Learning A Repression Network For Precise Vehicle Search
摘要
公共安全领域视频监控数量爆炸性的增长将大规模车辆数据库的检索技术推到风口浪尖。精准车辆检索需要根据输入的查询图片查找出所有目标。车辆检索的难度在于相同视觉特征的车型之间可能十分相似。为了解决这个问题,文章提出了RepNet,一种多任务的网络结构来同时学习每个目标的大体特征与精细特征。此外受益于特征分类的高准确率,提出了一种bucket search方式来减少检索时间,并基本保持准确率。实验在优化过的VehicleID数据集上进行。实验表明,RepNet达到了state-of-art表现,bucket search方法提升了约24倍检索时间。
1、Introduction
目前,公安系统对大规模监控图像和视频数据库的车辆图像检索和再识别的需求呈爆炸式增长。车牌自然是车辆的唯一ID,车牌识别已经在交通管理应用中得到了广泛的应用。不幸的是,在某些情况下,我们不能仅仅根据车牌来识别车辆。首先,有些监控摄像头并不是专门为车牌拍摄而设计的,即摄像头的分辨率不够高,无法清晰地显示车牌上的数字。其次,当车牌识别系统对“8”和“B”、“O”和“0”、“D”和“O”等容易混淆的字符进行分类时,车牌识别系统的性能急剧下降。最重要的是,车牌往往很容易被遮挡,删除,甚至伪造,这使得车牌与每辆车的相关性更小。因此,基于视觉属性的精确车辆检索,利用从车辆外观中获取的信息,在不同的监控摄像头视图中发现同一辆车辆,在现实应用中具有很大的实用价值。
虽然车辆检索和重识别问题已经讨论多年,大多数现有的工作依赖各种不同的传感器【2】和只能用于检索车辆共享同一coarse-level属性(例如颜色和模型)而不是完全的查询图像。与其他常见的检索问题如人脸和人检索相比,由于共享一个或多个视觉属性的车辆具有非常相似的视觉外观,因此车辆检索可能更具挑战性。换句话说,即使使用coarse属性的分类结果,我们仍然无法知道车辆的确切ID。然而,也有一些特殊的标志,如定制的图案,装饰,甚至划痕等,可以用来从其他类别中识别出车辆。因此,精确的车辆检索算法不仅要能够捕捉到每辆车的颜色、模型等粗粒度属性,而且要能够学习到代表每辆车独特细节的更具鉴别性的特征。
2、Related work
随着CNN的迅速发展,图像理解算法翻天覆地的变化。提出了许多算法通过学习关键部分的特征,提升不同类别特征的区别,提升分类准确率,或者使用度量学习降低类间变化问题的影响。然而,这样的模型不能很好的处理精确检索这一类的问题。例如,使用例如车型、年款、颜色这样属性训练的模型很难区分同一车型的区别。为了克服这类问题,一个潜在的方式是结合类似contrastive或者triplets等相似性约束。这类特征可以很好的表达细节特征却在属性特征上表现不好。值得注意的是triplet约束在人脸识别与检索上广泛应用多年,因为它可以保持类间的区分度。
因此直觉上来说可以通过结合分类特征与相似性约束来建立一个基于CNN的多任务框架。有些文献中结合softmax与contrastive loss联合优化,有些通过结合softmax与triplet loss得到更好的结果。这些模型之所以改善了传统CNN是因为相似性约束在训练过程中扩展了特征内容。此外,有些方法级联不同层的特征来提升特征的表达能力。然而,这些方法都有自己的局限性。首先,他们没有将不同任务的区别纳入考虑范围,因为所有浅层的卷积特征与fc层都是共享的。因此,不相关约束不能独立处理,更难的任务不能用更深的网络来处理,不同约束项关系是不可控的。其次,相似性约束与分类约束都是直接作用到最后一层全连接特征上,因此两种约束可能同时约束部分相同特征。分类约束设计用来学习同一类别相同的特征,相似性约束用来捕捉不同个体独特的特征。这样不仅会限制相似性约束的效果,还可能导致模型不收敛。
为了解决上述问题,论文提出了RepNet,在卷积层后使用两路全连接层来处理两个不同任务:属性分类与度量学习,用Repression层连接两路特征。较为浅层的特征用于属性学习。因此,相对较浅的属性分类流生成的特征可以作为反馈,监督后续的相似性学习,使其在不嵌入太多属性信息的情况下,更好地关注特殊细节。如图1第三至第五列所示,不同的任务确实关注于车辆的不同部分,从相似性约束(col 5)中学习到的特征与从分类约束(col 3和4)中学习到的特征几乎没有相关性。
此外,由于双路结构,文中引入了bucket search策略来在保证精度的前提下大幅度提升检索速度。我们还用一个新的属性丰富了“vehicleId”数据集【1】,并对其进行了扩展检索实验。

3、The Proposed Approach
3.1 Repression Network
其他深多任务学习模型的和Repression网络主要区别是我们分开后的全层(FC)层深卷积结构为两个流,一个基于标签的属性分类(分类属性流,ACS)。softmax损失函数和注重细节的相似性学习(学习流相似,SLS)三联体损失函数【11】。然后在两个流之间添加一个Repression 层。如图3所示,通过将SLS中第一层的特性与ACS中最后一层FC的特性交互,Repression层将SLS与ACS连接起来。
设计这个模型的基本思路是我们希望网络能够产生两个不同层次的分支特征-coarse特征与细节特征,这样每个分枝特征可以包含更多不同层级有区分度的信息用来进行更精确的检索任务。例如,如果需要检索的样本如图1左上第一张,我们可以首先第一步从数据库中找到所有灰色的大众速腾轿车作为候选,之后通过用户涂装、装饰、划痕或者其他特别特征来缩小范围。对于车辆来说,粗粒度特征与细节特征通常是独立的,例如停车证或者划痕既有可能出现在白色起亚轿车上,也可能出现在白色本田SUV上。这也是为什么我们可以为他们使用两个不同的分支。此外根据之前的实验结果,粗粒度特征学习比相似度学习要容易得多,例如之前的多任务学习框架比之前的收敛快得多,并且可以得到更高的准确率。因此,我们设计的网络在ACS中FC层相对更少,这样可以更早的得到最终的特征。最后,通过Repression层,前期提取的ACS特征用来给随后的SLS特征提供特定的反馈,这样减少甚至消除粗粒度信息对SLS的影响,使得SLS更专注于潜在细节特征。
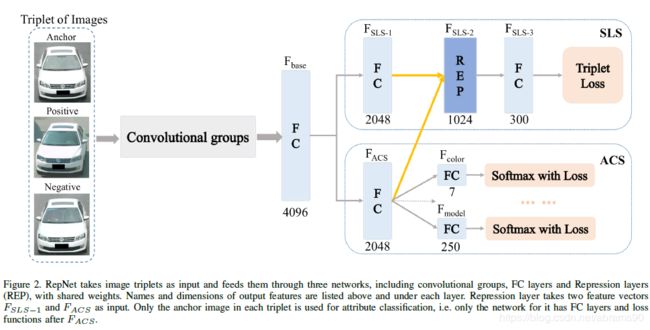
整体来说这是一个先进的多标签学习框架,更好的使用多任务框架为两个不同级别的任务产生两个不同的尽可能独立的子特征-粗粒度的车辆特征分类与超越属性标签的细节学习。此外,这种框架可以解决之前多任务框架中tripletloss难且慢收敛的问题。
3.2 Repression Layer
Repression层输入是两个向量![]() 与
与![]() ,两者维度相同,表示为
,两者维度相同,表示为![]() 。Repression层输出表示为
。Repression层输出表示为![]() 维度为
维度为![]() ,并且作为特征向量输入SLS第二层。我们设立了三个不同的Repression层,并在实验中做了对比。
,并且作为特征向量输入SLS第二层。我们设立了三个不同的Repression层,并在实验中做了对比。
Product Repression Layer(PRL)。PRL进行两个输入特征向量的元素间相乘,并且将新向量映射到![]() 特征空间:
特征空间:
![]()
这里![]() 是一个
是一个![]() 大小的矩阵。(1)中每个特征向量的导数分别为:
大小的矩阵。(1)中每个特征向量的导数分别为:
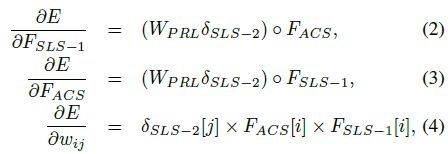
这里![]() 是
是![]() 计算出来的梯度,
计算出来的梯度,![]() 是
是![]() 在第i行第j列的值,E表示loss,在我们的实验中是tripletloss,用于相似度度量。
在第i行第j列的值,E表示loss,在我们的实验中是tripletloss,用于相似度度量。
Subtractive Repression Layer (SRL)。同样,SRL对两个输入特征向量进行元素相减,将新向量映射到Doutput维空间:
![]()
这里![]() 也是一个
也是一个![]() 大小的矩阵。类似的,(5)得导数计算如下:
大小的矩阵。类似的,(5)得导数计算如下:

Concatenated Repression Layer (CRL)。CRL将讲个输入特征向量连接成一个长向量,并将其映射到![]() 维度空间:
维度空间:
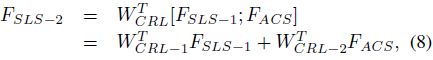
这里![]() 是一个
是一个![]() 矩阵,
矩阵,![]() 与
与![]() 是
是![]() 矩阵。(8)的导数求解如下:
矩阵。(8)的导数求解如下:

Repression设计用来使得ACS学到的特征不会被包含到SLS中,并且平衡两个分支权重的尺度。SRL是减少信息从一个特征到另一个特征的嵌入最直观的方法,可以作为RepNet的基线。PRL能够对两个特征向量的内积进行建模,提高了建模能力。如果两个向量互相正交,我们可以假设它们几乎没有相关性。与以往直接对两个特征关系进行建模的Repression层相比,CRL是一种线性变换,是两个特征的组合,是最神奇的一个,它能够对更复杂的情况进行建模,超出了明确定义的距离测量。
3.3 Training the Network
利用交叉熵损失对softmax归一化进行属性分类,利用triplet loss损失进行相似性学习。我们实验中所有基于VGG【16】的CNN模型,包括5个卷积组,都使用了广泛使用的深度学习框架Caffe【17】进行训练,并从只能用于属性分类的baseline模型进行微调。我们将梯度下降的小批量大小设置为90,这意味着每次训练迭代输入90*3 = 270张图像。我们从0.001的基本学习率开始,然后通过在每50000个批处理迭代之后重复乘以0.5来降低它。动量设置为0.9,所有损失的权重设置为相等。
在相似性学习方面,一个重要的问题是triplet抽样,因为它可以直接决定网络可以学习什么。在我们的基于Repression层的多任务学习框架中,只有最难的三元组,其中三幅图像具有完全相同的粗粒度属性(例如颜色和模型),才能用于相似性学习。这样做的原因是,相似性学习流的目的是学习属性之外的东西,即一些不能用标签描述的细节,所以SLS学习的特征应该与属性分类无关。否则,从SLS中学习到的特性可能会与从ACS中学习到的特性部分重叠,这将会降低模型的性能或表达。
4、Repression Analysis
4.1 Canonical Correlation Analysis(典型相关性分析)
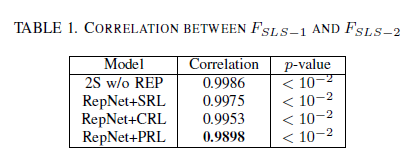
我们使用正则相关分析(CCA)【18】来说明Repression层可以抑制嵌入在以下特征中的某些信息,即降低FSLS-1与FSLS-2之间的相关性。具体来说,CCA将学习FSLS -1和FSLS -2特征的投影,通过投影特征之间的相关性最大化,我们用这种相关性来表示这两个特征之间的关系。
我们首先对协方差矩阵![]() 与
与![]() 和互协方差矩阵
和互协方差矩阵![]() 与
与![]() 进行分解,在训练集中
进行分解,在训练集中![]() 与
与![]() 分别表示为X与Y。那么,在不失通用性的前提下,我们从
分别表示为X与Y。那么,在不失通用性的前提下,我们从![]() 与
与![]() 挑选一个最大的特征向量来讲
挑选一个最大的特征向量来讲![]() 与
与![]() 映射到一维空间中。投影特征之间的Pearson相关系数如表1所示。注意,相关性非常接近于1,因为这两个特征只相隔一层,这些值是它们通过投影到一维空间所能得到的最大相关性。然而,我们仍然可以看到相关性下降了1% (RepNet + PRL),这意味着由于抑制层的存在,某些信息被抑制而无法进入FSLS -2。
映射到一维空间中。投影特征之间的Pearson相关系数如表1所示。注意,相关性非常接近于1,因为这两个特征只相隔一层,这些值是它们通过投影到一维空间所能得到的最大相关性。然而,我们仍然可以看到相关性下降了1% (RepNet + PRL),这意味着由于抑制层的存在,某些信息被抑制而无法进入FSLS -2。
4.2 Saliency Maps
然后,我们直观地展示了RepNet的有效性。我们使用【19】中介绍的方法从不同的层中提取特征的显著性图。具体来说,通过用一个小的黑色方块覆盖图像,我们可以计算出新图像和原始图像产生的特征之间的差异。差异越大,RepNet从覆盖区域获得的信息越多。通过在整个图像上滑动黑色方块,可以生成完整图像的显著性映射。
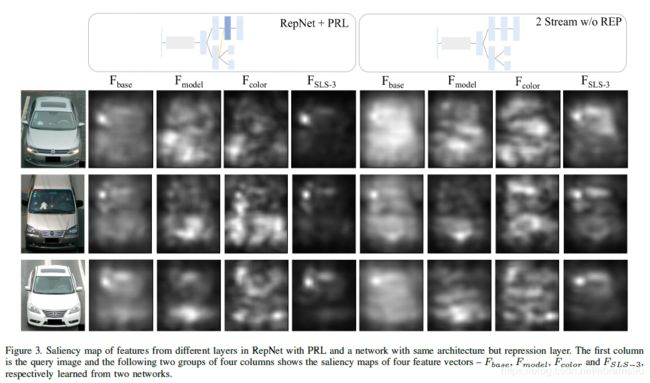
我们以图1中的轿车和面包车为例,说明不同的任务具有不同的显著性映射,即关注车辆的不同部位。Fbase的显著性映射在图像中几乎均匀地分布在车辆上,这意味着低层几乎从车辆的任何位置提取信息。然而,由于每个任务都有很强的约束(即损失函数),从每个任务的最后一层提取的特征的显著性映射只落在某个特定的区域。例如,为了正确的分类车型和车型的颜色,我们的模型主要集中在车型的前部,尤其是散热盖上的品牌和发动机罩上的颜色。
SLS中最后一个FC层的显著性图证明了模型和抑制层的特殊细节提取的有效性。原因之一是它集中在挡风玻璃左上角的一小块地方,所有的年检标都必须贴在上面。请注意,这些年检标是强制性的所有车辆都需要粘贴,但可以以不同的顺序和模式粘贴,因人而异。因此,它可以作为一个强而特殊的标记,将当前查询图像中的车辆与其他具有相同颜色和型号的车辆区分开来。的另一个原因是,如图3所示,相比之下,去年FC层在SLS的显著图的网络没有Repression层(9列)上校的一个RepNet(5列)上包括更少车辆其他位置的信息,特别是前面用于属性分类部分。这是一个强有力的证据,表明Repress层确实会压抑用于其他任务的信息,并使当前流专注于学习属性标签之外的细节。
5、Retrieval Experiments
在本节中,我们在“VehicleID”数据集【1】上对所提出的模型进行了深入的实验。特别地,我们的目标是证明我们所学习的特征表示可以用来检索相同实例的图像,与其他基于cnn的多任务学习方法相比,具有更高的精度或更短的检索时间。注意,我们在这里没有引入任何单任务模型(例如softmax分类或Triplet学习),因为【10】已经证明了多任务框架在区分特征学习方面优于这些模型的有效性。
四个多任务学习模型我们比较先进,有:1)一个模型的最后FC层链接一个softmax损失一个Triplet损失【10】,2)一个模型的相连的FC层分别链接一个softmax与一个Triplet损失【14】。3)两路模型结尾分别连接softmax与一个Tripletloss。4)两路模型使用softmax与coupled cluster loss,即混合不同网络【1】。所有的CNN模型底部都有完全相同的五个卷积组,并且在相同的训练数据上进行了微调。
5.1 DataSet
VehicleID数据集包含多个真实世界的监控摄像头在白天拍摄到的数据,这些摄像头分布在中国的一个小城市。其中包含26267辆车的221763张图像,以及用于模型训练的78982张图像,这些图像具有三个属性——颜色、车型和车辆ID。在实验中,颜色和车辆模型作为两个粗粒度属性,共有7种不同的颜色,共250种不同的型号。对于每个车辆ID,即每个车辆类,有多个图像属于该类。因此,VehicleID数据集适合于我们的模型训练和检索实验。此外,在我们的实验中,我们还包括389,316个干扰样本,它们是由另一个城市的监控摄像头收集到的车辆图像。
然而,vehicleID数据集的一个显著缺点是,车辆图像要么是从前面捕获的,要么是从后面捕获的,并且没有关于这些信息的标签。因此,我们在vehicleID数据集中为所有的图像提供了一个新的标签视图来描述图像的拍摄位置。然后,我们根据每个图像的视图更新其车辆ID,以便将相同原始类中具有不同视图的图像分成两个新类。现在,我们有43,426个不同的车辆id。
我们从vehicleID数据集中创建了两个查询图像列表,用于检索实验。请注意,所有这些查询图像没有出现在训练集,没有对他们共享相同的ID。第一个查询列表,随机查询列表,由随机选择1000图像而另一个,样本列表,包括内部类样本数量最多的1000张样本。
5.2 Evaluation Criteria
我们根据在对象检索中广泛使用的平均平均精度(MAP)协议,在新重新标记的车体数据集上评估了我们提出的模型,并报告了“k精度”曲线。“K处精度”表示检索到的前k个图像的平均精度,K处精度为![]() ,这里
,这里![]() 是标签函数,ri。与rq是样本列表上第i张样本,与查询样本的标签。MAP是一种更全面的测量,同时描述精度和召回率:MAP=
是标签函数,ri。与rq是样本列表上第i张样本,与查询样本的标签。MAP是一种更全面的测量,同时描述精度和召回率:MAP=![]() ,T是查询样本的GT数量,N是样本集中的样本总数。
,T是查询样本的GT数量,N是样本集中的样本总数。
5.3 Bucket Search
与线性搜索方法完全计算查询图像与数据库中所有图像之间的距离相比,bucket搜索只对候选相邻列表执行此操作。具体来说,我们首先为每个不同的属性组合创建几个桶,并将所有图像放入对应的桶中。注意,除了训练集中的属性外,数据库中的图像和查询图像的属性都是由模型预测的。然后,对于每一个查询图像,我们根据其预测的属性找出它所属的桶,只计算由SLS生成的特征距离,SLS是一个更短的向量,查询图像与位于同一桶内的图像之间的特征距离。但是对于一路模型,我们仍然在实验中使用原始特性进行桶搜索。
然而,在实践中,由于属性分类不能很好地工作,因此可能没有将图像分配到正确的桶中。我们决定为每个查询映像检查多个bucket。具体来说,对于vehicleID数据集,我们在四个桶中检查图像,这些桶表示给定查询图像的最近的两种颜色和两个模型。
5.4 Experiment Results
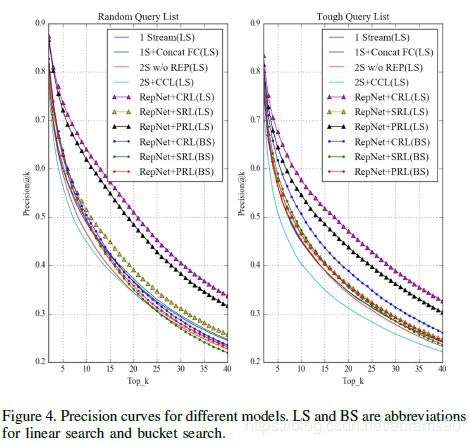
我们将我们的Repression网络与本节开头提到的其他多任务学习框架进行了比较。由于所有的模型都是基于VGG构造的,并且对分类和相似性学习都使用了约束条件,所以我们只使用有区别的缩写来命名它们。表2列出了所有检索任务的MAP。在桶搜索中,双流模型的性能优于单流模型,这表明将不同的约束分解为不同的流可以帮助它们各自获得更好的子特性。但是随着子特征之间的尺度变化,线性搜索的性能受到很大的影响,线性搜索需要将双流模型的所有子特征串联起来。然而,在线性搜索中,RepNets的检索性能明显优于其他所有列出的多任务学习框架,CRL在三个Repression层中脱颖而出,在线性搜索和桶搜索中都具有更高的精度。实验结果表明,RepNet是一种有效的学习判别特征的方法,精确的检索和Repression层有助于平衡子特征的尺度。另外,图4中最上面的两条曲线是带有PRL和CRL的RepNet,这也有力地证明了我们框架的有效性。

虽然根据表2,bucket搜索不能具有与线性搜索相同的检索性能,但是它可以大大减少检索时间。在我们的实验中,我们使用特征尺寸为2348(FSLS-3de 300,FACS的2048)线性搜索,和特征尺寸为300桶搜索。线性搜索和桶搜索的平均检索时间分别为0.213s和0.009s,是桶搜索速度的24倍。另外,如图4所示,RepNet桶的precision@k曲线搜索比其他模型的线性搜索曲线,这意味着RepNet桶搜索Top排名等于生成的其他模型的线性搜索。此外,在随机查询列表中使用CRL的RepNet bucket搜索的MAP甚至比其他模型的线性搜索还要高。
6、Conclusion
在本文中,我们提出了一个多任务学习框架来有效地为属性分类和相似度学习生成细粒度的特征表示。设计了一个Repression层,将从属性分类中学习到的信息嵌入到表示每个独特车辆的特定细节的特征中,并在两个FC层流中平衡权重的比例。通过在vehicleID数据集中增加一个新的属性,对修改后的数据集进行了大量的实验,证明了我们的框架和Repression层的有效性-线性搜索的图像检索精度更高,桶搜索的检索时间更短。这些优点值得对RepNet在学习细粒度特征表示(如引入哈希函数生成二进制特征或将卷积组分成两组)方面进行进一步研究。此外,我们还可以将我们的框架扩展到更广泛的应用,如人脸和行人检索。