intellij运行spark的maven方式
Intellij版本是2018.3.2
scala plugin使用的是:
scala-intellij-bin-2018.3.6.zip
1.Create New Project
2.Maven
选择Create from archetype
选择org.scala-tools.archetypes:scala-archetype-simple
3.GroupId和ArtifactId都填写scala-learn
然后点击Next
4.Next
5.Finish
6.进入主界面后,右下角会提示Maven projects need to be imported,
选择Import Changes.
有上方会提示:
No Scala SDK in module,选择选择Setup Scala SDK
(记得在settings-plugin中确保已经安装了scala plugin)
7.删除整个test文件夹、整个scala-learn文件夹
这里如果没有提前安装scala插件,是不会出现test文件夹的
8.在main文件夹下面新建一个object,取名为
WordCountLocal,代码在附录中。
9.修改pom.xml,完整内容如附录所示。
启动hadoop中的hdfs系统,具体的启动办法是:
alias start="/bigdata/hadoop-2.7.7/sbin/start-dfs.sh&&/bigdata/hadoop-2.7.7/sbin/start-yarn.sh"
然后终端输入start即可启动.
当然如果这不是第一次启动的话,你需要事先建立好namenode以及对namenode进行格式化.
然后,
新建一个hello.txt,然后
hdfs dfs -mkdir -p /user/ds
hdfs dfs -put hello.txt /user/ds
11.按下Alt+Shift+F10,选择WordCountLocal即可运行。
运行结果如下:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
19/03/21 19:12:14 INFO Remoting: Starting remoting
19/03/21 19:12:14 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:33403]
(eat,1)
(I,1)
(to,1)
(apple,2)
(an,1)
(yuchi,1)
(want,1)
Process finished with exit code 0
最终效果如下:
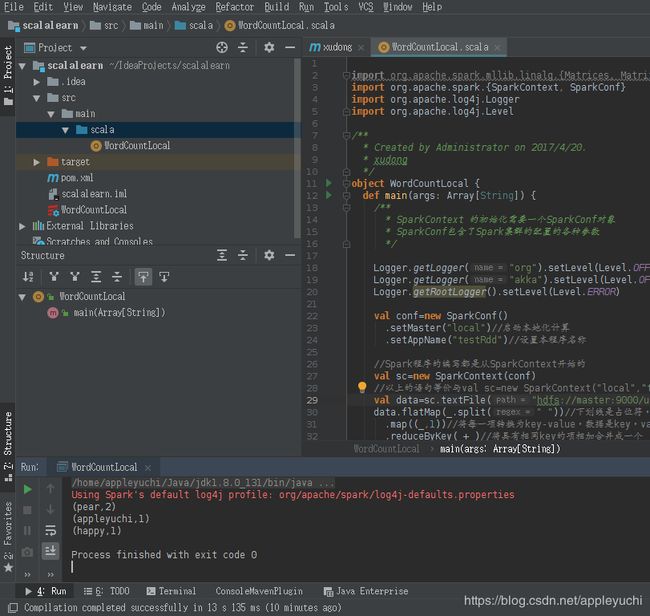
-----------------------------------------------附录-----------------------------------
代码是:
import org.apache.spark.mllib.linalg.{Matrices, Matrix}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.log4j.Logger
import org.apache.log4j.Level
/**
* Created by Administrator on 2017/4/20.
* xudong
*/
object WordCountLocal {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一个SparkConf对象
* SparkConf包含了Spark集群的配置的各种参数
*/
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("akka").setLevel(Level.OFF)
Logger.getRootLogger().setLevel(Level.ERROR)
val conf=new SparkConf()
.setMaster("local")//启动本地化计算
.setAppName("testRdd")//设置本程序名称
//Spark程序的编写都是从SparkContext开始的
val sc=new SparkContext(conf)
//以上的语句等价与val sc=new SparkContext("local","testRdd")
val data=sc.textFile("hdfs://master:9000/user/ds/hello.txt")//读取本地文件
data.flatMap(_.split(" "))//下划线是占位符,flatMap是对行操作的方法,对读入的数据进行分割
.map((_,1))//将每一项转换为key-value,数据是key,value是1
.reduceByKey(_+_)//将具有相同key的项相加合并成一个
.collect()//将分布式的RDD返回一个单机的scala array,在这个数组上运用scala的函数操作,并返回结果到驱动程序
.foreach(println)//循环打印
}
}
pom.xml:
4.0.0
com.xudong
xudong
1.0-SNAPSHOT
UTF-8
1.6.0
2.10
2.6.0
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.version}
${spark.version}
org.apache.hadoop
hadoop-client
2.6.0
org.apache.spark
spark-streaming-kafka_${scala.version}
${spark.version}
org.apache.spark
spark-mllib_${scala.version}
${spark.version}
mysql
mysql-connector-java
5.1.39
junit
junit
4.12
central
Maven Repository Switchboard
default
http://repo2.maven.org/maven2
false
src/main/scala
src/test/scala