结果,其中有class和confidence和位置
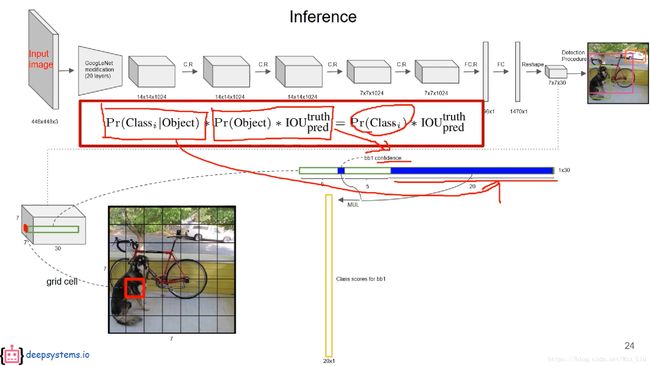
class的概率显然是一个条件概率,与前面的confidence相乘,得到真正Pr(Classi)*IoU,对所有98个bbox都进行这些操作,得到98个20*1的class scores,再针对某一个Object的scores进行降序排列,再讲小于某个阈值的scores清零,在进行NMS操作得到对应的98个20*1的class scores。
解释:为什么有可能要进行NMS,因为每一个grid cell不止生成了一个bbox。拿狗狗举例,有可能有多条狗在图中(当然这不是关键)
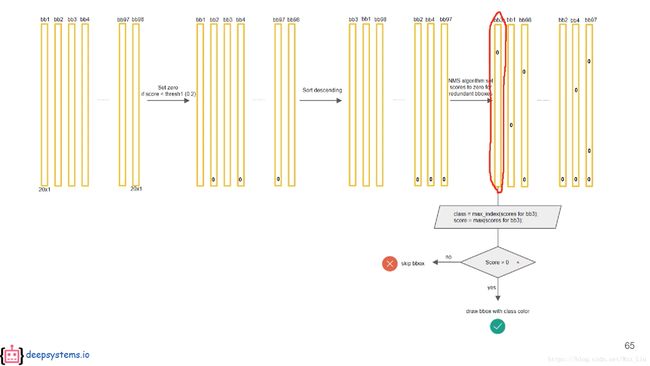
对其中一个bbox的class scores查找其最大的scores,如果大于0,这标记bbox为结果,并染色输出;没有则放弃该bbox。
解释:引文confidence的存在,使得大部分的scores都是0,如果最大都是0,说明该bbox对应的grid cell不是任何的Object的中心点。
思考
同一个grid cell可能同时出现两个相同的class的bbox!
原因:当同一个grid cell对应的2个bbox的IoU小于某个阈值即可。
而不可能同一个grid cell中出现两个不同的class的bbox!
原因:因为在计算每个bbox的class scores时,是将每个grid cell的Pr(Classi | Object)和前面两个bbox的confidence相乘,所以属于同一个grid cell的bbox每个类的class scores大小关系是一样的。
正因为有这个缺点,YOLO V1对一个grid cell里有多个目标的情况无能为力,这也是为什么YOLO V1对小物体准确率不高的原因关键!!!
四、conclusion
1.因为很暴力的直接在网格(最后一层feature)上选bbox,Object中心点落在的那个grid cell负责把该Object回归出;而不用像faster-rcnn一样有一个siding windows的多余操作来提取proposal再筛选哪些适合作为bbox,所以要快很多!
2.由联合损失函数softmax+smooth变成了一个自己定义的loss function
YOLO v1的精准性和召回率相对于fast-rcnn比较差。其对背景的误判率比fast-rcnn的误判率低很多。这说明了YOLO v1中把物体检测的思路转成回归问题的思路有较好的准确率,但是对于bounding box的定位不是很好。