tensorflow2.0笔记12:梯度下降、函数优化实战、手写数字问题实战以及Tensorboard可视化!
| 梯度下降、函数优化实战、手写数字问题实战以及Tensorboard可视化! |
文章目录
- 一、梯度下降
- 1.1、什么是梯度?
- 1.2、梯度到底代表什么意思?
- 1.3、如何搜索loss最小值
- 1.4、tensorflow自动求导机制
- 1.4.1、补充知识:二阶梯度!
- 二、函数优化实战
- 2.1、绘制函数图像
- 2.2、使用梯度下降(重要!)
- 三、手写数字问题实战
- 3.1、fashionmnist数据集训练过程
- 3.2、加上测试过程
- 3.1、mnist数据集测试结果
- 四、Tensorboard可视化
- 4.1、tensorboard的安装以及工作原理
- 4.1、第一步:run listener
- 4.2、第二步:build summary
- 4.3、第三步:fed scalar
- 4.4、第三步2:fed single image
- 4.4、第三步3:fed muti-images
- 4.2、代码演示
一、梯度下降

1.1、什么是梯度?

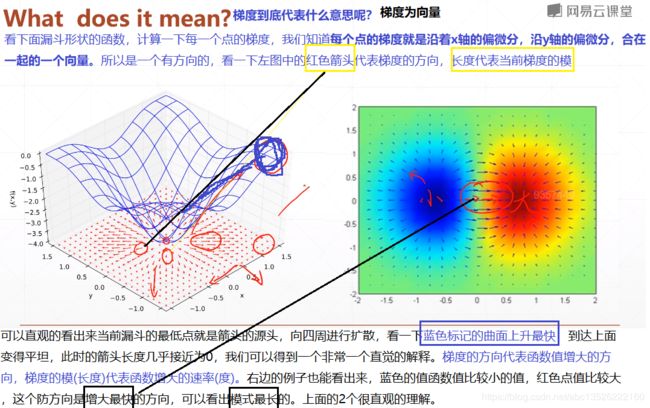
1.2、梯度到底代表什么意思?
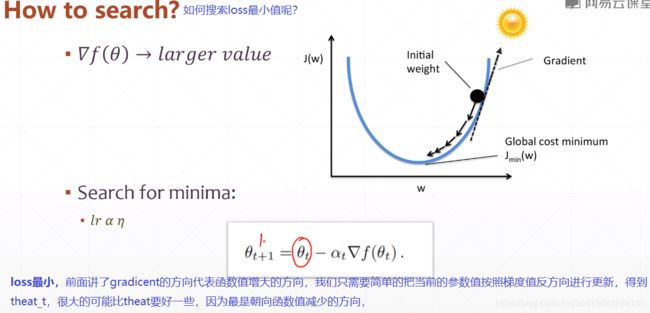
1.3、如何搜索loss最小值
1.4、tensorflow自动求导机制

- 具体实例如下:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
w = tf.constant(1.)
x = tf.constant(2.) #注意这里只能是浮点数,是整数的话结果返回None。
y = x*w
#梯度的计算过程要包在这个里面。
with tf.GradientTape() as tape:
tape.watch([w])
y2 = x*w
#[grad1] = tape.gradient(y, [w]) #这里参数[w]为list列表。最终返回的也是list类型。
#print(grad1) #这里返回的为None,为什么呢?因为tape.gradient()中药求解的y,并没有包在里面,而是y2
[grad2] = tape.gradient(y2, [w]) #这里参数[w]为list列表。最终返回的也是list类型。y2放进去了
print(grad2)
- 运行结果:
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2.0/bin/python -u /home/zhangkf/tmp/pycharm_project_258/demo/TF2/out.py
None
Process finished with exit code 0
- 注意下面这个:

1.4.1、补充知识:二阶梯度!

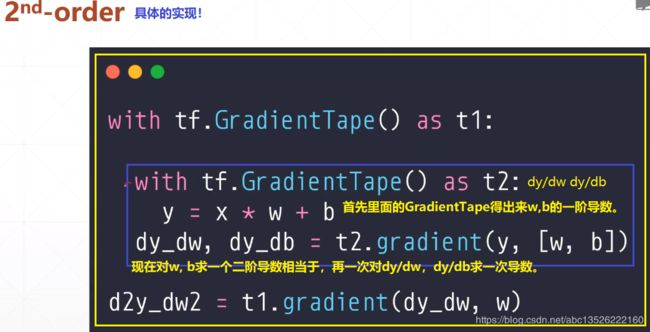
- 代码如下:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
w = tf.Variable(1.) #只能是小数
b = tf.Variable(2.)
x = tf.Variable(3.)
with tf.GradientTape() as tape1:
with tf.GradientTape() as tape2:
y = x*w +b
#dy_dw, dy_db = tape2.gradient(y, [w, b]) #都可以
[dy_dw, dy_db] = tape2.gradient(y, [w, b])
#d2y_d2w = tape1.gradient(dy_dw, [w]) #都可以
d2y_d2w = tape1.gradient(dy_dw, w)
print(dy_dw)
print(dy_db)
print(d2y_d2w)
- 运行结果:
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2.0/bin/python -u /home/zhangkf/tmp/pycharm_project_258/demo/TF2/out.py
tf.Tensor(3.0, shape=(), dtype=float32)
tf.Tensor(1.0, shape=(), dtype=float32)
[None]
Process finished with exit code 0
二、函数优化实战
2.1、绘制函数图像
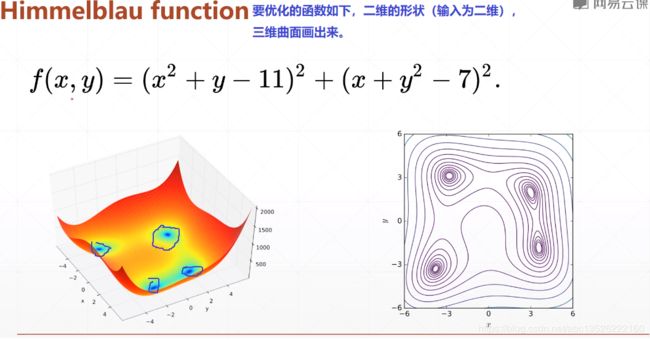


- 代码如下:
import tensorflow as tf
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def himelblau(x):
return (x[0]**2 + x[1] -11)**2 +(x[0] + x[1]**2 - 7)**2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print("x,y range: ", x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print("X,Y maps: ", X.shape, Y.shape)
Z = himelblau([X, Y])
fig = plt.figure('himelblau')
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
- 运行结果如下:
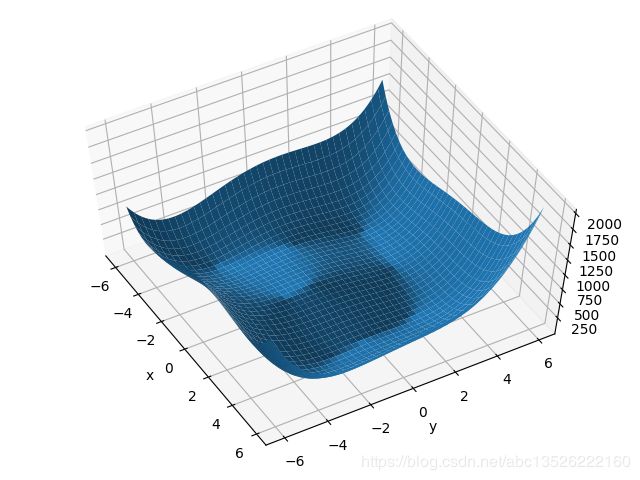
想深入理解绘图请参考文档:python笔记:numpy中mgrid的用法
2.2、使用梯度下降(重要!)

注意下面两点:
- 对于一个Tensor和Variable类型相信大家都知道了,如果你的网络结构使用的是Dense Layers构建的,里面的变量w, b类型就是Variable类型的变量, 也就是不需要watch;如果我们构建的x是一个constant也就是一个Tenosr类型的话,为了更好的跟踪梯度的相关信息,这里需要把它加进tape.watch里面去,这个例子就是。
- tf.GradientTape里面默认只会跟踪tf.Variable()类型。如果类型不是这个的话。这里为tf.tensor,tf.Variable是tf.tensor的一种特殊类型。因此简单的包装一下,在tensor类型外面包一个Variable类型。
- 代码如下:
import tensorflow as tf
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def himelblau(x):
return (x[0]**2 + x[1] -11)**2 +(x[0] + x[1]**2 - 7)**2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print("x,y range: ", x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print("X,Y maps: ", X.shape, Y.shape)
Z = himelblau([X, Y])
fig = plt.figure('himelblau')
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# [1., 0.], [-4, 0.], [4, 0.]
x = tf.constant([-4., 0.]) #初始点的坐标(x, y)
for step in range(200): #迭代200次。
with tf.GradientTape() as tape:
tape.watch([x])
y = himelblau(x)
grads = tape.gradient(y, [x])[0]
#print(grads)
x -=0.01*grads
if step % 20 ==0:
print('step {0}: x = {1}, f(x) = {2}'.format(step, x.numpy(),y.numpy()))
- 运行结果如下:
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2.0/bin/python -u /home/zhangkf/tmp/pycharm_project_258/demo/TF2/youhua.py
x,y range: (120,) (120,)
X,Y maps: (120, 120) (120, 120)
step 0: x = [-2.98 -0.09999999], f(x) = 146.0
step 20: x = [-3.6890159 -3.1276689], f(x) = 6.054703235626221
step 40: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 60: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 80: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 100: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 120: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 140: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 160: x = [-3.7793102 -3.283186 ], f(x) = 0.0
step 180: x = [-3.7793102 -3.283186 ], f(x) = 0.0
Process finished with exit code 0
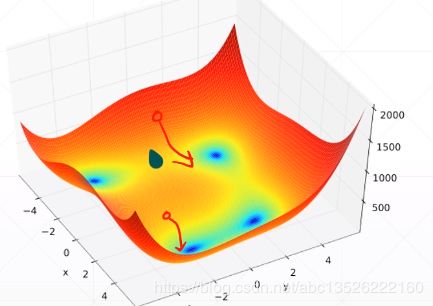
- 可以很快发现找到最小值,使f(x)=0;对比刚才的标准解,改变初始坐标,会有惊奇的发现。
- 我们改变初始坐标:通过梯度下降法搜索的时候,会按照不同的路径搜索(下图的2个坐标),同时也可以知道,梯度下降的任何一个超参数都会影响我们的最终的结果,所以我们在做deep learning的时候,需要非常的细心,要想取得很好的解,每一个细节我们都需要注意。
三、手写数字问题实战
3.1、fashionmnist数据集训练过程
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def preprocess(x, y): #数据预处理
x = tf.cast(x, dtype=tf.float32)/ 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x, y),(x_test, y_test) = datasets.fashion_mnist.load_data()
print(x.shape, y.shape)
batchsize = 128
#训练集预处理
db = tf.data.Dataset.from_tensor_slices((x,y)) #构造数据集,这里可以自动的转换为tensor类型了
db = db.map(preprocess).shuffle(10000).batch(batchsize)
#测试集预处理
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) #构造数据集
db_test = db_test.map(preprocess).shuffle(10000).batch(batchsize)
db_iter = iter(db)
sample = next(db_iter)
print("batch: ", sample[0].shape, sample[1].shape)
#准备一个网络,5层。
model = Sequential([
layers.Dense(256, activation=tf.nn.relu), # [b, 784] => [b, 256]
layers.Dense(128, activation=tf.nn.relu), # [b, 256] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32]
layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10
])
# 拿到这个层,喂给它一个权值,构建这样的一个输入。
model.build(input_shape=[None, 28*28])
model.summary() #调试的功能,可以打印网络结构。可以看出来总共有24万个,24万跟线,4字节的float.参数量一共100kb左右。gradient可能更大。
# 优化器
# w = w - lr*grads
optimizer = optimizers.Adam(lr=1e-3)
def main():
for epoch in range(30):
for step, (x, y) in enumerate(db):
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape:
# 前向传播,这里非常的简单。
# [b, 784] => [b, 10]
logits = model(x) #调用完成前向传播。
y_onehot = tf.one_hot(y, depth=10) #one-hot 标签编码
# 返回shape为[b],每个instance求一个实例。
loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot, logits))
# loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
# loss_ce = tf.reduce_mean(loss_ce)
grads = tape.gradient(loss_mse, model.trainable_variables)
#根据w=w-lr*grads把所有参数进行原地更新。zip的作用就是:把2个list(grads和mode...)中都为第0个的元素拼在一起,第1个同样2,3。
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch,step,'loss: ', float(loss_mse))
if __name__ == '__main__':
main()
- 运行结果部分如下:
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2gpu/bin/python -u /home/zhangkf/tmp/Demo/TF2/fashionmnist.py
(60000, 28, 28) (60000,)
batch: (128, 28, 28) (128,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 200960
_________________________________________________________________
dense_1 (Dense) multiple 32896
_________________________________________________________________
dense_2 (Dense) multiple 8256
_________________________________________________________________
dense_3 (Dense) multiple 2080
_________________________________________________________________
dense_4 (Dense) multiple 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
0 0 loss: 0.28108981251716614
0 100 loss: 0.03783908858895302
0 200 loss: 0.033792220056056976
0 300 loss: 0.02424546703696251
0 400 loss: 0.02667560800909996
1 0 loss: 0.020572274923324585
1 100 loss: 0.022968323901295662
1 200 loss: 0.02329324558377266
1 300 loss: 0.016586219891905785
1 400 loss: 0.02277246117591858
2 0 loss: 0.012702874839305878
2 100 loss: 0.021132349967956543
3.2、加上测试过程
- 我们在每一次epoch(数据集迭代一次)迭代循环的过程中加上一个测试过程,使用测试集测试准确率。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def preprocess(x, y): #数据预处理
x = tf.cast(x, dtype=tf.float32)/ 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x, y),(x_test, y_test) = datasets.fashion_mnist.load_data()
print(x.shape, y.shape)
batchsize = 128
#训练集预处理
db = tf.data.Dataset.from_tensor_slices((x,y)) #构造数据集,这里可以自动的转换为tensor类型了
db = db.map(preprocess).shuffle(10000).batch(batchsize)
#测试集预处理
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) #构造数据集
db_test = db_test.map(preprocess).shuffle(10000).batch(batchsize)
db_iter = iter(db)
sample = next(db_iter)
print("batch: ", sample[0].shape, sample[1].shape)
#准备一个网络,5层。
model = Sequential([
layers.Dense(256, activation=tf.nn.relu), # [b, 784] => [b, 256]
layers.Dense(128, activation=tf.nn.relu), # [b, 256] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32]
layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10
])
# 拿到这个层,喂给它一个权值,构建这样的一个输入。
model.build(input_shape=[None, 28*28])
model.summary() #调试的功能,可以打印网络结构。可以看出来总共有24万个,24万跟线,4字节的float.参数量一共100kb左右。gradient可能更大。
# 优化器
# w = w - lr*grads
optimizer = optimizers.Adam(lr=1e-3)
def main():
for epoch in range(30):
for step, (x, y) in enumerate(db):
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape:
# 前向传播,这里非常的简单。
# [b, 784] => [b, 10]
logits = model(x) #调用完成前向传播。
y_onehot = tf.one_hot(y, depth=10) #one-hot 标签编码
# 返回shape为[b],每个instance求一个实例。
loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot, logits))
# loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
# loss_ce = tf.reduce_mean(loss_ce)
grads = tape.gradient(loss_mse, model.trainable_variables)
#根据w=w-lr*grads把所有参数进行原地更新。zip的作用就是:把2个list(grads和mode...)中都为第0个的元素拼在一起,第1个同样2,3。
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch,step,'loss: ', float(loss_mse))
#test: 只需要做前向传播。
total_correct = 0 #总的正确的个数。
total_num = 0 #总的测试的个数。
for (x, y) in db_test:
# x: [b, 28, 28] => [b, 784]
# y: [b]
x = tf.reshape(x, [-1, 28*28])
#同样的道理这里我们不需要做一个GradientTape()的包围。
logits = model(x) # 调用完成前向传播。
# 首先把logits => problity
prob = tf.nn.softmax(logits, axis=1)
# [b, 10] => [b]
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# pred: [b]
# y: [b]
#correct: [b], True: equal, False: not equal
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
# 这里为什么需要做一个int,因为correct其实为一个tensor,但是我们这里的total_correct为一个numpy。
# 需要把correct转换为一个numpy。
total_correct += int(correct)
total_num +=x.shape[0]
acc = total_correct / total_num
print(epoch, 'test acc: ', acc)
if __name__ == '__main__':
main()
- 测试运行结果如下。
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2gpu/bin/python -u /home/zhangkf/tmp/Demo/TF2/fashionmnist.py
(60000, 28, 28) (60000,)
batch: (128, 28, 28) (128,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 200960
_________________________________________________________________
dense_1 (Dense) multiple 32896
_________________________________________________________________
dense_2 (Dense) multiple 8256
_________________________________________________________________
dense_3 (Dense) multiple 2080
_________________________________________________________________
dense_4 (Dense) multiple 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
0 0 loss: 0.19458024203777313
0 100 loss: 0.036363571882247925
0 200 loss: 0.032441332936286926
0 300 loss: 0.019747404381632805
0 400 loss: 0.02550702542066574
0 test acc: 0.8509
1 0 loss: 0.02539714053273201
1 100 loss: 0.02056763879954815
1 200 loss: 0.023237016052007675
1 300 loss: 0.015667583793401718
1 400 loss: 0.021112270653247833
1 test acc: 0.8623
2 0 loss: 0.020541422069072723
2 100 loss: 0.016747312620282173
2 200 loss: 0.02134033851325512
2 300 loss: 0.015358170494437218
2 400 loss: 0.018122201785445213
2 test acc: 0.8684
3 0 loss: 0.020190317183732986
3 100 loss: 0.016574887558817863
3 200 loss: 0.020748499780893326
3 300 loss: 0.013868845999240875
3 400 loss: 0.01566133461892605
3 test acc: 0.8672
4 0 loss: 0.018454818055033684
4 100 loss: 0.016828391700983047
4 200 loss: 0.020106405019760132
4 300 loss: 0.012405113317072392
4 400 loss: 0.014889994636178017
4 test acc: 0.8748
5 0 loss: 0.01606764644384384
5 100 loss: 0.017117412760853767
5 200 loss: 0.019564660266041756
5 300 loss: 0.011097634211182594
5 400 loss: 0.01564815826714039
5 test acc: 0.8785
6 0 loss: 0.014718996360898018
6 100 loss: 0.01662229560315609
6 200 loss: 0.018378911539912224
6 300 loss: 0.010508645325899124
6 400 loss: 0.015032753348350525
6 test acc: 0.8729
7 0 loss: 0.015667423605918884
7 100 loss: 0.016279781237244606
7 200 loss: 0.017196565866470337
7 300 loss: 0.00941111333668232
7 400 loss: 0.014600815251469612
7 test acc: 0.8759
8 0 loss: 0.01538974791765213
8 100 loss: 0.0186711847782135
8 200 loss: 0.0175008587539196
8 300 loss: 0.010067133232951164
8 400 loss: 0.012716127559542656
8 test acc: 0.8752
9 0 loss: 0.015107875689864159
9 100 loss: 0.014609502628445625
9 200 loss: 0.015676777809858322
9 300 loss: 0.00886197667568922
9 400 loss: 0.012621772475540638
9 test acc: 0.878
10 0 loss: 0.012508086860179901
10 100 loss: 0.014593368396162987
10 200 loss: 0.016985658556222916
10 300 loss: 0.008926136419177055
10 400 loss: 0.011033560149371624
10 test acc: 0.8831
11 0 loss: 0.013397718779742718
11 100 loss: 0.014744454063475132
11 200 loss: 0.01430567353963852
11 300 loss: 0.007968902587890625
11 400 loss: 0.01065629068762064
11 test acc: 0.8781
12 0 loss: 0.013224001042544842
12 100 loss: 0.015853524208068848
12 200 loss: 0.015165337361395359
12 300 loss: 0.009187716990709305
12 400 loss: 0.009905575774610043
12 test acc: 0.8831
13 0 loss: 0.013034269213676453
13 100 loss: 0.0140057522803545
13 200 loss: 0.015336663462221622
13 300 loss: 0.007507847622036934
13 400 loss: 0.010190257802605629
13 test acc: 0.8827
14 0 loss: 0.014330487698316574
14 100 loss: 0.014545144513249397
14 200 loss: 0.0151679003611207
14 300 loss: 0.007624481339007616
14 400 loss: 0.012049675919115543
14 test acc: 0.8795
15 0 loss: 0.011853596195578575
15 100 loss: 0.013386417180299759
15 200 loss: 0.01623581349849701
15 300 loss: 0.007744798436760902
15 400 loss: 0.010626107454299927
15 test acc: 0.8846
16 0 loss: 0.012869065627455711
16 100 loss: 0.01566094160079956
16 200 loss: 0.013635646551847458
16 300 loss: 0.007910249754786491
16 400 loss: 0.006288451608270407
16 test acc: 0.8783
17 0 loss: 0.01169196330010891
17 100 loss: 0.013201200403273106
17 200 loss: 0.014017730951309204
17 300 loss: 0.007273884490132332
17 400 loss: 0.007333120331168175
17 test acc: 0.88
18 0 loss: 0.011241523548960686
18 100 loss: 0.013573165982961655
18 200 loss: 0.015488039702177048
18 300 loss: 0.007177937775850296
18 400 loss: 0.007097573019564152
18 test acc: 0.8763
19 0 loss: 0.012915467843413353
19 100 loss: 0.014760339632630348
19 200 loss: 0.01378253661096096
19 300 loss: 0.005552347749471664
19 400 loss: 0.005689560901373625
19 test acc: 0.8874
20 0 loss: 0.010689078830182552
20 100 loss: 0.013369133695960045
20 200 loss: 0.01298336498439312
20 300 loss: 0.006962855812162161
20 400 loss: 0.006755348294973373
20 test acc: 0.8813
21 0 loss: 0.009134437888860703
21 100 loss: 0.010499630123376846
21 200 loss: 0.014751171693205833
21 300 loss: 0.006795352790504694
21 400 loss: 0.00538606196641922
21 test acc: 0.8801
22 0 loss: 0.01044565811753273
22 100 loss: 0.011590628884732723
22 200 loss: 0.015012377873063087
22 300 loss: 0.006033927667886019
22 400 loss: 0.00678940350189805
22 test acc: 0.8787
23 0 loss: 0.010316393338143826
23 100 loss: 0.012017862871289253
23 200 loss: 0.012830575928092003
23 300 loss: 0.006192473694682121
23 400 loss: 0.008464876562356949
23 test acc: 0.8764
24 0 loss: 0.011143441312015057
24 100 loss: 0.013284456916153431
24 200 loss: 0.01539537776261568
24 300 loss: 0.006349161267280579
24 400 loss: 0.005191871430724859
24 test acc: 0.8791
25 0 loss: 0.008160690777003765
25 100 loss: 0.01073048822581768
25 200 loss: 0.013163005001842976
25 300 loss: 0.00611414248123765
25 400 loss: 0.005381602793931961
25 test acc: 0.8757
26 0 loss: 0.010423164814710617
26 100 loss: 0.010404998436570168
26 200 loss: 0.012802797369658947
26 300 loss: 0.005761695560067892
26 400 loss: 0.0051652537658810616
26 test acc: 0.8748
27 0 loss: 0.011208397336304188
27 100 loss: 0.008895112201571465
27 200 loss: 0.012888671830296516
27 300 loss: 0.005374333821237087
27 400 loss: 0.002466527745127678
27 test acc: 0.875
28 0 loss: 0.008191661909222603
28 100 loss: 0.01037006825208664
28 200 loss: 0.011590645648539066
28 300 loss: 0.006284721195697784
28 400 loss: 0.004848773591220379
28 test acc: 0.871
29 0 loss: 0.01246708258986473
29 100 loss: 0.010097669437527657
29 200 loss: 0.010514488443732262
29 300 loss: 0.005914418958127499
29 400 loss: 0.0046995715238153934
29 test acc: 0.8688
Process finished with exit code 0
注意: 这里使用的fashion mnist数据集进行的测试,难度比mnist数据集提升了不少。
- float(loss)其中loss为一个tensor类型的,float()把tensor类型的转化为numpy格式的,也就是具体的一个数值。
3.1、mnist数据集测试结果
- 测试结果如下:
ssh://[email protected]:22/home/zhangkf/anaconda3/envs/tf2gpu/bin/python -u /home/zhangkf/tmp/Demo/TF2/fashionmnist.py
(60000, 28, 28) (60000,)
batch: (128, 28, 28) (128,)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 200960
_________________________________________________________________
dense_1 (Dense) multiple 32896
_________________________________________________________________
dense_2 (Dense) multiple 8256
_________________________________________________________________
dense_3 (Dense) multiple 2080
_________________________________________________________________
dense_4 (Dense) multiple 330
=================================================================
Total params: 244,522
Trainable params: 244,522
Non-trainable params: 0
_________________________________________________________________
0 0 loss: 0.11261574923992157
0 100 loss: 0.019530486315488815
0 200 loss: 0.01174904778599739
0 300 loss: 0.011174042709171772
0 400 loss: 0.0071163419634103775
0 test acc: 0.9683
1 0 loss: 0.008186059072613716
1 100 loss: 0.004481384996324778
1 200 loss: 0.0036306995898485184
1 300 loss: 0.007517718710005283
1 400 loss: 0.005410732235759497
1 test acc: 0.975
2 0 loss: 0.006112025119364262
2 100 loss: 0.002369648776948452
2 200 loss: 0.002144075697287917
2 300 loss: 0.004650611896067858
2 400 loss: 0.004395436029881239
2 test acc: 0.9772
3 0 loss: 0.004759968724101782
3 100 loss: 0.0015721507370471954
3 200 loss: 0.0015010953648015857
3 300 loss: 0.0029471651650965214
3 400 loss: 0.004548327997326851
3 test acc: 0.9776
4 0 loss: 0.0025919275358319283
4 100 loss: 0.0010535863693803549
4 200 loss: 0.0007837673183530569
4 300 loss: 0.0018600159091874957
4 400 loss: 0.0028297696262598038
4 test acc: 0.9775
5 0 loss: 0.0018190648406744003
5 100 loss: 0.0009360802359879017
5 200 loss: 0.00040155433816835284
5 300 loss: 0.0016272295033559203
5 400 loss: 0.0032459311187267303
5 test acc: 0.9776
6 0 loss: 0.0010409639216959476
6 100 loss: 0.0005466567818075418
6 200 loss: 0.0015541617758572102
6 300 loss: 0.0020434632897377014
6 400 loss: 0.0027982722967863083
6 test acc: 0.9789
7 0 loss: 0.0006204959936439991
7 100 loss: 0.0004487053374759853
7 200 loss: 0.000804127543233335
7 300 loss: 0.0021731392480432987
7 400 loss: 0.0018355580978095531
7 test acc: 0.9772
8 0 loss: 0.0006399792619049549
8 100 loss: 0.0017930917674675584
8 200 loss: 0.00017883079999592155
8 300 loss: 0.0012828889302909374
8 400 loss: 0.0035301153548061848
8 test acc: 0.9751
9 0 loss: 0.001718969433568418
9 100 loss: 0.0004413828137330711
9 200 loss: 0.00031321722781285644
9 300 loss: 0.0007271956419572234
9 400 loss: 0.0023524416610598564
9 test acc: 0.9775
10 0 loss: 0.0020461445674300194
10 100 loss: 0.00026773090939968824
10 200 loss: 0.0006563116912730038
10 300 loss: 0.000715789501555264
10 400 loss: 0.0021528888028115034
10 test acc: 0.9806
11 0 loss: 0.00024114687403198332
11 100 loss: 0.0005013482295908034
11 200 loss: 9.308371227234602e-05
11 300 loss: 0.001994780031964183
11 400 loss: 0.0016717053949832916
11 test acc: 0.9823
12 0 loss: 0.0001852611603680998
12 100 loss: 0.00024311350716743618
12 200 loss: 8.886255091056228e-05
12 300 loss: 0.0007402133196592331
12 400 loss: 0.0029067224822938442
12 test acc: 0.9779
13 0 loss: 0.00047873941366560757
13 100 loss: 9.357767703477293e-05
13 200 loss: 9.42078695516102e-05
13 300 loss: 0.0003543517959769815
13 400 loss: 0.0019165880512446165
13 test acc: 0.9813
14 0 loss: 0.00030578149016946554
14 100 loss: 7.959248614497483e-05
14 200 loss: 8.379908831557259e-05
14 300 loss: 0.0012580101611092687
14 400 loss: 0.0015522179892286658
14 test acc: 0.9804
15 0 loss: 0.0002282425994053483
15 100 loss: 0.00011417316272854805
15 200 loss: 5.990979843772948e-05
15 300 loss: 0.0005740143242292106
15 400 loss: 0.0015932765090838075
15 test acc: 0.9803
16 0 loss: 0.00010142216342501342
16 100 loss: 0.0002163861208828166
16 200 loss: 5.2243780373828486e-05
16 300 loss: 0.0003183520748279989
16 400 loss: 0.0019341596635058522
16 test acc: 0.9805
17 0 loss: 0.00020278460578992963
17 100 loss: 0.00015661961515434086
17 200 loss: 7.370500679826364e-05
17 300 loss: 0.0001956780324690044
17 400 loss: 0.0023549366742372513
17 test acc: 0.9814
18 0 loss: 0.0003451842349022627
18 100 loss: 7.637660019099712e-05
18 200 loss: 8.976418030215427e-05
18 300 loss: 0.00022842231555841863
18 400 loss: 0.002065550070255995
18 test acc: 0.9795
19 0 loss: 0.00022768843336962163
19 100 loss: 0.0002521189453545958
19 200 loss: 5.326288373908028e-05
19 300 loss: 0.00022491179697681218
19 400 loss: 0.0015890001086518168
19 test acc: 0.9801
20 0 loss: 9.52912523644045e-05
20 100 loss: 9.696342749521136e-05
20 200 loss: 3.90992354368791e-05
20 300 loss: 0.00018493531388230622
20 400 loss: 0.0015233487356454134
20 test acc: 0.9812
21 0 loss: 5.6464006775058806e-05
21 100 loss: 5.403083559940569e-05
21 200 loss: 0.000279740197584033
21 300 loss: 0.001402488211169839
21 400 loss: 0.0015064539620652795
21 test acc: 0.981
22 0 loss: 0.000320777966408059
22 100 loss: 3.527809167280793e-05
22 200 loss: 0.00013281249266583472
22 300 loss: 0.0017866295529529452
22 400 loss: 0.0020384842064231634
22 test acc: 0.9815
23 0 loss: 0.00012230486026965082
23 100 loss: 9.675664477981627e-05
23 200 loss: 3.2961681426968426e-05
23 300 loss: 0.0007549835136160254
23 400 loss: 0.00249645602889359
23 test acc: 0.9816
24 0 loss: 0.0001323460746789351
24 100 loss: 3.6385936255101115e-05
24 200 loss: 3.338681563036516e-05
24 300 loss: 0.0010897789616137743
24 400 loss: 0.0014632373349741101
24 test acc: 0.9812
25 0 loss: 8.117502875393257e-05
25 100 loss: 0.00014247625949792564
25 200 loss: 2.500126720406115e-05
25 300 loss: 0.00018271690350957215
25 400 loss: 0.0015632903669029474
25 test acc: 0.9835
26 0 loss: 6.632209260715172e-05
26 100 loss: 3.962207119911909e-05
26 200 loss: 1.637535751797259e-05
26 300 loss: 0.00011928033200092614
26 400 loss: 0.002037406899034977
26 test acc: 0.9804
27 0 loss: 7.14105844963342e-05
27 100 loss: 0.00018323754193261266
27 200 loss: 0.0005219013546593487
27 300 loss: 0.0002097641845466569
27 400 loss: 0.002554401522502303
27 test acc: 0.9794
28 0 loss: 0.00011688200174830854
28 100 loss: 3.008816929650493e-05
28 200 loss: 1.887914550025016e-05
28 300 loss: 0.00013388325169216841
28 400 loss: 0.0020415899343788624
28 test acc: 0.98
29 0 loss: 8.409706788370386e-05
29 100 loss: 0.00015714146138634533
29 200 loss: 0.0001166250731330365
29 300 loss: 0.00023176214017439634
29 400 loss: 0.0025082104839384556
29 test acc: 0.98
Process finished with exit code 0
四、Tensorboard可视化
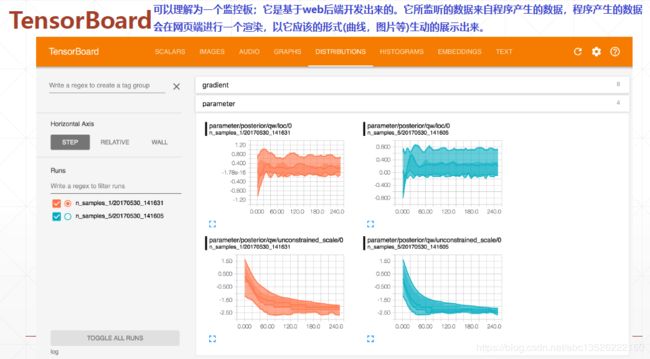
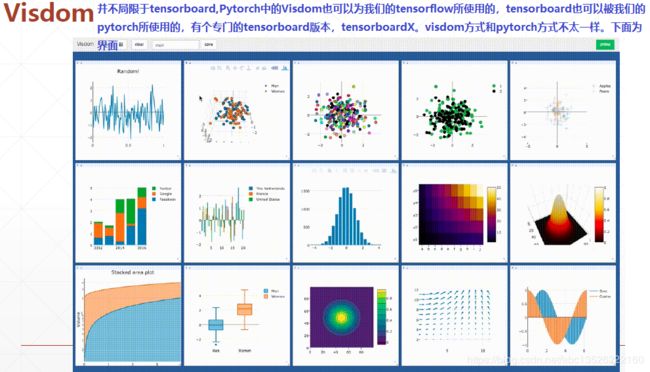
- 其中visdom显示界面可以看出更加的丰富,可以画各种各样的图像。
4.1、tensorboard的安装以及工作原理
- 貌似现在最先版本默认安转了tensorboard,如果没有安装的话执行下面的命令。
pip install tensorboard
- cpu运行一个程序,有一个tensor在这里流动;它会磁盘的某一个目录写数据;比如写在目录logs,写在这个目录下面以后,这个目录对应的文件格式就会被更新掉,这里面包含了一些要监听的数据(比如一些loss的最新数据写到这个文件夹下面去),然后另外一个监听器叫listener,你把目录告诉它,它会监听磁盘下的这个目录,然后这个目录有变化的话,它会把这个数据更新一下,这样的话打开一个web浏览器,这个web浏览器就是一个UI界面,这个界面会从listener中取数据。这样就可以在远程或者本地, 通过浏览器监听你的数据变化。

4.1、第一步:run listener

4.2、第二步:build summary

- 新建之后,summary往这个路径下写数据。
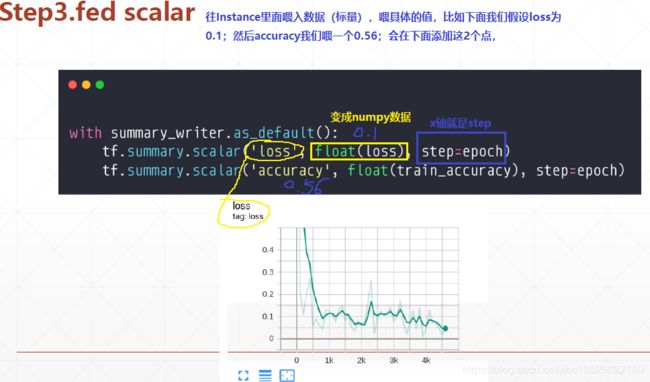
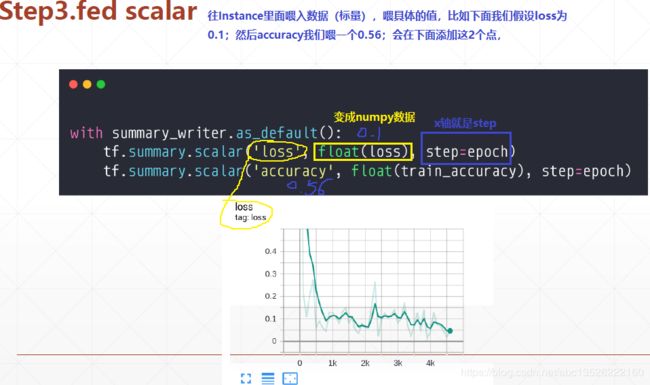
4.3、第三步:fed scalar
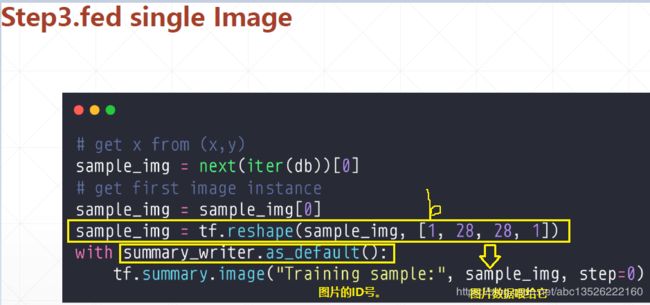
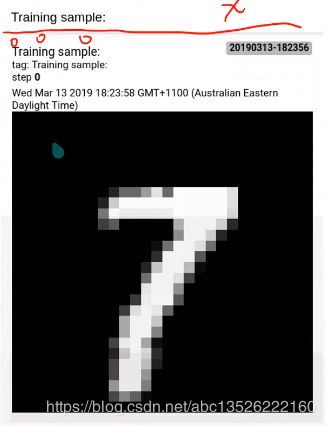
4.4、第三步2:fed single image
4.4、第三步3:fed muti-images
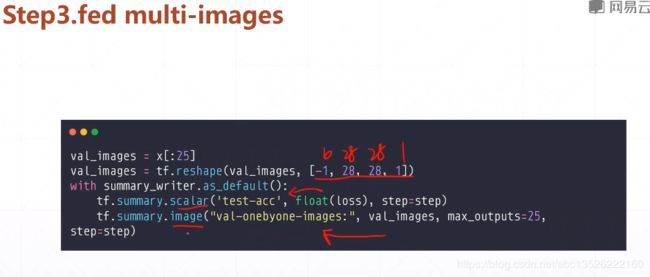 - 显示方式如下:不会组合成一个图片
- 显示方式如下:不会组合成一个图片

- 显示方式如下:不会组合成一个图片;怎么组合呢?tensorflow中没有,我们自己写了一个函数。image_grid()函数:


- 自己拼接之后显示效果如下: