Mask R-CNN 学习笔记
Mask R-CNN学习笔记
-
- 前述
- 从VGG Net 到Res Net
- 从ROI Pooling 到ROI Align
-
- 量化误差是从哪来的
- ROI Align的改进之处
- 网络结构
-
- FPN网络
- 损失函数
- 参考博客
前述
从R-CNN ,fast R-CNN,faster R-CNN一直看到了现在的mask R-CNN,一步一步看着从detection到segmentation是如何一步一步走来的,人们是如何改进的。前面几篇文章作为了解,但是Mask R-CNN必须作为精读。好了,不多说了,进入正题吧。 想学Mask R-CNN必须了解之前的工作,大家可以看我之前写的学习笔记。
Fast R-CNN 学习笔记
Faster R-CNN 学习笔记
关于R-CNN的笔记因为之前是记到了word里,有时间会整理出来一篇博客的。
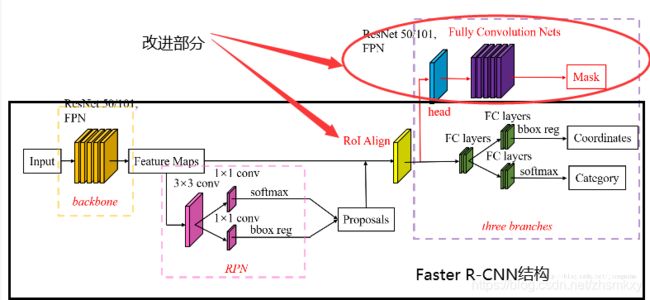
Mask R-CNN是继承于Faster R-CNN的,Mask R-CNN只是在Faster R-CNN上加了一个Mask prediction Branch(Mask 预测分支),并且改良了基于Fast R-CNN的ROI Pooling(感兴趣区域池化层or空间金字塔池化层),提出了ROI Align。
从VGG Net 到Res Net
关于Res Net的介绍可以参看我之前写的一篇博客
Res Net学习笔记
https://blog.csdn.net/zhsmkxy/article/details/107040068
从ROI Pooling 到ROI Align
量化误差是从哪来的
首先说一下,为什么要针对ROI pooling层进行改进,因为之前Faster R-CNN的任务还是做detection,也就是说对于目标物需要给出一个框,但是从mask R-CNN开始多了一个任务就是做segmentation,segmentation的任务是pixel级别的,

要想把物体从像素级别抠出来,就需要在算法层面进行改进,主要使得原图区域到特征图谱区域的映射关系中的量化误差减小。所以接下来我们需要对比一下误差出现在什么地方了。(下面这个例子出现在很多博客中,我也拿这个例子举例,加入自己的理解。)
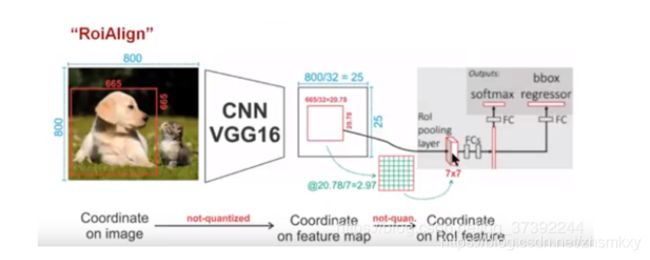
我们现在的输入是:800×800的图片和一个已知左上角和右下角坐标的大小为665×665的框(代表狗)(再说明一下,在训练过程中我们得到是FPN传来的region,不是原图中的region),我们知道经过卷积池化后得到的特征图谱是降维过的(降维处理主要是由pooling层完成),在VGGNET16中,我们经过5层pooling层最后会把原图缩小到原来的1/32。然后现在我们需要找的是我们整个在原图上大小为665×665的框映射到了特征图谱的哪。经过计算,665/32×665/32=20.78×20.78。

因为我们并不能在特征图上找到20.78的区域,0.78没办法找,所以这个地方是采用了直接取整,取20,所以就会大概产生上图所示的效果,我们会发现我们的region整体向右上方移动了一下,这个对于像素级分割任务来说,可能特征图上产生的误差不大,但特征图上的误差是会放大的,0.78*32=24.96,相当于产生了20多个像素的误差,这样的话对于物体的边缘部分的分割来说,误差已经相当大了。其次我们现在得到了20×20的这个区域,然后要经过进一步分割池化成7×7的区域才能输入到接下来的全连接层中。要把20×20分成7×7,这个肯定是均分不了,因为我没有看源码,看了这么多博客,有的博客说20/7=2.86,然后直接取整,那么2×7=14,这直接把区域缩小一块,这完全不合理,这样的误差太大了(原文论文中采用四舍五入) 。我倾向于这时候的操作是分成了3 3 3 3 3 3 2这样的区域,然后在此区域上再进行最大值池化,但是这也会产生误差,我觉得此时的误差在于我经过计算之后得到的这个7×7的区域经过全连层后然后产生边框回归那部分时候,是按照7×7的区域每一块尺寸相等反映射的,但实际上7×7的区域每一块的区域并不是严格尺寸相等。综上所述,我们就会发现在原有Faster R-CNN的网络架构上无法做分割任务的原因了。
接下来,我们就看看Mask R-CNN网络是如何改进的?
ROI Align的改进之处
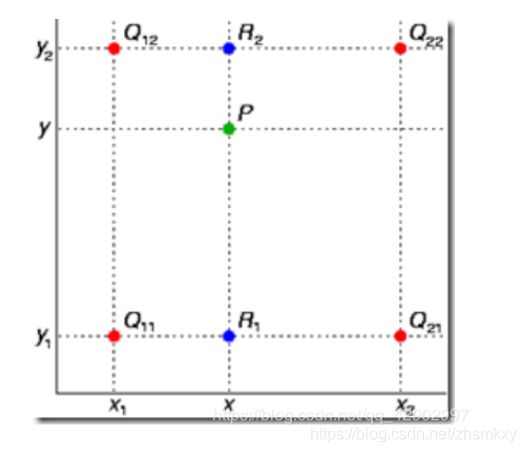
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进方法。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点。

还是上图中的这个区域,20.78就20.78吧,我们不动了,然后将这个20.78的区域分成4个尺寸相等的区域,每一个区域的大小为10.39×10.39,紧接着,我们需要在每个找4个采样点,至于说为什么是4个,原文是这样设置的,作者发现采样点设为4会获得最佳性能。也有论文针对这个地方进行过进一步的改进,比如直接算这个区域的均值。而不是选出4个采样点再池化。我们用下面三个步骤总结一下。
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k x k个单元,每个单元的边界也不做量化。(k由全连层网络决定)
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
事实上,ROI Align在遍历取样点的数量上没有ROI Pooling那么多,但却可以获得更好的性能,这主要归公于解决了misalignment(原图和特征图区域对不齐)的问题。
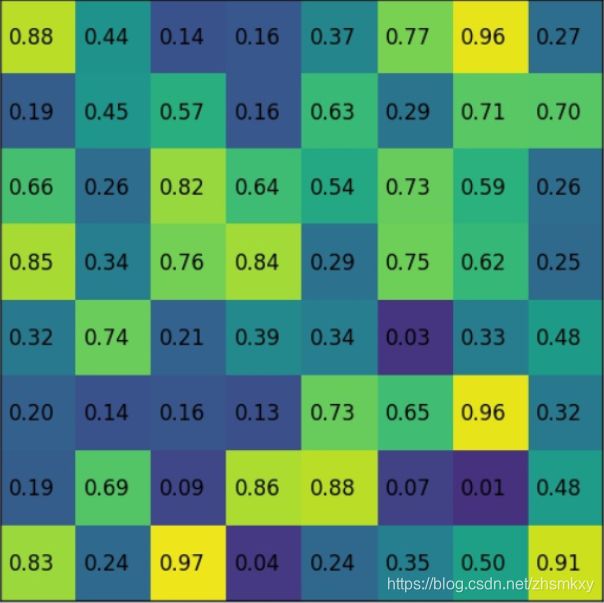
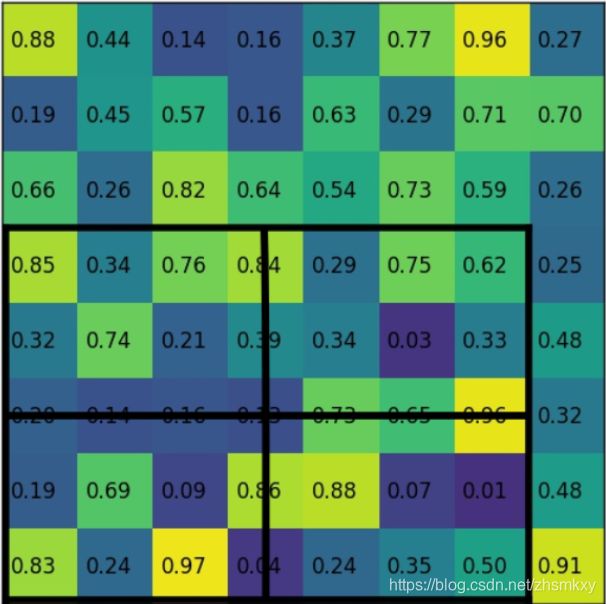



这其中有必要对双线性插值部分到底是如何做的展开进一步说明。

网络结构
整个网络的机构包含两个部分,一部分是backbone用来提取特征,另一部分是head用来对每一个ROI进行分类,边框回归和预测。论文中提出了两种架构,左边的Faster R-CNN/ResNet和右边的Faster R-CNN/FPN,如下图所示。
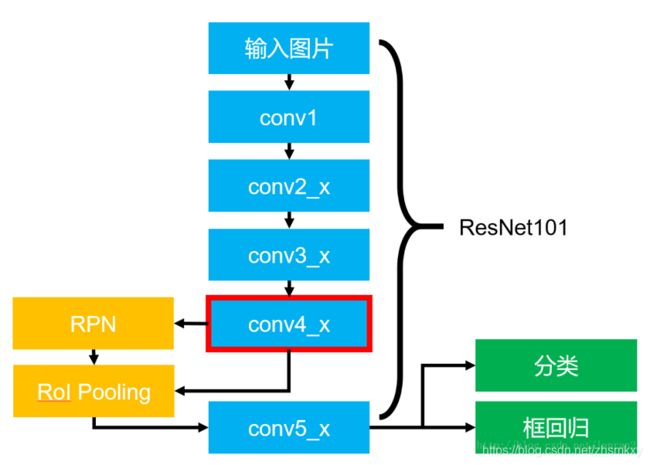
对于左边的架构,backbone使用的是预训练好的ResNet,使用ResNet导数第4层的网络。输入的ROI首先获得7×7×1024的ROI feature,然后将其升维到2048个通道,然后有两个分支,上面的分支负责分类和回归,下面的分支负责生成对应的mask。由于前面进行了多次卷积核池化,减小了对应的分辨率,mask分支开始利用反卷积进行分辨率的提升,同时减少通道个数,变成14×14,最后输出了14×14×80的mask模板
右边使用的backbone的FPN网络。
FPN网络
特征金字塔网络FPN是2017年提出的一种网络,FPN主要解决的是物体中的多尺度问题,通过网络连接,在进本不增加原有模型计算量的情况下,大幅度提升了小物体的检测的性能。
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。虽然有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而FPN网络却不一样。
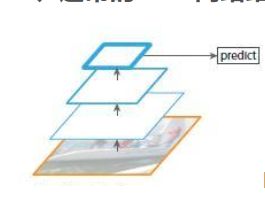
上图网络是自底向上卷积,然后使用最后一层特征图进行预测,像SPP-Net,之前的fast,faster-RCNN都是这样仅仅采用网络最后一层的特征。
以VGG16为例子,假如feat_stride=16,表示若原图大小是1000600,经过网络后最深一层的特征图大小是6040,可理解为特征图上一像素点映射原图中一个1616的区域;那原图中有一个小于1616大小的小物体,是不是就会被忽略掉,检测不到了呢?
1. 图片金字塔生成特征金字塔
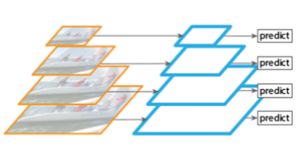
由于单层检测可能会丢失细节特征,就会想到利用图像的各个尺度进行训练和测试,将图像做成不同的scale,利用不同的scale的图像生成不同的scale特征。但这种方法我们说过了,每一张图片过卷积层十分耗时,而且一张图片的不同scale,更不用想了,不符合实际应用。
2. 多尺度特征融合的方式
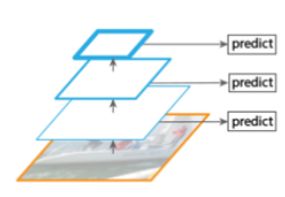
像SSD就是采用多尺度特征融合的方式,没有上采样过程,即从网络的不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。
3. FPN(Feature Pyramid Networks)
4. top-down pyramid w/o lateral
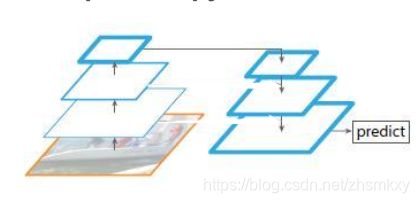
上图该网络有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。实验发现这样效果比图1的网络效果更差。
5. only finest nevel
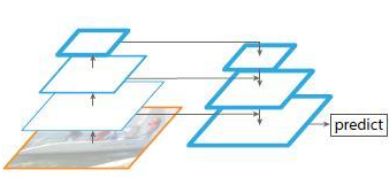
上图带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测,跟FPN的区别是它仅在最后一层预测。
FPN网络详解
算法大致结构如下:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。

自下而上:
自下而上的过程就是神经网络普通的前向传播过程,特征图经过卷积核计算,通常会越变越小。具体来说,对resnet,我们使用每个阶段的最后一个residual block输出的特征激活输出,把conv2,conv3,conv4和conv5的输出表示为{C2,C3,C4,C5},它们相对于输入图像具有{4,8,16,32}的步长,由于conv1庞大的内存占用,不会用conv1的输出纳入金字塔。
自上而下
自上而下是把更抽象,语义更强的高层特征图进行上采样,然后靠横向连接把上采样的结果和自下而上生成的相同大小的feature map进行融合,横向链接的两层特征在空间尺寸相同,这样可以利用底层定位细节信息。将低分辨率的特征图做2倍上采样(使用最近邻上采样)。然后通过按元素相加,将上采样映射与相应的自底而上映射合并。
横向连接
采用1×1的卷积核进行连接。
损失函数
网络使用的损失函数分为分类误差+检测误差+分割误差
L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask
分割误差和检测误差在前面已经讲过了,分割为新的东西,对于每一个ROI,mask分支定义一个 K × m 2 K\times m^{2} K×m2个不同的分类对于每一个$ m^{2}$的区域,也就是说我们手动设定最后一层卷积核的通道数和它的类别数相等,而且已经设定了哪一个通道和哪一个类别相对应。这里再详细说明一下,我们事先知道了ground truth的掩码,下图左边的并不是ground truth的掩码,而是ROI经过mask分支生成的特征图(形状已经大致像一个气球了),我们用这个特征图和ground truth的掩码图做损失函数。具体操作就是逐像素的进行average binary cross entropy。先让像素点经过sigmoid函数映射到(0,1)的区间,然后做average binary cross entropy。公式如下:
L m a s k = − 1 m × m ∑ 1 m 2 y i l o g ( s i g m o i d ( y i ^ ) ) + ( 1 − y i ) l o g ( 1 − s i g m o i d ( y i ^ ) ) L_{mask}=-\frac{1}{m\times m}\sum_{1}^{m^{2}}y_{i}log(sigmoid(\hat{y_{i}}))+(1-y_{i})log(1-sigmoid(\hat{y_{i}})) Lmask=−m×m1∑1m2yilog(sigmoid(yi^))+(1−yi)log(1−sigmoid(yi^))

参考博客
实例分割–Mask RCNN详解(ROI Align / Loss Fun)
https://blog.csdn.net/qinghuaci666/article/details/80900882?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.nonecase
详解 Mask-RCNN 中的 “RoIAlign” 作用 / 双线性插值的方法
https://blog.csdn.net/qq_42902997/article/details/105087407
FPN网络详解
https://blog.csdn.net/kk123k/article/details/86566954
(Mask RCNN)——论文详解(真的很详细)
https://blog.csdn.net/wangdongwei0/article/details/83110305?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
【论文翻译】Mask R-CNN
https://blog.csdn.net/xiaqunfeng123/article/details/78716136
Mask RCNN 实战(一)--代码详细解析
https://blog.csdn.net/ghw15221836342/article/details/80084984
Mask R-CNN原理详细解读
https://blog.csdn.net/qq_37392244/article/details/88844681?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.nonecase
Feature Pyramid Networks for Object Detection 总结
https://blog.csdn.net/xiamentingtao/article/details/78598027