图解什么是 Transformer
Transformer 是 Google 团队在 17 年 6 月提出的 NLP 经典之作,
由 Ashish Vaswani 等人在 2017 年发表的论文 Attention Is All You Need 中提出。
Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。

Transformer 是一种基于 encoder-decoder 结构的模型,
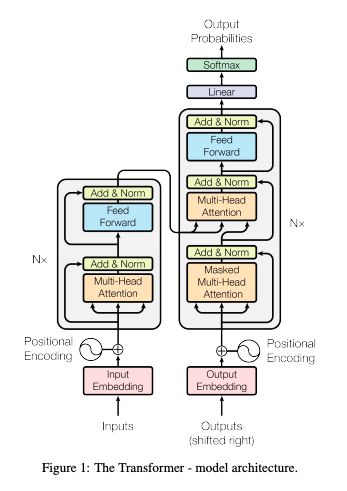
在 Encoder 中,
- Input 经过 embedding 后,要做 positional encodings,
- 然后是 Multi-head attention,
- 再经过 position-wise Feed Forward,
- 每个子层之间有残差连接。
在 Decoder 中,
- 如上图所示,也有 positional encodings,Multi-head attention 和 FFN,子层之间也要做残差连接,
- 但比 encoder 多了一个 Masked Multi-head attention,
- 最后要经过 Linear 和 softmax 输出概率。
下面我们具体看一下其中这几个概念,这里主要参考 Jay Alammar,他在 The Illustrated Transformer 中给出了很形象的讲解。
1. 整体结构
例如我们要进行机器翻译任务,输入一种语言,经过 Transformer,会输出另一种语言。
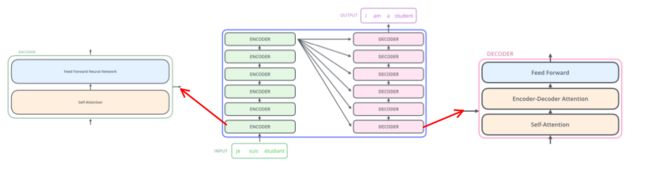
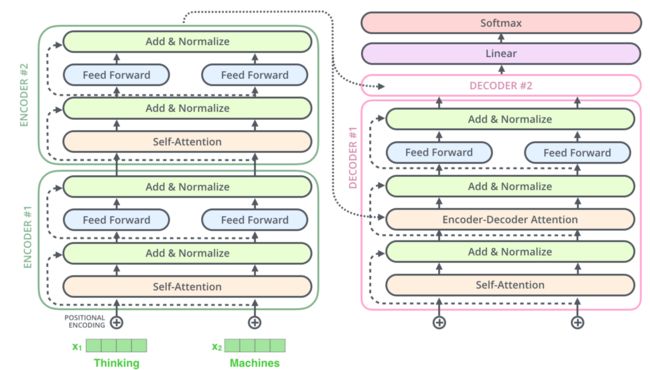
Transformer 的 encoder 由 6 个编码器叠加组成,
decoder 也由 6 个解码器组成,
在结构上都是相同的,但它们不共享权重。
每一个 encoder 都分为两个子层:
- 先流经 self-attention 层,这一层可以帮助编码器在编码某个特定单词时,也会查看其他单词
- self-attention 层的输出再传递给一个前馈神经网络层,在每个位置的前馈网络都是完全相同的,
每一个 decoder 也具有这两个层,但还有一个注意力层,用来帮助解码器关注输入句子的相关部分
2. Encoder
- Input 经过 embedding 后,要做 positional encodings,
- 然后是 Multi-head attention,
- 再经过 position-wise Feed Forward,
- 每个子层之间有残差连接。
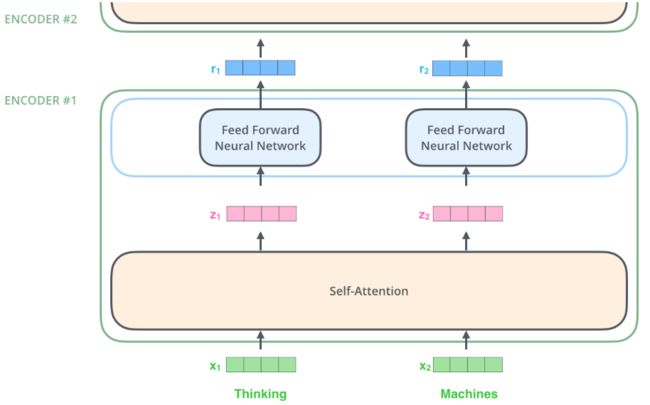
首先使用嵌入算法将输入的 word 转换为 vector,
最下面的 encoder ,它的输入就是 embedding 向量,
在每个 encoder 内部,
输入向量经过 self-attention,再经过 feed-forward 层,
每个 encoder 的输出向量是它正上方 encoder 的输入,
向量的大小是一个超参数,通常设置为训练集中最长句子的长度。
在这里,我们开始看到 Transformer 的一个关键性质,
即每个位置的单词在 encoder 中都有自己的路径,
self-attention 层中的这些路径之间存在依赖关系,
然而在 feed-forward 层不具有那些依赖关系,
这样各种路径在流过 feed-forward 层时可以并行执行。
2.1 positional encodings
Positional Encoding 是一种考虑输入序列中单词顺序的方法。
encoder 为每个输入 embedding 添加了一个向量,这些向量符合一种特定模式,可以确定每个单词的位置,或者序列中不同单词之间的距离。
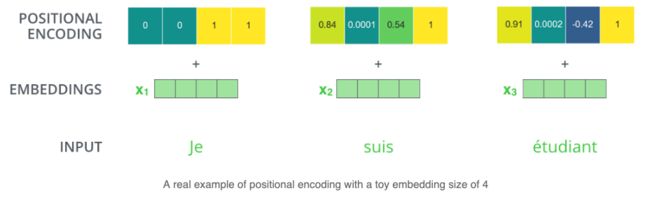
例如,input embedding 的维度为4,那么实际的positional encodings如下所示:
在下图中,是20个单词的 positional encoding,每行代表一个单词的位置编码,即第一行是加在输入序列中第一个词嵌入的,每行包含 512 个值, 每个值介于 -1 和 1 之间,用颜色表示出来。
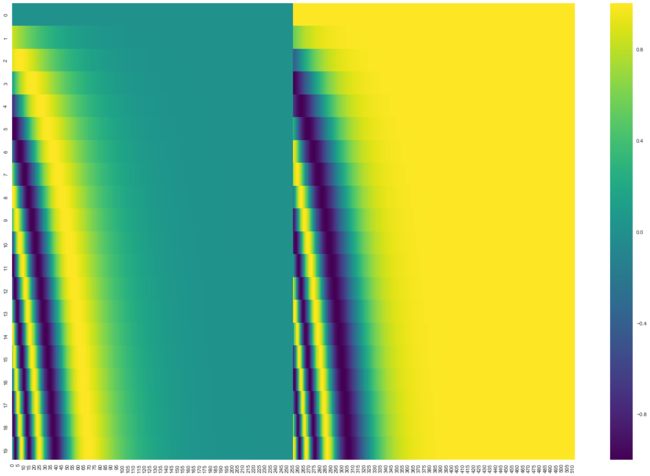
可以看到在中心位置分成了两半,因为左半部分的值由一个正弦函数生成,右半部分由余弦函数生成,然后将它们连接起来形成了每个位置的编码向量。
当然这并不是位置编码的唯一方法,只是这个方法能够扩展到看不见的序列长度处,例如当我们要翻译一个句子,这个句子的长度比我们训练集中的任何一个句子都长时。
2.2 Multi-head attention
2.2.1 先看什么是 Self-Attention
例如我们要翻译:”The animal didn’t cross the street because it was too tired” 这句话
这句话中的“it”是指什么?它指的是 street 还是 animal?
这对人类来说是一个简单的问题,但对算法来说并不简单。
而 Self-Attention 让算法知道这里的 it 指的是 animal
2.2.2 self-attention 的作用
当模型在处理每个单词时,self-attention 可以帮助模型查看 input 序列中的其他位置,寻找相关的线索,来达到更好的编码效果。它的作用就是将对其他相关单词的“understanding”融入我们当前正在处理的单词中。

例如上图中,在第5层时,我们就知道 it 大概指的是 animal 了。
2.2.3 self-attention 具体原理
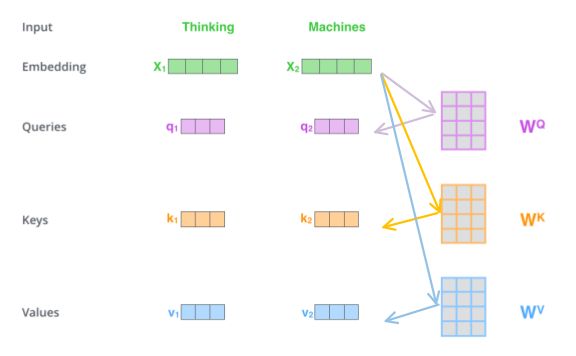
第一步,为编码器的每个输入单词创建三个向量,
即 Query vector, Key vector, Value vector
这些向量通过 embedding 和三个矩阵相乘得到,
请注意,这些新向量的尺寸小于嵌入向量。它们的维数为64,而嵌入和编码器输入/输出向量的维数为512.它们不一定要小,这是一种架构选择,可以使多头注意力计算(大多数)不变。
将x1乘以WQ得到Query向量 q1,同理得到Key 向量 和, Value 向量
这三个向量对 attention 的计算有很重要的作用
第二步,是计算一个得分
假设我们要计算一个例子中第一个单词 “Thinking” 的 self-attention,就需要根据这个单词,对输入句子的每个单词进行评分,这个分数决定了对其他单词放置多少关注度。
分数的计算方法是,
例如我们正在考虑 Thinking 这个词,就用它的 q1 去乘以每个位置的 ki
第三步和第四步,是将得分加以处理再传递给 softmax
将得分除以 8(因为论文中使用的 key 向量的维数是 64,8 是它的平方根)
这样可以有更稳定的梯度,
然后传递给 softmax,Softmax 就将分数标准化,这样加起来保证为 1。
这个 softmax 分数决定了每个单词在该位置bbei表达的程度。
很明显,这个位置上的单词将具有最高的softmax分数,但有时候注意与当前单词相关的另一个单词是有用的。
第五步,用这个得分乘以每个 value 向量
目的让我们想要关注单词的值保持不变,并通过乘以 0.001 这样小的数字,来淹没不相关的单词
第六步,加权求和这些 value 向量
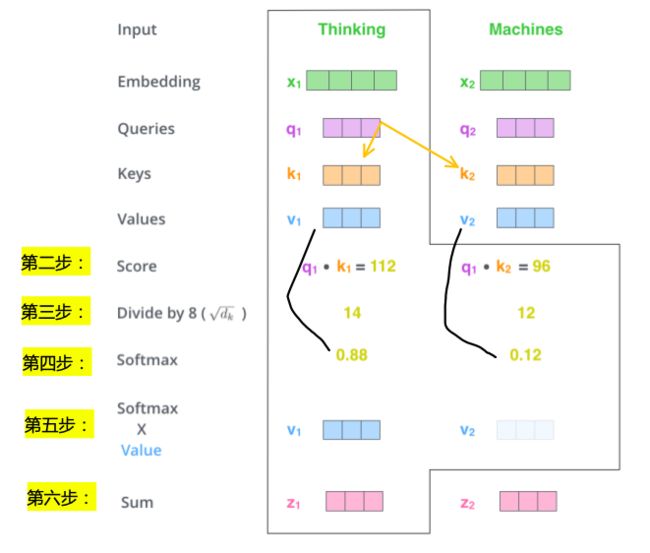
这就是第一个单词的 self-attention 的输出
得到的向量接下来要输入到前馈神经网络,在实际实现中用矩阵乘法的形式完成
2.2.4 multi-headed 机制
论文中还增加一种称为 multi-headed 注意力机制,可以提升注意力层的性能
它使得模型可以关注不同位置
虽然在上面的例子中,z1 包含了一点其他位置的编码,但当前位置的单词还是占主要作用, 当我们想知道“The animal didn’t cross the street because it was too tired” 中 it 的含义时,这时就需要关注到其他位置
这个机制为注意层提供了多个“表示子空间”。下面我们将具体介绍,
1. 经过 multi-headed , 我们会得到和 heads 数目一样多的 Query / Key / Value 权重矩阵组
论文中用了8个,那么每个encoder/decoder我们都会得到 8 个集合。
这些集合都是随机初始化的,经过训练之后,每个集合会将input embeddings 投影到不同的表示子空间中。
2. 简单来说,就是定义 8 组权重矩阵,每个单词会做 8 次上面的 self-attention 的计算
这样每个单词会得到 8 个不同的加权求和 z
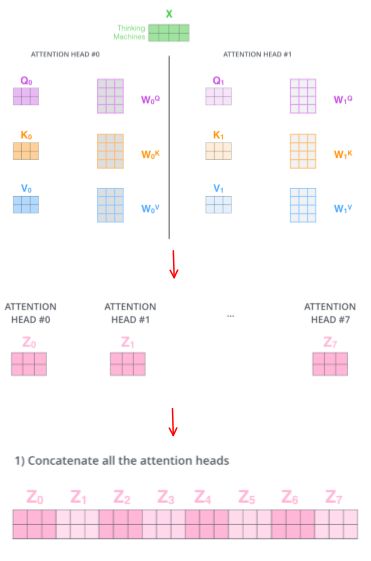
3. 但在 feed-forward 处只能接收一个矩阵,所以需要将这八个压缩成一个矩阵
方法就是先将8个z矩阵连接起来,然后乘一个额外的权重矩阵WO

下图显示了在例句中,it 的不同的注意力 heads 所关注的位置,一个注意力的焦点主要集中在“animal”上,而另一个注意力集中在“tired”,换句话说,it 是 “animal”和“tired”的一种表现形式。
当然如果选了8个层,将所有注意力 heads 都添加到图片中,就有点难以解释了。

2.3 Residuals
这里有一个细节,
即在每个 encoders 和 decoders 里面的 self-attention, ffnn,encoders-decoders attention 层,都有 residual 连接,还有一步 layer-normalization
3. Decoder
下面我们看一下 Decoder 部分
- 如上图所示,也有 positional encodings,Multi-head attention 和 FFN,子层之间也要做残差连接,
- 但比 encoder 多了一个 Masked Multi-head attention,
- 最后要经过 Linear 和 softmax 输出概率。
1. 输入序列经过编码器部分,然后将最上面的 encoder 的输出变换成一组 attention 向量 K和V
这些向量会用于每个 decoder 的 encoder-decoder attention 层,有助于解码器聚焦在输入序列中的合适位置
重复上面的过程,直到 decoder 完成了输出,每个时间步的输出都在下一个时间步时喂入给最底部的 decoder,同样,在这些 decoder 的输入中也加入了位置编码,来表示每个字的位置。
2. 解码器中的 self attention 层与编码器中的略有不同
在解码器中,在 self attention 的 softmax 步骤之前,将未来的位置设置为 -inf 来屏蔽这些位置,这样做是为了 self attention 层只能关注输出序列中靠前的一些位置。
Encoder-Decoder Attention 层的工作方式与 multiheaded self-attention 类似,只是它用下面的层创建其 Queries 矩阵,从编码器栈的输出中获取 Keys 和 Values 矩阵。
3. 解码器最后输出的是一个向量,如何把它变成一个单词,这就要靠它后面的线性层和 softmax 层
线性层就是一个很简单的全连接神经网络,将解码器输出的向量映射成一个更长的向量。
例如我们有 10,000 个无重复的单词,那么最后输出的向量就有一万维。
每个位置上的值代表了相应单词的分数。
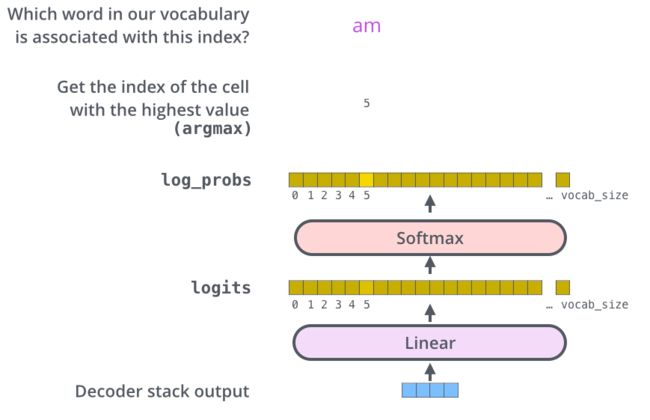
softmax 层将这个分数转换为了概率。
我们选择概率最大的所对应的单词,就是当前时间步的输出。
学习资源:
https://arxiv.org/pdf/1706.03762.pdf
https://jalammar.github.io/illustrated-transformer/
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html