一种日志采集装置及方法
技术领域
[0001] 本发明涉及数据采集领域,特别涉及一种日志采集装置及方法。
背景技术
[0002] 在互联网以及传统行业,“大数据”时代已经来临,各个公司、团体机构都在极力研宄、构建自己的大数据处理平台,通过对海量数据的整合、分析、统计,充分利用数据中蕴含的价值,挖掘出对企业管理、业务改进、商机捕捉等更为有用的信息,或者辅助企业网站系统的运营。而这些大规模的数据都是需要从各个应用系统中获取,对于规模较大的公司,应用系统众多,数据生成、存储方式、规范都有所不同,尤其是应用系统的日志数据。如何可靠、实时的将大规模的日志数据传送到大数据平台进行ETL(Extract-Transform-Load,萃取、转置、加载)处理、统计、分析、挖掘,是构建大数据平台必须面对的问题。
[0003] 常见的日志数据采集方式有:SNMP Trap (SNMP自陷;SNMP:Simple NetworkManagement Protocol,简单网络管理协议)机制采集、系统日志(Syslog)协议的采集、Telnet采集及文本方式(Mail (邮件)或FTP(File Transfer Protocol,文本传输协议))采集等。而某些互联网公司使用rsync (类unix系统下的数据镜像备份工具)服务定时的将数据传送到大数据平台,然后由大数据平台的监测程序完成数据入库操作。
[0004] 最近随着大数据的不断地被互联网公司、学术机构认可并应用,开源的数据采集方案如Apache Flume和Kafka等越来越受业界关注。Cloudera开源出来的Flume可以实现点对点的实时数据传输,且支持多种数据源的采集。Linkedln的Kafka是一个分布式、分区的、多副本的、多订阅者的“提交”日志系统,采用的策略是:生产者把数据推到Kafka集群上,而消费者主动去集群上拉数据。
[0005]目前的日志采集方案,不能在实时地进行日志采集时,还能够避免垃圾数据产生、数据丢失,并且能够及时进行断点续传。
发明内容
[0006] 本发明针对上述问题,提出了一种日志采集装置及方法,用以在实时地进行日志采集时,能够避免垃圾数据产生、数据丢失,并且还能够及时进行断点续传。
[0007] 本发明提供了一种日志采集装置,包括:
[0008]日志监控模块,用于监控当前服务器上的多个应用系统的日志文件;确定各日志文件新增的记录,并保存各日志文件以及新增的记录;
[0009] 数据传输服务模块,用于将新增的记录进行跨网传输以导入云平台的HDFS功能,和/或,根据需要将保存的日志文件进行跨网传输以导入云平台的HDFS功能。
[0010] 本发明提供了一种日志采集方法,包括如下步骤:
[0011] 监控当前服务器上的多个应用系统的日志文件;
[0012] 确定各日志文件新增的记录,并保存各日志文件以及新增的记录;
[0013] 将新增的记录进行跨网传输以导入云平台的HDFS功能,和/或,根据需要将保存的日志文件进行跨网传输以导入云平台的HDFS功能。
[0014] 本发明有益效果:
[0015] 相对于现有技术中只能定时定点传送的方案,由于在本发明实施例提供的技术方案中,在确定各日志文件新增记录后便将新增的记录进行跨网传输导入云平台的HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)功能,因此能够满足实时性要求,同时也能在数据量增加时能够及时处理大规模的实时数据。
[0016] 而对于点对点的实时数据传输,导致众多垃圾数据传送到大数据平台以及不能及时断点续传、数据丢失的方案,由于在本发明实施例提供的技术方案中,仅传输各日志文件新增的记录,因此避免了垃圾数据的传送;同时,由于在本发明实施例提供的技术方案中还保存了各日志文件以及新增的记录,使得原日志文件以及上传的记录变化都是可以查询获知的,当需要进行断点续传或者重传丢失的数据时,查询获取相应的数据重传即可,克服了现有技术不能及时断点续传、以及数据丢失的问题。
附图说明
[0017] 为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
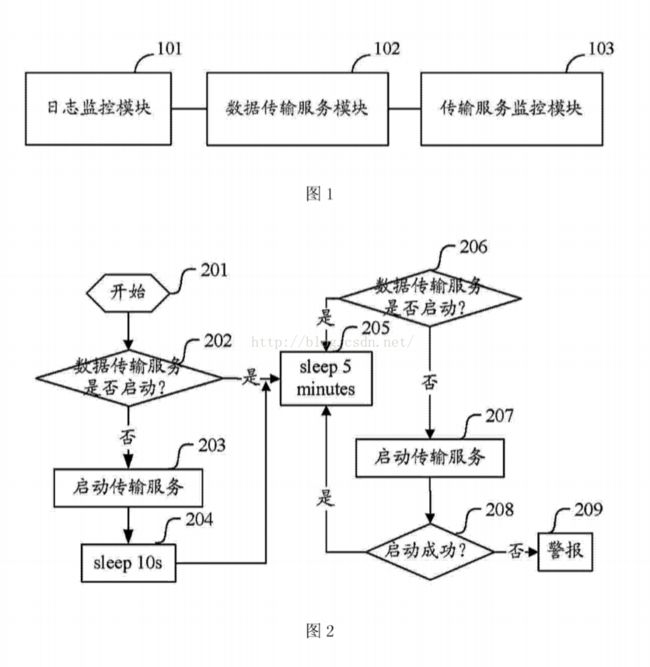
[0018] 图1为本发明实施例中日志采集装置的结构示意图;
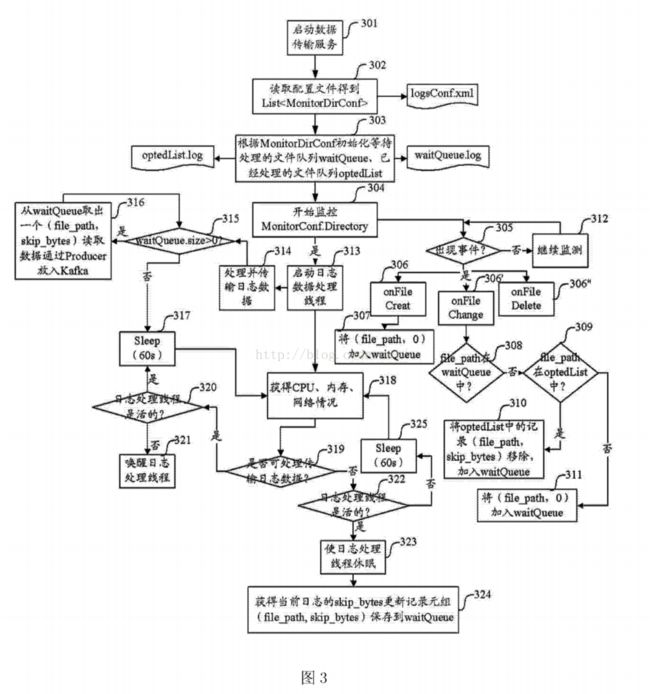
[0019]图2为本发明实施例中传输服务监控模块的实施流程示意图;
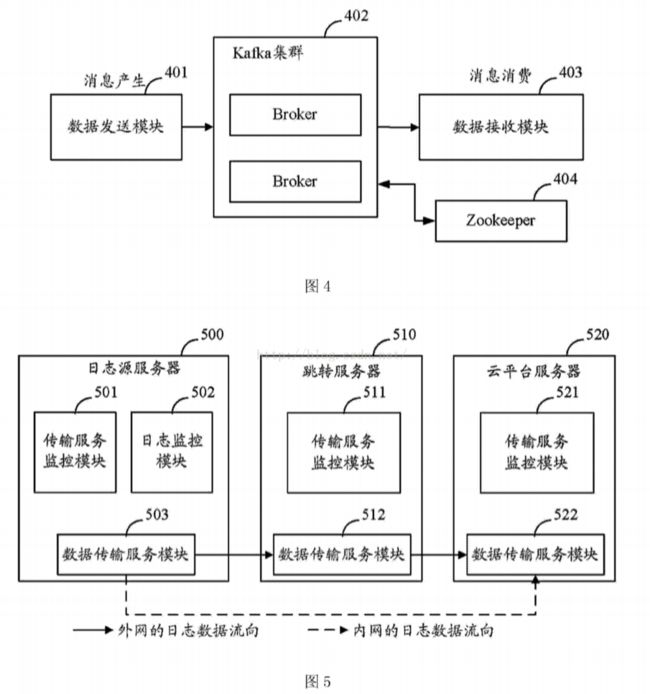
[0020] 图3为本发明实施例中日志监控模块的实施流程示意图;
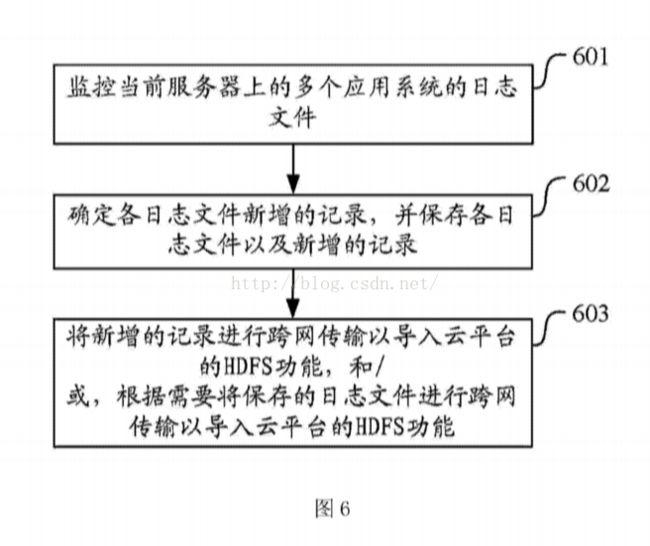
[0021]图4为本发明实施例中数据传输服务模块的实施流程示意图;
[0022] 图5为本发明实施例中数据传输流示意图;
[0023] 图6为本发明实施例中提供的日志采集方法实施流程示意图。
具体实施方式
[0024] 为了使本发明的技术方案及优点更加清楚明白,以下结合附图对本发明的示例性实施例进行进一步详细的说明,显然,所描述的实施例仅是本发明的一部分实施例,而不是所有实施例的穷举。
[0025] 发明人在发明过程中注意到:
[0026] 常见的数据采集方式有着明显的缺点。比如使用rsync服务采集日志,只能定时定点传送,不能满足实时性要求。而且随着业务的增加,定时任务的管理会越来越混乱。同时数据量的增加使得现有的方式不能及时处理大规模的实时数据。使用Syslog采集数据过分的依赖于Syslog服务,且该方案也仅适用于服务器系统日志数据采集。
[0027] Apache Flume缺点也很明显,对数据的ETL功能有限,该方案会导致众多垃圾数据传送到大数据平台,不但占用网络带宽而且对大数据平台的后续处理带来压力;而且,在Flume出现问题后不能及时从断点续传,数据会有丢失现象;同时,Flume对应用系统的侵入度太大,操作不当会毁损应用系统原有的文件;当数据量大时,数据会得不到及时,会在某个节点堆积数据,对该节点的存储带来极大压力。
[0028] 而该方案中的Kafka是一个消息传输的中间件,提供的简单的API (Applicat1nProgramming Interface,应用程序编程接口),编程难度大,而且本身不具有采集数据的功能,只能作为数据传输的一个临时通道。
[0029] 基于现有技术的上述不足,本发明实施例中提供了一种日志采集装置,下面进行说明。
[0030] 图1为日志采集装置结构示意图,如图1所示,装置中可以包括:
[0031]日志监控模块101,用于监控当前服务器上的多个应用系统的日志文件;确定各日志文件新增的记录,并保存各日志文件以及新增的记录;
[0032] 数据传输服务模块102,用于将新增的记录进行跨网传输以导入云平台的HDFS功能,和/或,根据需要将保存的日志文件进行跨网传输以导入云平台的HDFS功能。
[0033] 实施中,日志监控模块用于实现对多点、多系统的日志目录的实时监控,提取新增的日志记录供数据传输服务模块传输,具体实施中可以设置一个目录,如本发明实施例中命名为spooldir的目录,日志监控模块可以将提取的新增的日志记录放入数据传输服务模块监控的spooldir目录,数据传输服务模块在该目录监控到有新增文件后就进行发送。
[0034] 数据传输服务模块用于实现日志数据跨网传输,以及将日志数据导入HDFS功能。
[0035] 实施中,还可以进一步包括:
[0036] 传输服务监控模块103,用于监控记录和/或日志文件的传输过程,以使数据传输服务模块的传输进程处于运行状态。
[0037] 实施中,传输服务监控模块用于监控数据传输服务的运行,保证传输Agent (代理)处于运行状态;具体的,传输服务监控模块是数据传输服务模块运行状态的监控模块,负责该模块的启动,并保证该模块的服务进程处于运行状态。实施中,该模块可以分为两部分:(1)初始启动数据传输服务(2)循环监控数据传输服务运行状态。图2为传输服务监控模块的实施流程示意图,如图2所示,传输服务监控模块具体的实施流程可以如下:
[0038] 步骤201:开始。
[0039] 步骤202:判断数据传输服务器是否启动,若数据传输服务启动,执行步骤205 ;若数据传输服务没有启动,执行步骤203。
[0040] 步骤203:启动传输服务。
[0041] 步骤204:sleep 10s,即休眠10秒钟,具体的休眠时间长度可以根据具体实施中的情况而确定,这里休眠设为10秒钟仅作示例说明,不作具体限定。
[0042] 步骤205:sleep 5minutes,即休眠5分钟,同上,具体的休眠时间长度可以根据具体实施中的情况而确定。
[0043] 步骤206判断数据传输服务器是否启动,即:再次判断数据传输服务器是否启动,若此次数据传输服务启动,执行步骤205 ;若此次数据传输服务没有启动,执行步骤207。
[0044] 步骤207:启动传输服务。
[0045] 步骤208:判断启动传输服务是否成功,若启动传输服务成功,执行步骤205 ;若启动传输服务不成功,执行步骤209。
[0046] 步骤:209:警报,即:以文字、声音、图像或其他能够表示该警报信息的形式向日志维护相关工作人员发出警报信息,便于及时对数据传输故障进行分析与解决。
[0047] 实施中,日志监控模块还可以进一步用于通过监听所监控的应用系统的文件的修改、或创建、或删除事件的线程并响应来对应用系统进行监控。也即,日志监控模通过监听所监控的文件的修改、创建、删除等事件的线程并响应来实现对文件的监控。
[0048] 实施中,日志监控模块还可以进一步用于在保存各日志文件以及新增的记录时,在内存中保存各日志文件以及新增的记录,并标识已经处理或未处理;定时将已经处理或未处理的各日志文件以及新增的记录保存至磁盘文件。
[0049] 具体的,日志监控模块主要负责监控当前服务器上的多个应用系统的日志文件。具体处理逻辑的流程如下述图3所示。具体实施中,可以通过让该模块维护两份记录数据待处理的文档队列和已经处理过的文档列表,例如在内存中以waitQueue和optedList形式存在,然后定期写入磁盘文件中。
[0050]日志监控模块初次启动将历史日志文件分批次拷贝到数据传输服务模块,记录各个文件传输点位置,保存到一个记录板文件中。该模块正常运行后,将日志文件新增的记录传送到数据传输服务模块,并保存各个文件的已读取位置,以及属于哪个系统等信息。该模块的记录板可以在整个服务出现故障后能够及时恢复数据传输。同时模块通过配置要监控的目录、系统信息、采集频率实现对多点多系统的日志数据的可控传输。
[0051 ] 图3为日志监控模块的实施流程示意图,如图3所示,日志监控模块具体的实施流程可以如下:
[0052] 步骤301:启动数据传输服务,即:启动传输日志数据的传输服务。
[0053] 步骤302:读取配置文件得到List〈MonitorDirConf>,即读取日志数据采集的配置文件,根据日志数据采集的配置文件得到
[0054] List
[0055] 步骤303:根据MonitorDirConf初始化等待处理的文件队列waitQueue、已经处理的文件队列optedList,根据监测目录的配置信息,将日志数据进行初始化分类,将日志数据待处理的文件归入waitQueue,将已经处理过日志数据的文件归入optedList,从而得到记录等待处理的文件队列waitQueue.log和已经处理的文件队列optedList.logo
[0056] 步骤304:开始监控MonitorConf.Directory,即:开始监控根据日志数据采集配置文件得到的监测目录中的文件。
[0057] 步骤305:判断是否出现事件,这里的事件具体是指文件创建、修改或删除事件。若出现事件,执行步骤306、306’或306” ;若未出现事件,执行步骤312。
[0058] 步骤306:步骤305中出现的事件为onFileCreat,即出现创建文件的事件时,执行步骤307。
[0059] 步骤306’:步骤305中出现的事件为onFileChange,即出现修改文件的事件时,执行步骤308。
[0060] 步骤306”:步骤305中出现的事件为onFileDelete,即出现删除文件的事件时,记录该删除文件记录。
[0061] 步骤307:将记录元组(file_path,0)加入waitQueue,将创建文件事件日志记录涉及的文件路径及该日志记录需跳过的字节数0加入到waitQueue中。
[0062] 步骤308:判断file_path是否在waitQueue中,即:判断修改文件事件日志记录涉及的文件路径是否在waitQueue中,若不在,执行步骤309。
[0063] 步骤309:判断file_path是否在optedList中,即:当判断修改文件事件日志记录涉及的文件路径不在waitQueue中,继续判断修该日志记录涉及的的文件路径是否在optedList中,若在optedList中,执行步骤310 ;若步骤optedList中,执行步骤311。
[0064]步骤 310:将 optedList 中的记录元组(file_path,skip_bytes)移除,加入waitQueue,即,当判断修改文件事件日志记录涉及的的文件路径在optedList中,将optedList中的该文件路径和该日志记录需跳过的字节数记录移除,将optedList中的该文件路径和该日志记录需跳过的字节数的记录元组加入到waitQueue中。
[0065] 步骤311:将记录元组(file_path,0)加入waitQueue,即:当判断修改文件事件日志记录涉及的的文件路径不在optedList中时,说明该日志记录未被处理过,该日志记录需跳过的字节数为0,将该日志记录涉及的的文件路径和该日志记录需跳过的字节数0加入到waitQueue中。
[0066] 步骤312:继续监控,S卩:当前没有出现创建、修改或删除文件的事件时,继续监控有无创建、修改或删除文件的事件发生。
[0067] 步骤313:启动日志数据处理线程。
[0068] 步骤314:处理并传输日志数据。
[0069] 步骤315:判断是否waitQueue.size >0,即:判断等待处理的文件队列waitQueue大小是否大于0,若大于0,执行步骤316 ;若不大于0,执行步骤317:
[0070] 步骤316:从waitQueue取出一个记录元组(f ile_path,skip_bytes)读取数据通过 Producer 放入 Kafka,即:从 waitQueue 中取一个记录元组(f ile_path,skip_bytes),该记录元组包括的信息为该日志记录涉及的文件路径及该日志记录需跳过的字节数,依据此元组数据从相应日志文件中读取数据,由Kafka中的数据生产者(producer)放入Kafka的消息队列中。
[0071] 步骤317:Sleep(60s),即:休眠60秒,具体的休眠时间长度可以根据具体实施中的情况而确定,这里仅作示例说明,不作具体限定。
[0072] 步骤318:获得CPU、内存、网络情况,即:获得服务器的CPU、内存和/或网络质量等情况。
[0073] 步骤319:判断是否可以处理并传输日志数据,即:通过获得的服务器的CPU、内存和/或网络质量确定是否可以处理并传输日志数据,若可以处理并传输日志数据,执行步骤321 ;若不可以处理并传输日志数据,执行步骤322。
[0074] 步骤320:判断日志处理线程是否是活的,若日志处理线程是活的,执行步骤317 ;若日志处理线程不是活的,执行步骤321。
[0075] 步骤321:唤醒日志处理线程。
[0076] 步骤322:判断日志处理线程是否是活的,若日志处理线程是活的,执行步骤323 ;若日志处理线程不是活的,执行步骤325。
[0077] 步骤323:使日志处理线程休眠。
[0078] 步骤324:获得当前日志的skip_bytes更新记录元组(file_path,skip_bytes)保存到waitQueue,即:获得当前日志记录需跳转的字节数,将日志记录涉及的文件路径及该当前日志记录需跳转的字节数保存至待处理的文件队列中。
[0079] 步骤325:Sleep (60s),即:休眠60秒,具体的休眠时间长度可以根据具体实施中的情况而确定。
[0080] 实施中,数据传输服务模块还可以进一步用于采用分布式消息系统Kafka提供的应用程序编程接口 API暂时存储所述日志数据,在将所述日志数据导入至Hadoop分布式文件系统时,使用Simple Consumer接口利用Zookeeper (分布式协调系统)同步机制保存对所述日志数据消费的偏移量。
[0081] 具体的,数据传输服务模块作为数据采集的基础层,实现日志数据、交易数据的跨网传输,以及数据导入云平台的HDFS功能。此模块可以采用Kafka提供的API接口实现数据的短暂存储,确保数据可以重复消费,在数据导入HDFS时,使用SimpleConsumer的接口,利用Zookeeper的同步机制保存消费点OFFSET,对Kafka集群中的不同Topic的数据进行消费。Kafka是一种显式的分布式系统。Kafka假设,数据生产者、代理(Brokers)和数据使用者(consumer)分散于多台机器之上。由数据生产者发布关于某话题(topic)的消息,消息被发送至作为代理的服务器。若干的数据使用者订阅某个话题,然后数据生产者所发布的每条消息都会被发送给所有的使用者。具体实施流程如下述图4所示。在数据接收模块通过读取配置文件,实现对不同日志的ETL功能。
[0082] 在实施中,数据传输模块中Kafka可以使用其他消息中间件代替,只要能够提供消息传输服务即可。
[0083]图4为数据传输服务模块的实施流程示意图,如图4所示,数据传输服务模块具体的实施流程可以如下:数据传输服务模块采用Kafka提供的API接口,有数据生产者对应的是图4中的数据发送模块401,数据发送模块将数据发送至由多个代理(Broker)组成的Kafka集群402,数据使用者这里对应的是图4中的数据接收模块403,数据接收模块从Kafka集群中的代理处接收数据,进行消息消费。在Kafka中,由数据使用者负责维护反映哪些消息已被使用的状态信息,通常用偏移量表示那些消息已被使用。典型情况下,Kafka使用者的库会把状态数据保存到Zooke印er404之中。通常Kafka是运行在集群中的服务器上,没有中央的“主”节点,代理彼此之间是对等的,不需要任何手动配置即可随时添加或删除。同样,数据发送模块和数据接收模块可以在任何时候开启。每个代理都可以在Zookeeper中注册的一些元数据,例如,可用的主题。数据发送模块和数据消费者可以使用Zookeeper发现主题和相互协调。
[0084] 实施中,数据传输服务模块还可以进一步用于在传输记录和/或日志文件至云平台服务器时,当日志采集装置位于内网时,将记录和/或日志文件传输至云平台服务器;或,当日志采集装置位于外网时,在内网设置单向传输的跳转节点,通过跳转节点传输记录和/或日志文件至云平台服务器。
[0085] 具体的,图5为数据传输流示意图,如图5所示,为了要满足跨网络传输,即日志采集装置所在的日志源服务器500可能在公司内网也可能在外网,日志源服务器500中包括:传输服务监控模块501、日志监控模块502和数据传输服务模块503。通过在内网的服务器上设置一个跳转节点-跳转服务器510,在防火墙系统中为其开通单向传输的端口,跳转服务器510包括:传输服务监控模块511和数据传输服务模块512。其中对于外网日志数据需要经过跳转服务器节点的过渡处理,间接传送到云平台服务器520然后导入HDFS,云平台服务器520包括:传输服务监控模块521和数据传输服务模块522。内网的日志数据直接通过数据传输服务模块传输到云平台的服务器上然后导入到HDFS中。
[0086] 基于同一发明构思,本发明实施例中还提供了一种日志采集方法。由于该方法解决问题的原理与一种日志采集装置相似,因此该方法的实施可以参见装置的实施,重复之处不再赘述。
[0087] 图6为本发明实施例中提供的日志采集方法实施流程示意图,如图6所示,可以包括如下步骤:
[0088] 步骤601:监控当前服务器上的多个应用系统的日志文件;
[0089] 步骤602:确定各日志文件新增的记录,并保存各日志文件以及新增的记录;
[0090] 步骤603:将新增的记录进行跨网传输以导入云平台的HDFS功能,和/或,根据需要将保存的日志文件进行跨网传输以导入云平台的HDFS功能。
[0091 ] 实施中,还可以进一步包括:
[0092] 监控记录和/或日志文件的传输过程,以使传输进程处于运行状态。
[0093] 实施中,监控当前服务器上的多个应用系统的日志文件,是通过监听所监控的应用系统的文件的修改、或创建、或删除事件的线程并响应来对应用系统进行监控的。
[0094] 实施中,保存各日志文件以及新增的记录,可以包括:
[0095] 在内存中保存各日志文件以及新增的记录,并标识已经处理或未处理;
[0096] 定时将已经处理或未处理的各日志文件以及新增的记录保存至磁盘文件。
[0097] 实施中,还可以进一步包括:
[0098] 采用分布式消息系统Kafka提供的应用程序编程接口 API暂时存储所述日志数据,在将所述日志数据导入至Hadoop分布式文件系统时,使用Simple Consumer接口利用Zookeeper同步机制保存对所述日志数据消费的偏移量。
[0099] 实施中,传输记录和/或日志文件至云平台服务器,可以包括:
[0100] 当监测的服务器位于内网时,将记录和/或日志文件传输至云平台服务器;或,当监测的服务器位于外网时,在内网设置单向传输的跳转节点,通过跳转节点传输记录和/或日志文件至云平台服务器。
[0101] 由上述实施例可见,在本发明实施例提供的技术方案是一种基于大数据平台的多点、可靠的大规模实时日志数据采集方案。提供了文件监控的处理及其恢复机制;进一步的,使数据传输服务与Kafka的有机结合,借用其消息发布机制,开发完善的消息消费实现数据传输;进一步的,监控日志文件可配置,并且实现多线程监控日志目录,多线程处理新增日志发送到日志传输服务。
[0102] 由于在方案中对当前服务器上的多个应用系统的日志文件进行监控,因此可以多点采集,让更多的系统为大数据平台输送数据。进一步的,可以通过配置日志监控模块式,便可以采集不同应用系统的多种日志,每条记录都有所属系统、日志种类的标记,丰富数据的采集;由于在传输各日志文件新增的记录的同时,还保存了各日志文件以及新增的记录,因此可以实现可靠、稳定传输,支持断点续传,出现故障后也能够及时恢复数据传输。具体而言,一方面可以通过对waitQueue和optedList两个记录的维护,便可支持断点续传,进一步的,同时通过使用Kafka作为传输通过,所有的消息可以在Kafka集群上保留N天,可缓解大数据量对单点带来的存储压力,另一方面服务监控模块可以保证数据传输模块的正常运行;由于通过监控,能够实时发现各日志文件的变动,因而也能对新增的变动实时传输,实现了实时的传输大规模数据,让分析、挖掘系统能充分发挥数据的实时价值。
[0103] 为了描述的方便,以上装置的各部分以功能分为各种模块或单元分别描述。当然,在实施本发明时可以把各模块或单元的功能在同一个或多个软件或硬件中实现。
[0104] 本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
[0105] 本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0106] 这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0107] 这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0108] 尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0109] 显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。