深度学习(十二)——Winograd(2)
最大公约数和Euclidean algorithm(续)
Euclidean algorithm的步骤如下图所示:
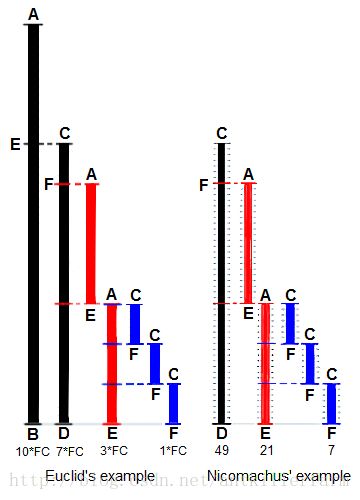
1.假设 a>b a > b ,则令 c:=amodb c := a mod b 。
2.如果 c=0 c = 0 ,则 GCD(a,b)=b G C D ( a , b ) = b 。
3.否则令 a:=b,b:=c a := b , b := c ,并返回到第1步。
这个算法应该是Euclid记述的前人成果,因为更早的Eudoxus of Cnidus曾提到过这个算法。
Eudoxus of Cnidus,公元前390年~公元前337年,古希腊几何学家、天文学家和地理学家。柏拉图同时代最杰出的数学家。《几何原本》卷Ⅴ和卷Ⅻ主要来自欧多克索斯的工作。
然而,小学课本不使用Euclidean algorithm是有原因的,除了Euclidean algorithm本身相对复杂之外,短除法能同时搞定最大公约数和最小公倍数(Least common multiple),这也是它的教学优势所在。
Euclidean algorithm作为最古老的算法之一,被收录进Knuth的巨著TAOCP。这里的算法,指的是那些根据一定的规则来一步步执行的运算。
Bézout’s identity和Extended Euclidean algorithm
Euclidean division还可以表示为如下形式:
如果 a′=amod(b) a ′ = a mod ( b ) ,则 a=⌊ab⌋b+a′ a = ⌊ a b ⌋ b + a ′ 。
这里的 ⌊x⌋ ⌊ x ⌋ 是向下取整的意思。
我们可以把上述定义扩展到负数。例如:
注意:余数永远 ≥0 ≥ 0 。
还可以把GCD的定义扩展为: GCD(a,0)=a G C D ( a , 0 ) = a ,即任何整数都能整除0。
Euclidean division的定义扩展之后,则有Bézout’s identity。
Bézout’s identity:若a,b是非0整数, d=GCD(a,b) d = G C D ( a , b ) ,则存在整数x,y使得 ax+by=d a x + b y = d 。证明略。
例如:
Étienne Bézout,1730~1783,法国数学家。法国科学院院士。
至于如何求解x,y,这就要用到Extended Euclidean algorithm了。
首先,我们考虑边界情况,当 b=0 b = 0 时,原方程可化为 ax=GCD(a,0) a x = G C D ( a , 0 ) ,则:
接着,设 a′=b,b′=amodb a ′ = b , b ′ = a mod b ,则由Euclidean algorithm可得: GCD(a,b)=GCD(b,amodb) G C D ( a , b ) = G C D ( b , a mod b ) ,因此:
整理得到:
对比系数,可得:
公式1和2合到一起,就是一种迭代算法,也就是Extended Euclidean algorithm了。
从上面的讨论可知,Extended Euclidean algorithm实际上只在Euclidean algorithm之上前进了很小的一步,它的主要内核还是来源于Euclid。
但Euclid之所以不能更进一步,则主要是受制于负数的概念。虽然现在的小学高年级课本中,已经引入了负数,古代中国、印度、阿拉伯也很早就用到了负数,但是西方差不多要到文艺复兴时期,才逐渐接受了负数的概念。
不过反例也是有的,比如无理数,其它文明貌似根本就没有关注过它和有理数究竟有何区别…
参考:
https://blog.sengxian.com/algorithms/gcd-extgcd
欧几里德算法与扩展欧几里德算法
中国剩余定理
Chinese remainder theorem算是初等数论中,一个非常重要的定理了。(初等数论意指使用不超过高中程度的初等代数处理的数论问题,其最主要的工具包括整数的整除性与同余。)
CRT最早出自中国四世纪成书的古书《孙子算经》。著名的娱乐圈学霸关晓彤同学所攻克的“鸡兔同笼问题”,就出自该书。
CRT的内容为:
设 mi m i 为两两互质(pairwise coprime)的大于1的整数, ai a i 为任意整数,则存在x满足:
如果 0≤x<M,M=∏ki=1mi 0 ≤ x < M , M = ∏ i = 1 k m i ,则该x是唯一的。
CRT的存在性证明略。
这里以如下简单的例子,来讲讲如何求解x。
这个问题的穷举法需要遍历0到M的所有整数,这显然是个十分低效的算法。因此无论手算还是计算机算,基本都不用穷举法。
再来介绍一下筛法(Sieving):
1.首先对 mi m i 按降序排序。
2.选择最大的模(这里为5)和对应的 ai a i (这里为4)。
3.
{% highlight text %}
4 mod 4 → 0. Continue
4 + 5 = 9 mod 4 →1. Continue
9 + 5 = 14 mod 4 → 2. Continue
14 + 5 = 19 mod 4 → 3. OK, continue by considering remainders modulo 3 and adding 5×4 = 20 each time
19 mod 3 → 1. Continue
19 + 20 = 39 mod 3 → 0. OK, this is the result.
{% endhighlight %}
筛法对于M较小的情况,是非常高效的,因此手算一般都采用该法。但是,筛法的复杂度是指数级的,对于M较大的情况,并不好用。
CRT虽然只是初等数论的基本定理,但应用范围很广,Lagrange interpolation(一阶多项式插值)、Hermite interpolation(多阶多项式插值)和Dedekind’s theorem,都用到了CRT。
多项式的Euclidean division和GCD
我们可以仿照整数Euclidean division定义多项式的Euclidean division,如下面的竖式所示:
上式也可写为横式:
其中的 r(x) r ( x ) 即为余数。
同样的可以定义多项式的GCD:
则两多项式的GCD为 (x+1) ( x + 1 ) 。
多项式的CRT
CRT亦可改为如下等效形式:
其中 mi m i 两两互质, ci=Rmi[c],M=∏ki=0mi,Mi=M/mi c i = R m i [ c ] , M = ∏ i = 0 k m i , M i = M / m i , Ni,ni N i , n i 是方程 NiMi+nimi=GCD(Mi,mi)=1 N i M i + n i m i = G C D ( M i , m i ) = 1 的解。
显然这里的 Ni,ni N i , n i 可以使用Extended Euclidean algorithm求解。
例如:
稍加扩展,可得到多项式版本的CRT:
其中 m(i)(p) m ( i ) ( p ) 两两互质, c(i)(p)=Rm(i)[c(p)],M(p)=∏ki=0m(i)(p),M(i)(p)=M(p)/m(i)(p) c ( i ) ( p ) = R m ( i ) [ c ( p ) ] , M ( p ) = ∏ i = 0 k m ( i ) ( p ) , M ( i ) ( p ) = M ( p ) / m ( i ) ( p ) , N(i)(p) N ( i ) ( p ) 是方程 N(i)(p)M(i)(p)+n(i)(p)m(i)(p)=GCD(M(i)(p),m(i)(p))=1 N ( i ) ( p ) M ( i ) ( p ) + n ( i ) ( p ) m ( i ) ( p ) = G C D ( M ( i ) ( p ) , m ( i ) ( p ) ) = 1 的解。
Winograd algorithm
下面以一个2x3的卷积为例,介绍一下Winograd algorithm的做法。
2x3卷积的多项式形式为:
这里引入多项式(polynomial)的度(degree)的概念:多项式中包含的最高次项的次数,被称为多项式的度。
例如,上面的 h(p) h ( p ) 的degree为1,而 x(p) x ( p ) 的degree为2,而 s(p) s ( p ) 的degree为3。
和Cook-Toom algorithm一样,Winograd algorithm也是一个构造式的算法。
Step 1:首先要构造一个degree大于等于3的多项式:
其中的 m(i)(p) m ( i ) ( p ) 两两互质。
这里为了简单起见,不妨令 m(p)=p(p−1)(p+1) m ( p ) = p ( p − 1 ) ( p + 1 ) ,并使用Extended Euclidean algorithm构建如下计算表格:
| i |
m(i)(p) m ( i ) ( p )
|
M(i)(p) M ( i ) ( p )
|
n(i)(p) n ( i ) ( p )
|
N(i)(p) N ( i ) ( p )
|
|---|---|---|---|---|
| 0 |
p p
|
p2−1 p 2 − 1
|
p p
|
−1 − 1
|
| 1 |
p−1 p − 1
|
p2+p p 2 + p
|
−12(p+2) − 1 2 ( p + 2 )
|
12 1 2
|
| 2 |
p+1 p + 1
|
p2−p p 2 − p
|
−12(p−2) − 1 2 ( p − 2 )
|
12 1 2
|
Step 2:使用如下公式计算 h(i)(p),x(i)(p) h ( i ) ( p ) , x ( i ) ( p ) :
计算过程如下:
Step 3:使用如下公式计算 s′(i)(p) s ′ ( i ) ( p ) :
计算过程如下:
Step 4:根据公式3计算余数 s′(p) s ′ ( p ) ,并利用如下公式计算被除数 s(p) s ( p ) :
计算过程如下:
这里用4个乘法和7个加法,替代了6个乘法和2个加法。
总的来说,Winograd algorithm是一个很复杂的算法,但是结论却很简单。因此,在具体的IC实现中,一般只针对特定常用尺寸的kernel,应用相应的结论即可。
Winograd这个知识点的复杂,其实主要还不在于算法本身,而是在于其前置了很多数论方面的知识。而我恰恰不具备这些知识,因此进展极度缓慢,前后用了近20天才看完了相关的内容。。。不过,收获很大^_^
Winograd for CNN
CNN中的Winograd算法一般使用如下论文的结论:
《Fast Algorithms for Convolutional Neural Networks》
该文引论部分提到了Winograd算法的结论,该结论和本文上述的算法步骤略有不同,最初是Winograd针对FIR提出的Minimal FIR Filtering算法。但是算法的本质是相同的,仍然是构建多项式和CRT。
https://github.com/andravin/wincnn
这个项目可以很方便的计算不同大小的核的Winograd的结果。这个项目中还有一个pdf文件作为上述论文的补充材料,详细的给出了各矩阵的计算方法。
FFT与卷积
FFT是加速卷积运算的一种常用方法。但由于其原理,当卷积核小的时候,是没什么加速的,当核是3或者5时,速度有时更慢或者相当,而在CNN中卷积的核大多数比较小,FFT起到的加速作用很小,所以基本没人用。
参见:
http://www.cnblogs.com/jianyingzhou/p/4303578.html
convolution,fft, 加速
参考
https://colfaxresearch.com/falcon-library/
FALCON Library: Fast Image Convolution in Neural Networks on Intel Architecture
https://www.intelnervana.com/winograd/
“Not so fast, FFT”: Winograd
https://www.encyclopediaofmath.org/index.php/Winograd_small_convolution_algorithm
Winograd small convolution algorithm