VGGNet 学习小记
参考很多,仅为个人学习记录使用
论文:Very Deep Convolutional Networks forLarge-Scale Image Recognition
发表时间:2014
一、网络结构

论文中训练了 6 种结构不同的网络:A、A-LRN、B、C、D、E。
这些结构都有一个统一的框架:Input -> (Conv stage ->MaxPool) * 5 -> FC * 3 -> Soft-max。在每一个隐藏层后面都连接一个 ReLU 激活函数。

不同的结构只是改变了 Conv stage 中卷积层的数量。
- 结构 A:1 -> 1 -> 2 -> 2 -> 2;
- 结构 A-LRN:与 A 结构相同,但在 Conv stage1 里加入了 LRN 层;
- 结构 B:在 A 的 Conv stage2 和 Conv stage3 分别增加一个 3*3 的卷积层;
- 结构 C:在 B 的 Conv stage3、 Conv stage4、 Conv stage5 分别增加一个 1*1 的卷积层;
- 结构 D(VGG-16):在 B 的 Conv stage3、 Conv stage4、 Conv stage5 分别增加一个 3*3 的卷积层;
- 结构 E(VGG-19):在 D 的 Conv stage3、 Conv stage4、 Conv stage5 分别增加一个 3*3 的卷积层;
效果对比:
- A 与 A-LRN 比较:A-LRN 效果没有 A 好,说明 LRN 作用不大;
- A 与 B、C、D 比较:A 是层数最少的,也是效果最差的,可见层数对效果有影响;
- B 与 C 比较:C 中增加了 1*1 卷积层,在深度不变的情况下,增加了网络的非线性,效果有提升;
- C 与 D 比较:3*3 的卷积层比 1*1 的卷积层效果好;
VGG 网络中所有卷积层都是 kernal_size = 3,stride = 1,padding = 1
这样做的好处有:
- 3*3 是最小的能够捕获左、右、上、下和中心特征的尺寸;
- 两个 3*3 卷积连接可以视为 5*5 的卷积,三个 3*3 的卷积连在一起可以视为 7*7 的卷积;多个小卷积层比一个大卷积层有更多的非线性,且具有更少的参数。
VGG 网络的一个问题是参数过多,这主要是因为它有三个全连接层,卷积层的增加对参数数量的影响不是很大,由下图可以看出:

二、训练与测试
VGG 网络的输入尺寸是 224 * 224,而数据集中的图片尺寸不一,为了获得尺寸为 224 * 224 大小的图片,每张图片在输入前进行裁剪,为了进一步的增加训练集,对每张图片进行水平翻转以及进行随机RGB色差调整。
原始图片进行裁剪时,原始图片的最小边不宜过小,这样的话,裁剪到 224 * 224 的时候,就相当于几乎覆盖了整个图片,这样对原始图片进行不同的随机裁剪得到的图片就基本上没差别,就失去了增加数据集的意义;但同时也不宜过大,这样的话,裁剪到的图片只含有目标的一小部分,也不是很好。最好将原图缩放到一个合适的尺寸 S,然后再进行裁剪。
在训练阶段,针对上述裁剪的问题,提出了两种解决办法:
- 固定最小边尺寸为 256 来训练网络,然后固定最小边尺寸为 384 来 fine-tune 网络;
- 随机从 [256, 512] 范围内进行抽样,作为最小边的长度。这样原始图片尺寸不一,有利于训练。这个方法叫做尺度抖动(scal jittering),有利于训练集增强;
在测试阶段,依然对测试图像进行 rescale 到预设尺度 Q,测试图像的尺寸 Q 与训练图像的尺寸 S 没有关系。在论文中,作者对于每个训练图像的 S 都用了几个不同的 Q 来进行预测,可以得到更好的性能。
在 rescale 之后,有两种提升测试结果的方式:multi-crop 和 dense。
multi_crop
论文中,multi-crop 是在原图左上角选取一个 5*5 的网格,将 crop 出的 224*224 的图像的左上角分别放在每个格子中(因此原图的尺寸至少为 224 + 5 - 1 = 228),另外加上水平翻转,则一共有 5 * 5 * 2 = 50 种情况,在 test 阶段选取了三个不同的 Q,那么每张图就有 150 个 crop 图像。网络会跑一张图的 150 个 crops 然后将结果做 average。
dense
dense 与 FCN 的思想类似,作者将训练网络中的三个全连接层依次转换成了 1 个 conv 7*7,2 个 conv 1*1,也就是三个卷积层,改变之后,由于没有了全连接层,网络的输入就可以是任意尺寸的图像了,不需要进行 crop.
转换的过程中,全连接层的参数数量与卷积层的参数数量是一样的,因此直接使用全连接层的网络参数构成卷积层。
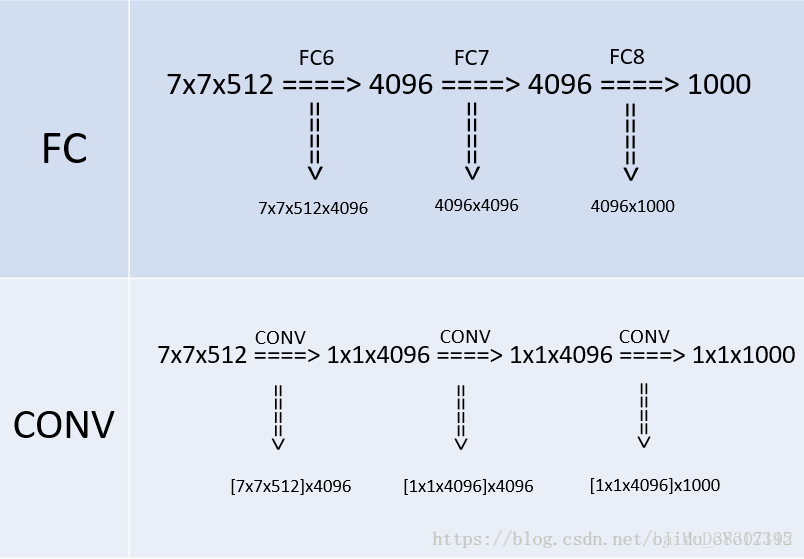
以第一个全连接层转换成卷积层的部分为例,在全连接层中,输入为 7*7*512 个节点,输出为 4096 个节点,那么这一层的参数总数为 7*7*512*4096。在卷积层中,每一个 fliter 的卷积核参数为 7*7*512,输出 fliter 为 4096 层,因此参数为 [7*7*512]*4096。
当输入的测试图片尺寸为 224 *224 时,dense 部分可以恰好输出 1*1*1000 的结果用于 soft-max。当输入的测试图片尺寸为其它尺寸时,如 384*384,输出为 6*6*1000。因为 Soft-max 只能接受 1*1*1000 的输入,所以对每个 fliter 的 6*6 特征图做了 average,得到一个值作为结果。
三、结果评估
单尺度评估
使用单尺寸的训练图像和单尺寸的测试图像,对 6 种网络结构进行性能比较。测试图像的尺寸设定分为两种情况:
- 当训练图像尺寸 S 固定时,设置测试图像尺寸 Q = S;
- 当训练图像尺寸介于 [S_min, S_max] 之间时,设置测试图像尺寸 Q = 0.5(S_min + S_max);

作者发现,即使是单一尺度(Scale),训练时进行尺度随机(scale jittering)resize 后再 crop 图像的方式比固定最小边后再 crop图片去训练的效果好。也再次印证了对训练图像以 scale jittering 的方式做 augmentation(捕捉多尺度信息上)是有效果的。
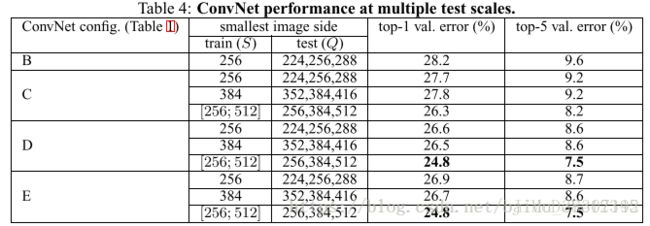
多尺度评估
训练图像和测试图像的尺寸设置有两种情况:
- 用固定大小的尺度S训练的模型,用三种尺寸Q去评估,其中Q=[S–32,S,S+32];
- 用尺度S随机的方式训练模型,S∈[S_min, S_max],评估使用更大的尺寸范围Q={S_min, 0.5(S_min+S_max), S_max}
多 crop 评估
比较 multi-crop 和 dense 两种方式
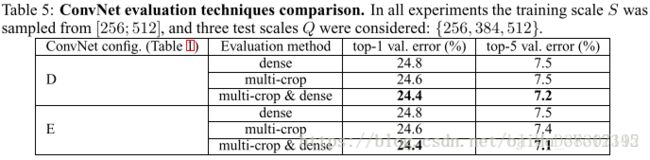
multi-crop 比 dense 的性能稍好,但是计算量太大。两者结合,效果会更好。
四、VGG 的 PyTorch 实现
1.CNN 部分
# 卷积层构造函数
# 传入的 cfg 参数表示层类型和层结构
# batch_norm 表示是否使用 BN
def make_layers(cfg, batch_norm=False):
layers = []
# 默认输入维度为 3
in_channels = 3
for v in cfg:
# M 表示 MaxPooling 层, size=2, stride=2
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
# v 表示这一卷积层的输出维度
# in_channels 的初始值为 3,之后随着卷积层的增加而变化
# 全用 3*3 卷积,步长为 1,padding 为 1
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
# 如果选择 BN 模式,就在卷积层和激活函数之间加入 BN 层
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
# 更新卷积层的输入维度
in_channels = v
# 返回一个 nn 层序列
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}2.VGG 网络
# VGG 类
# 输入参数 features 是 CNN 部分的网络结构
# num_classes 表示分类数量
# init_weights 表示初始化模式
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights =True):
super(VGG, self).__init__() # 必加
# CNN 部分
self.features = features
# 全连接部分
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
# 前向传播
def forward(self, x):
# CNN
x = self.features(x)
# 展平输入维度
x = x.view(x.size(0), -1)
# 全连接层
x = self.classifier(x)
return x
# 初始化参数函数
# 是 PyTorch 中最常用的初始化函数
def _initialize_weights(self):
for m in self.modules():
# 初始化卷积层参数
# 使用针对 ReLU 的初始化方法:均值为 0,方差为 2/n
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
# BN 层,全 1 初始化
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# 全连接层,均值为 0,方差为 0.01
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()3.生成 VGG 网络
# 普通 VGG-16
def vgg16(pretrained=False, **kwargs):
"""VGG 16-layer model (configuration "D")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
# 如果使用预训练模型,就把参数初始化设为 False
if pretrained:
kwargs['init_weights'] = False
# VGG-16 对应结构 D
model = VGG(make_layers(cfg['D']), **kwargs)
if pretrained:
# 预训练模型参数加载
model.load_state_dict(model_zoo.load_url(model_urls['vgg16']))
return model
# 使用 BN 的 VGG-16
def vgg16_bn(pretrained=False, **kwargs):
"""VGG 16-layer model (configuration "D") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['D'], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16_bn']))
return model