超详细 Hadoop2.0高可用集群搭建方案
Hadoop完全分布式中的概念
在Hadoop 完全分布式的安装配置中,可以配置多个Namenode(两个)形成互为热备的状态,解决Namenode单节点故障的问题两个Namenode 直接通过JN集群来共享数据,基本原理和Zookeeper类似,处于Active状态的Namenode 通过将元数据的更新发送给大部分JN机器,保证只要JN集群大部分的机器存活,处于StandBy状态的Namenode可以同步这些元数据,两个Namenode 通过Zookeeper实现选举,这个选举过程是由FailOverController来具体执行的。

NameNode(Active):真正在工作状态的NameNode,保持着元数据,并将元数据的更新信息写入JN
NameNode(Standby):处在备用装填的NameNode,从JN中获取信息,同步元数据。
DataNode:保存数据的节点
JN集群:用来同步元数据的集群,为了防止单节点故障,做成了集群。
Zookeeper:负责集群协调,包括NameNode的选举
FailOverController:联系NameNode和Zookeeper的进程
Hadoop完全分布式集群规划
Hadoop 集群模式的安装规则
1,两个Namenode 一般单独安装
2,FailOverController的进程必须和Namenode装在一起
3,ResourceManager 一般单独安装和NameNode安装在一起
4,Datanode 单独安装
5,NodeManager一般和Datanode装在一起
6,JN要么单独装,要么和DataNode装在一起
7,Zookeeper通常是一个单独的集群,如果没有条件也可以配置在hadoop集群中
五台机器的情况下
hadoop01
NameNode(activer)
ResourceManager (activer)
FailOverController
Zookeeper
hadoop02
NameNode (Standby)
ResourceManager (Standby)
FailOverController
Zookeeper
hadoop03
DataNode
NodeManager
JN
Zookeeper
hadoop04
DataNode
NodeManager
JN
hadoop05
DataNode
NodeManager
JN
三台机器的情况下
hadoop01
Namenode
ResourceManager
FailOverController
DataNode
NodeManager
JN
Zookeeper
hadoop02
Namenode
ResourceManager
FailOverController
Datanode
NodeManager
JN
Zookeeper
hadoop03
DataNode
NodeManager
JN
Zookeeper
环境:五台centos6.5虚拟机
准备工作:
1,修改主机名 :vim /etc/sysconfig/network , 将五台虚拟机的主机名都改为hadoop01----hadoop05,
保存退出后 输入 hostname hadoop01 使其生效

2, 修改host文件 :vim /etc/hosts (windows 最好也配置一下host文件)

3, 关闭防火墙 : chkconfig iptables off,
输入 chkconfig --list iptables 查看防火墙是否关闭

4,配置ssh免密登陆
在hadoop01 机器上输入 ssh-keygen 一路点击三个回车即可 ,
然后输入 ssh-copy-id root@hadoop01 依次将该密钥发送到hadoop01到hadoop05上
然后按照上述步骤 配置 hadoop02,hadoop03,hadoop04,hadoop05
如果配置成功 我们直接可以使用 ssh 主机名 即可登陆其他主机 例如连接 hadoop02 直接输入 ssh hadoop02 即可
输入exits 即可退出连接
5,安装jdk
将安装包上传到相应的文件夹下 解压 tar -zxvf 安装包名字
然后配置环境变量 : vim /etc/profile

配置完成后 输入 source /etc/profile 使环境变量生效
然后再输入 java -version 如果和截图中一样 说明jdk配置生效了

6, 配置zookeeper
【1】首先将zookeeper的安装包上传到linux的相关文件夹下 然后解压, 配置zookeeper环境变量(看jdk环境变量的截图)
【2】然后进入zookeeper的conf目录中 其中有一个zoo_sample.cfg的配置文件,这个一个配置模板文件,我们需要复制 这个文件,并重命名为 zoo.cfg。zoo.cfg才是真正的配置文件 命令 :mv zoo_sample.cfg zoo.cfg
【3】 dataDir。这个参数是存放zookeeper集群环境配置信息的。这个参数默然是配置在 /tmp/zookeeper下的 。但是注意, tmp是一个临时文件夹,这个是linux自带的一个目录,是linux本身用于存放临时文件用的目录。但是这个目录极有可能被清空,所以,重要的文件一定不要存在这个目录下。所以改成:/home/softwares/zookeeper-3.4.7/tmp

在配置文件中加入以下配置

①server是关键字,写死
②后面的数字是选举id,在zk集群的选举过程中会用到。
说明:2888原子广播端口,3888选举端口
zookeeper有几个节点,就配置几个server,
③配置文件配置好,需要在dataDir目录下创建一个文件
vim myid 输入 1 保存退出即可
然后 将zookeeper 远程拷贝给hadoop02 ,hadoop03
scp -r /home/software/zookeeper-3.4.7 root@hadoop02:/home/software
然后将hadoop02 和hadoop03中的myid 文件中的数字改为 2和3
启动zookeeper zkServer.sh start ,然后 输入zkServer.sh status 查看zookeeper 的状态
7,上传hadoop的安装包 然后解压 进行配置
【1】cd /home/software/hadoop-2.7.1x/etc/hadoop/ 进入到该目录下
配置hadoop-env.sh 这个文件 ,添加jdk的地址

【2】 配置core-site.xml
【3】配置 hdfs-site.xml 这个文件
【4】配置mapred-site.xml
该文件一开始是没有的 需要复制 mapred-site.xml.template 这个文件并且重命名为 mapred-site.xml
【5】配置yarn-site.xml
【5】12.配置slaves文件(salves中是配置datanode所在的节点)
hadoop04
hadoop05
hadoop06
【6】根据配置文件,创建相关的文件夹,用来存放对应数据
在hadoop-2.7.1x 目录下创建
①创建tmp目录
②journal目录
③在tmp目录下,创建hdfs文件夹 并在hdfs下创建name和data文件夹
【7】通过scp 命令,将hadoop安装目录远程copy到其他4台机器上
比如向hadoop02节点传输:
scp -r hadoop-2.7.1x root@hadoop02:/home/software
Hadoop集群的启动
【1】第一步启动zookeeper集群 zkServer.sh statrt
【2】 格式化zookeeper
在zk的leader节点上执行:hdfs zkfc -formatZK,这个指令的作用是在zookeeper集群上生成hadoop-ha节点(ns节点)
格式化完毕后 如果出现 Successfully created /hadoop-ha/ns in ZK. 说明格式化成功了
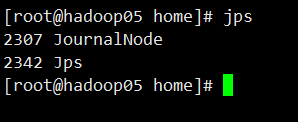
【3】启动JN集群
sh hadoop-daemons.sh start journalnode
然后在hadoop03,hadoop04,hadoop05,中查看是否启动了journalndoe
【4】格式化namenode 节点(第一次启动时)
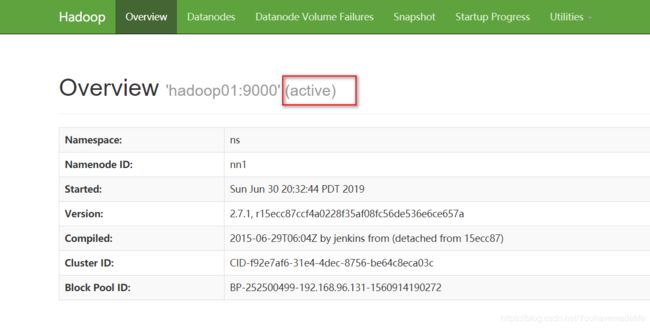
在Active NameNode节点运行
hdfs namenode -format
在Activ NameNode (hadoop01)节点运行
hadoop-daemon.sh start namenode
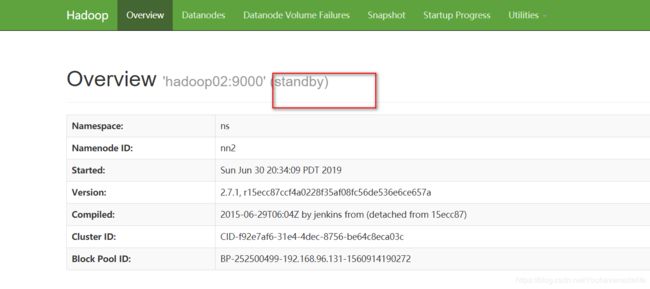
【5】在standby NameNode (hadoop02)节点运行
hdfs namenode –bootStrapStandby(第一次启动时)
hadoop-daemon.sh start namenode
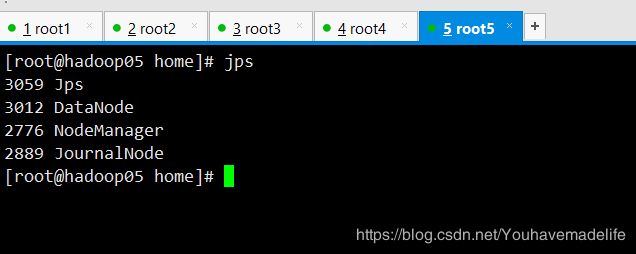
【6】启动DataNode (在hadoop03,hadoop04,hadoop05)
在ActiveNameNode节点上运行
hadoop-daemons.sh start datanode
【7】启动zkfc(启动FalioverControllerActive)
在hadoop01,hadoop02节点上执行:
hadoop-daemon.sh start zkfc
【8】在hadoop01节点上启动 主Resourcemanager
在01节点上执行:start-yarn.sh
启动成功后,hadoop03,hadoop04,hadoop05节点上应该有NodeManager 的进程
【9】在hadoop02 节点上启动副 Resoucemanager
在02节点上执行:yarn-daemon.sh start resourcemanager
上述命令输入完后 我们依次看一下每个节点
haoop01

hadoop02

hadoop03
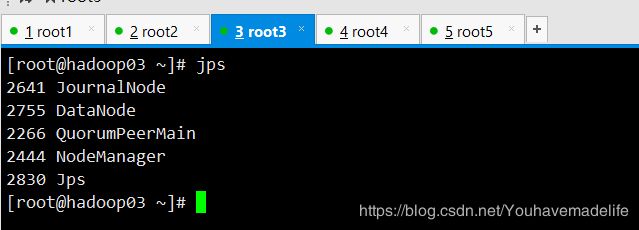
hadoop04

hadoop05