深度学习实战(一)快速理解实现风格迁移
前言
Gatys大神之前发表了一篇利用风格迁移进行作画的文章,让普通的照片具有名人的画风,效果如下:

让一篇普通的图片有了梵高的风格,厉害了。
文章链接:A Neural Algorithm of Artistic Style
其实我们也可以利用风格迁移实现自己的风格,比如本文实现的国画风格。难点在于很多国画背景与内容色差并没西方画作那么明显,有的仅用淡墨,黑白两色就可以完成。这样给风格迁移学习带来较大困难,不过通过调节学习速率和损失函数也可以实现很好的学习效果。比如本文实现的国画风格:



风格迁移1. 马



风格迁移2. 山水
是不是很有意思!接下来我们就一起来理解实现风格迁移。
实现风格迁移主要依赖于
• torch7
• loadcaffe
• VGG-19 model
可选:
CUDA ,cuDNN,OpenCL
安装相关平台还是蛮麻烦的, 需要 protobuf, loadcaffe, torch 三件套。而且有些 trick ,比如 lua 版本要足够新否则会有包安装不上的问题 (luarocks),需要查询相关安装说明,github issue 以及 FAQ 耐心解决。
相关代码整理在我的GitHub上,感兴趣的同学可以直接克隆下来调试玩一玩。
GitHub地址:https://github.com/TONYCHANBB/Chinese_painting-style
原理
回到原理上来,作者定义了两个损失函数:style loss 和 content loss,回到文章初始的图上来

将图a的style loss 和 图p的content loss 组合起来,最小化total loss function求得x
其中, α α , β β 对应两个loss的权重,调节它们会得到不同的效果。
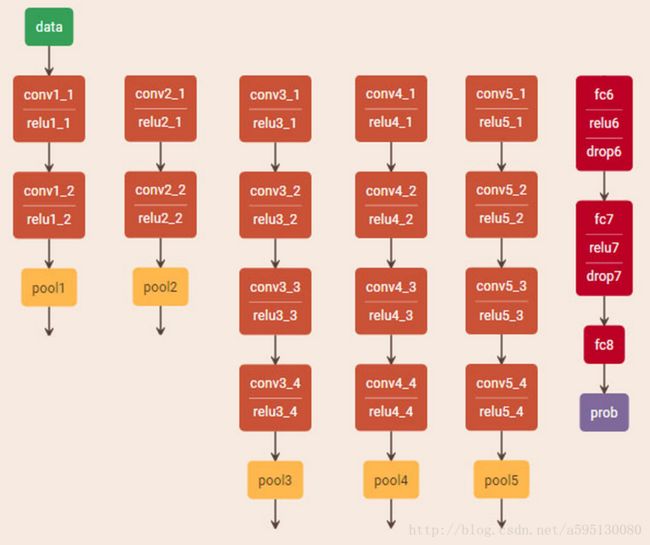
如何得到两个损失函数和内容风格重建呢呢,我们回到网络结构上来,作者利用了VGG-Network16个卷积层和5个池化层,没有用全连接层,采用的平均池化。(文末有VGG的网络结构图)
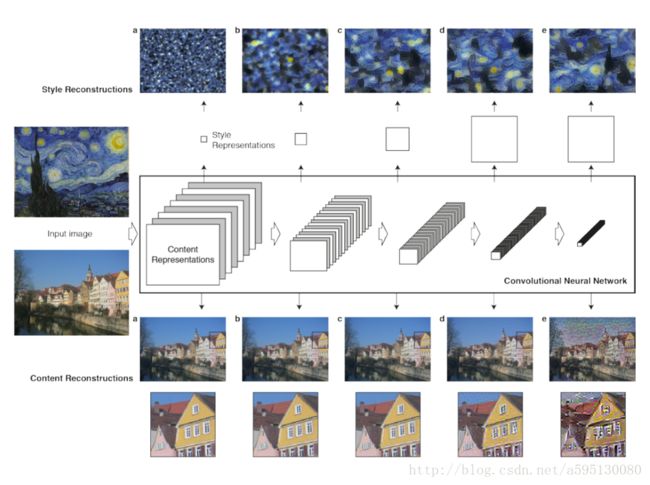
对于内容重建来说,用了原始网络的五个卷积层,‘conv1_1’ (a), ‘conv2_1’ (b), ‘conv3_1’ (c), ‘conv4_1’ (d) and ‘conv5_1’ (e),即图下方中的a、b、c、d、e。VGG 网络主要用来做内容识别,在实践中作者发现,使用前三层a、b、c已经能够达到比较好的内容重建工作,d、e两层保留了一些比较高层的特征,丢失了一些细节。
对于风格重建,用了卷积层的不同子集:
‘conv1_1’ (a),
‘conv1_1’ and ‘conv2_1’ (b),
‘conv1_1’, ‘conv2_1’ and ‘conv3_1’ (c),
‘conv1_1’, ‘conv2_1’ , ‘conv3_1’and ‘conv4_1’ (d),
‘conv1_1’, ‘conv2_1’ , ‘conv3_1’, ‘conv4_1’and ‘conv5_1’ (e)
这样构建网络可以忽略图像的内容,保留风格。
内容损失函数:
Lcontent L c o n t e n t 采用平方损失函数,为每个像素的损失和
Flij F i j l 为第 l l 层第 i i 个卷积的第 j j 个位置的特征表示,用来代表内容, P P 为某图像该位置的特征表示, x x 为想形成的目标图像。
我们可以这样理解,首先对待提取内容的图片p得到该位置的内容表示 P P ,可以构造一个图像 x x 在该位置的特征无限趋近于 P P ,使得内容损失函数最小,我们的目标就是找到这个在内容上无限接近 P P 的 x x .
如何找到它呢?作者对 x x 生成一个白噪声图像,然后利用经典的梯度下降法Find it。
损失函数的导数为:
注意由于VGG使用 ReLu作为 activation layer,所以导数分段, F F 小于0,导数为0. Lcontent L c o n t e n t 为各层损失求和。
风格损失函数:
风格损失函数理解上与内容损失函数相同,只是利用了不同层相应的组合表示,作者对于每一层的相应建立了一个格莱姆矩阵 G G 表示他们的特征关联,
l l 层的损失为:
其中 A A 为原始图像在 l l 层的表示。
则风格损失函数的表示为:
Wl W l 为每层的权重。
导数为:
则总的损失函数为
就是文初的给出的公式,我们最小化这个损失函数就可以了。
值得注意的,这里优化的参数不再是网络的 w w 和 b b ,而是初始输入的一张白噪声图片 x x 。
了解原理后我们就可以大干一场了!首先可以把GitHub上代码clone或下载下来,先运行一遍,保证没有问题,理解原理和代码后就可以修改参数,制作我们自己的风格了!
Tips:
(1) 注意我们还需要下载VGG模型(放在当前项目下),运行时记得模型的路径改成自己的当前路径
(2) 我们可以调参,更改优化算法,甚至网络结构,尝试看会不会得到更好的效果,而且我们还可以做视频的风格转化哦
(3) neural style 无法保存训练好的模型,每次转换风格都要重新跑一遍,时间很长很长,推荐大家安装GPU的TensorFlow。
(4) 斯坦福的李飞飞大牛发了一篇《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》,通过使用perceptual loss来替代per-pixels loss使用pre-trained的vgg model来简化原先的loss计算,增加一个transform Network,直接生成Content image的style。感兴趣的朋友也可以研究下,做些好玩的事。
VGG-Network结构:
最后,希望能给大家带来帮助,如果你喜欢,给个star哈,欢迎大家在GitHub上把优化和有趣的实现推过来,我们来一起做点好玩的事!
参考链接:
深度学习实战(一)快速理解实现风格迁移
A Neural Algorithm of Artistic Style
neural-style
torch7
loadcaffe
VGG-19 model