Anaconda 安装第三方库失败的解决办法
本地环境:
Windows 10,Anaconda Python 3.6.3
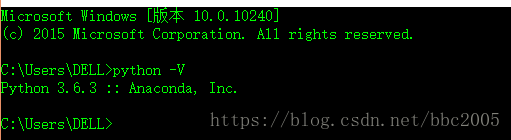
一般,对于 Python中安装第三方库:若Python是通过Anaconda安装的最好用conda命令来安装第三方库;能用conda用conda,不能用conda则用pip命令;有一些库不论conda和pip都无法直接安装,只能下载whl文件再安装了。
今天安装Scrapy遇到的情况:
1:异常现象
1:Windows命令行通过pip和conda安装:
Microsoft Windows [版本 10.0.10240]
(c) 2015 Microsoft Corporation. All rights reserved.
C:\Users\DELL>pip list
DEPRECATION: The default format will switch to columns in the future. You can use --format=(legacy|columns) (or define a format=(legacy|columns) in your pip.conf under the [list] section) to disable this warning.
alabaster (0.7.10)
anaconda-client (1.6.5)
anaconda-navigator (1.6.9)
anaconda-project (0.8.0)
asn1crypto (0.22.0)
astroid (1.5.3)
astropy (2.0.2)
babel (2.5.0)
backports.shutil-get-terminal-size (1.0.0)
beautifulsoup4 (4.6.0)
bitarray (0.8.1)
bkcharts (0.2)
blaze (0.11.3)
bleach (1.5.0)
bokeh (0.12.10)
boto (2.48.0)
Bottleneck (1.2.1)
CacheControl (0.12.3)
certifi (2017.7.27.1)
cffi (1.10.0)
chardet (3.0.4)
click (6.7)
cloudpickle (0.4.0)
clyent (1.2.2)
colorama (0.3.9)
comtypes (1.1.2)
conda (4.3.30)
conda-build (3.0.27)
conda-verify (2.0.0)
contextlib2 (0.5.5)
cryptography (2.0.3)
cx-Freeze (5.1)
cycler (0.10.0)
Cython (0.26.1)
cytoolz (0.8.2)
dask (0.15.3)
datashape (0.5.4)
decorator (4.1.2)
defusedxml (0.5.0)
distlib (0.2.5)
distributed (1.19.1)
docutils (0.14)
entrypoints (0.2.3)
enum34 (1.1.6)
et-xmlfile (1.0.1)
fastcache (1.0.2)
filelock (2.0.12)
Flask (0.12.2)
Flask-Cors (3.0.3)
gevent (1.2.2)
glob2 (0.5)
greenlet (0.4.12)
h5py (2.7.0)
heapdict (1.0.0)
html5lib (0.9999999)
idna (2.6)
imageio (2.2.0)
imagesize (0.7.1)
ipykernel (4.6.1)
ipython (6.1.0)
ipython-genutils (0.2.0)
ipywidgets (7.0.0)
isort (4.2.15)
itsdangerous (0.24)
jdcal (1.3)
jedi (0.10.2)
Jinja2 (2.9.6)
jsonschema (2.6.0)
jupyter-client (5.1.0)
jupyter-console (5.2.0)
jupyter-core (4.3.0)
jupyterlab (0.27.0)
jupyterlab-launcher (0.4.0)
lazy-object-proxy (1.3.1)
llvmlite (0.20.0)
locket (0.2.0)
lockfile (0.12.2)
lxml (4.2.3)
Markdown (2.6.11)
MarkupSafe (1.0)
matplotlib (2.1.0)
mccabe (0.6.1)
menuinst (1.4.10)
mistune (0.7.4)
mpmath (0.19)
msgpack-python (0.4.8)
multipledispatch (0.4.9)
navigator-updater (0.1.0)
nbconvert (5.3.1)
nbformat (4.4.0)
networkx (2.0)
nltk (3.2.4)
nose (1.3.7)
notebook (5.0.0)
numba (0.35.0+10.g143f70e)
numexpr (2.6.2)
numpy (1.13.3)
numpydoc (0.7.0)
odo (0.5.1)
olefile (0.44)
openpyxl (2.4.8)
packaging (16.8)
pandas (0.20.3)
pandocfilters (1.4.2)
partd (0.3.8)
path.py (10.3.1)
pathlib2 (2.3.0)
patsy (0.4.1)
pep8 (1.7.0)
pickleshare (0.7.4)
Pillow (4.2.1)
pip (9.0.1)
pkginfo (1.4.1)
ply (3.10)
progress (1.3)
prompt-toolkit (1.0.15)
protobuf (3.5.1)
psutil (5.4.0)
py (1.4.34)
Py3AMF (0.8.7)
pycodestyle (2.3.1)
pycosat (0.6.2)
pycparser (2.18)
pycrypto (2.6.1)
pycurl (7.43.0)
pyflakes (1.6.0)
Pygments (2.2.0)
pylint (1.7.4)
pyodbc (4.0.17)
pyOpenSSL (17.2.0)
pyparsing (2.2.0)
PyPDF2 (1.26.0)
PySocks (1.6.7)
pytest (3.2.1)
python-dateutil (2.6.1)
pytz (2017.2)
PyWavelets (0.5.2)
pywin32 (221)
PyYAML (3.12)
pyzmq (16.0.2)
QtAwesome (0.4.4)
qtconsole (4.3.1)
QtPy (1.3.1)
reportlab (3.4.0)
requests (2.18.4)
rope (0.10.5)
ruamel-yaml (0.11.14)
scikit-image (0.13.0)
scikit-learn (0.19.1)
scipy (0.19.1)
seaborn (0.8)
setuptools (36.5.0.post20170921)
simplegeneric (0.8.1)
singledispatch (3.4.0.3)
six (1.11.0)
snowballstemmer (1.2.1)
sortedcollections (0.5.3)
sortedcontainers (1.5.7)
Sphinx (1.6.3)
sphinxcontrib-websupport (1.0.1)
spyder (3.2.4)
SQLAlchemy (1.1.13)
statsmodels (0.8.0)
sympy (1.1.1)
tables (3.4.2)
tblib (1.3.2)
tensorflow (1.4.0)
tensorflow-tensorboard (0.4.0rc3)
testpath (0.3.1)
tinify (1.5.1)
toolz (0.8.2)
tornado (4.5.2)
traitlets (4.3.2)
typing (3.6.2)
unicodecsv (0.14.1)
urllib3 (1.22)
wcwidth (0.1.7)
webencodings (0.5.1)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (3.0.2)
win-inet-pton (1.0.1)
win-unicode-console (0.5)
wincertstore (0.2)
wrapt (1.10.11)
xlrd (1.1.0)
XlsxWriter (1.0.2)
xlwings (0.11.4)
xlwt (1.3.0)
zict (0.1.3)
C:\Users\DELL>pip install scrapy
Collecting scrapy
Exception:
Traceback (most recent call last):
File "D:\AppData\Anaconda3\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "D:\AppData\Anaconda3\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "D:\AppData\Anaconda3\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 554, in _prepare_file
require_hashes
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_install.py", line 278, in populate_link
self.link = finder.find_requirement(self, upgrade)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 465, in find_requirement
all_candidates = self.find_all_candidates(req.name)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 423, in find_all_candidates
for page in self._get_pages(url_locations, project_name):
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 568, in _get_pages
page = self._get_page(location)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 683, in _get_page
return HTMLPage.get_page(link, session=self.session)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 811, in get_page
inst = cls(resp.content, resp.url, resp.headers)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 731, in __init__
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument 'transport_encoding'
C:\Users\DELL>conda install -c scrapinghub scrapy
Fetching package metadata ...............
Solving package specifications: .
Package plan for installation in environment D:\AppData\Anaconda3:
The following NEW packages will be INSTALLED:
appdirs: 1.4.3-py36_0
attrs: 18.1.0-py36_0
automat: 0.7.0-py36_0
constantly: 15.1.0-py36_0
cssselect: 1.0.3-py36_0
hyperlink: 18.0.0-py36_0
incremental: 17.5.0-py36he5b1da3_0
parsel: 1.4.0-py36_0
pyasn1: 0.4.3-py36_0
pyasn1-modules: 0.2.2-py36_0
pydispatcher: 2.0.5-py36_0
pytest-runner: 4.2-py36_0
queuelib: 1.5.0-py36_0
scrapy: 1.5.0-py36_0
service_identity: 17.0.0-py36_0
twisted: 18.4.0-py36hfa6e2cd_0
w3lib: 1.19.0-py36_0
zope: 1.0-py36_0
zope.interface: 4.5.0-py36hfa6e2cd_0
The following packages will be UPDATED:
anaconda: 5.0.1-py36h8316230_2 --> custom-py36h363777c_0
conda: 4.3.30-py36h7e176b0_0 --> 4.5.8-py36_0
pycosat: 0.6.2-py36hf17546d_1 --> 0.6.3-py36h413d8a4_0
Proceed ([y]/n)? y
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
C:\Users\DELL>
一般Anaconda Prompt和Windows的命令行一样的:
2:Anaconda Prompt通过pip和conda安装:
(D:\AppData\Anaconda3) C:\Users\DELL>pip install scrapy
Collecting scrapy
Exception:
Traceback (most recent call last):
File "D:\AppData\Anaconda3\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "D:\AppData\Anaconda3\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "D:\AppData\Anaconda3\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 554, in _prepare_file
require_hashes
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_install.py", line 278, in populate_link
self.link = finder.find_requirement(self, upgrade)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 465, in find_requirement
all_candidates = self.find_all_candidates(req.name)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 423, in find_all_candidates
for page in self._get_pages(url_locations, project_name):
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 568, in _get_pages
page = self._get_page(location)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 683, in _get_page
return HTMLPage.get_page(link, session=self.session)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 811, in get_page
inst = cls(resp.content, resp.url, resp.headers)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 731, in __init__
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument 'transport_encoding'
(D:\AppData\Anaconda3) C:\Users\DELL>pip install Scrapy
Collecting Scrapy
Exception:
Traceback (most recent call last):
File "D:\AppData\Anaconda3\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "D:\AppData\Anaconda3\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "D:\AppData\Anaconda3\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 554, in _prepare_file
require_hashes
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_install.py", line 278, in populate_link
self.link = finder.find_requirement(self, upgrade)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 465, in find_requirement
all_candidates = self.find_all_candidates(req.name)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 423, in find_all_candidates
for page in self._get_pages(url_locations, project_name):
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 568, in _get_pages
page = self._get_page(location)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 683, in _get_page
return HTMLPage.get_page(link, session=self.session)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 811, in get_page
inst = cls(resp.content, resp.url, resp.headers)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 731, in __init__
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument 'transport_encoding'
(D:\AppData\Anaconda3) C:\Users\DELL>conda install Scrapy
Fetching package metadata ...
CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
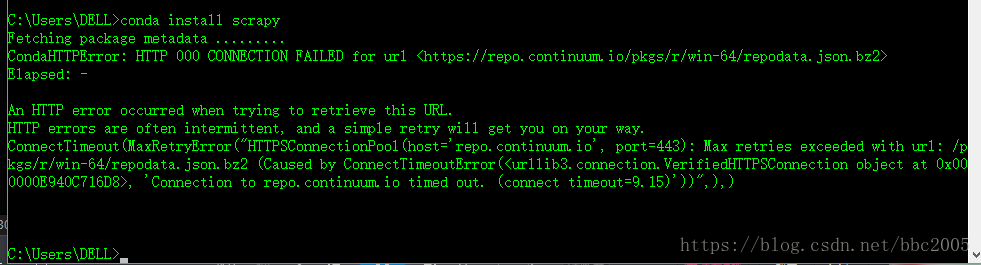
ConnectTimeout(MaxRetryError("HTTPSConnectionPool(host='repo.continuum.io', port=443): Max retries exceeded with url: /pkgs/main/win-64/repodata.json.bz2 (Caused by ConnectTimeoutError(, 'Connection to repo.continuum.io timed out. (connect timeout=9.15)'))",),)
(D:\AppData\Anaconda3) C:\Users\DELL>pip install scrapy
Collecting scrapy
Exception:
Traceback (most recent call last):
File "D:\AppData\Anaconda3\lib\site-packages\pip\basecommand.py", line 215, in main
status = self.run(options, args)
File "D:\AppData\Anaconda3\lib\site-packages\pip\commands\install.py", line 335, in run
wb.build(autobuilding=True)
File "D:\AppData\Anaconda3\lib\site-packages\pip\wheel.py", line 749, in build
self.requirement_set.prepare_files(self.finder)
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 380, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_set.py", line 554, in _prepare_file
require_hashes
File "D:\AppData\Anaconda3\lib\site-packages\pip\req\req_install.py", line 278, in populate_link
self.link = finder.find_requirement(self, upgrade)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 465, in find_requirement
all_candidates = self.find_all_candidates(req.name)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 423, in find_all_candidates
for page in self._get_pages(url_locations, project_name):
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 568, in _get_pages
page = self._get_page(location)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 683, in _get_page
return HTMLPage.get_page(link, session=self.session)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 811, in get_page
inst = cls(resp.content, resp.url, resp.headers)
File "D:\AppData\Anaconda3\lib\site-packages\pip\index.py", line 731, in __init__
namespaceHTMLElements=False,
TypeError: parse() got an unexpected keyword argument 'transport_encoding'
(D:\AppData\Anaconda3) C:\Users\DELL>conda install scrapy
Fetching package metadata .............
Solving package specifications: .
Package plan for installation in environment D:\AppData\Anaconda3:
The following NEW packages will be INSTALLED:
appdirs: 1.4.3-py36_0
attrs: 18.1.0-py36_0
automat: 0.7.0-py36_0
constantly: 15.1.0-py36_0
cssselect: 1.0.3-py36_0
hyperlink: 18.0.0-py36_0
incremental: 17.5.0-py36he5b1da3_0
parsel: 1.4.0-py36_0
pyasn1: 0.4.3-py36_0
pyasn1-modules: 0.2.2-py36_0
pydispatcher: 2.0.5-py36_0
pytest-runner: 4.2-py36_0
queuelib: 1.5.0-py36_0
scrapy: 1.5.0-py36_0
service_identity: 17.0.0-py36_0
twisted: 18.4.0-py36hfa6e2cd_0
w3lib: 1.19.0-py36_0
zope: 1.0-py36_0
zope.interface: 4.5.0-py36hfa6e2cd_0
The following packages will be UPDATED:
anaconda: 5.0.1-py36h8316230_2 --> custom-py36h363777c_0
conda: 4.3.30-py36h7e176b0_0 --> 4.5.8-py36_0
pycosat: 0.6.2-py36hf17546d_1 --> 0.6.3-py36h413d8a4_0
Proceed ([y]/n)? y
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
CondaError: CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
(D:\AppData\Anaconda3) C:\Users\DELL> 3:Anaconda Navigator安装:
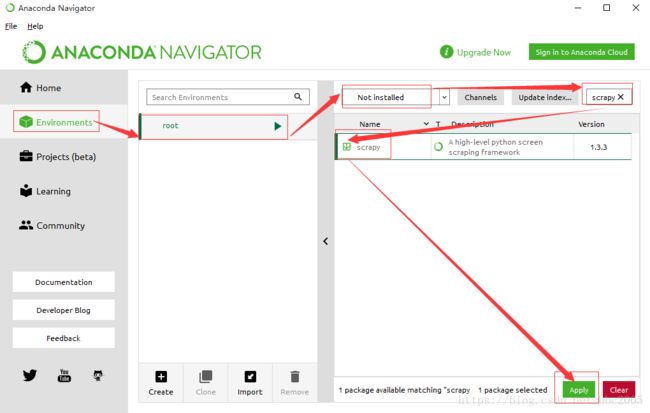
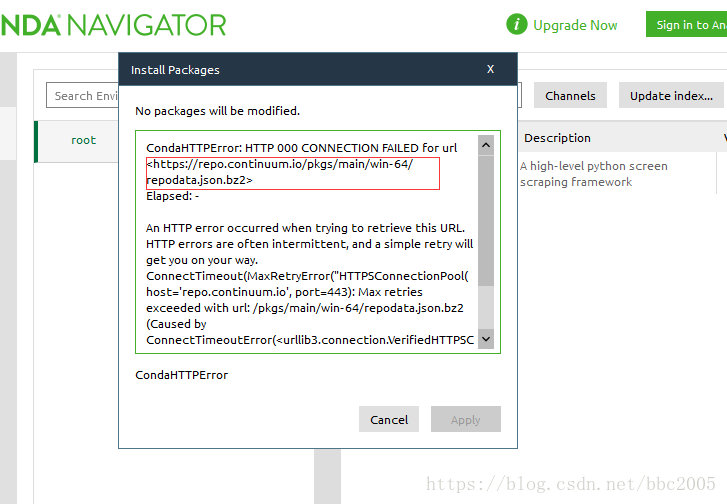
2:异常原因
由以上错误提示知都是网络问题,导致安装失败。Anaconda默认的镜像源大部分都在国外,国内很多网络环境下,访问不稳定,下载速率慢,有时根本连接不上,另外国内也有镜像源,可以修改Anaconda的镜像源为国内的。
3:解决办法
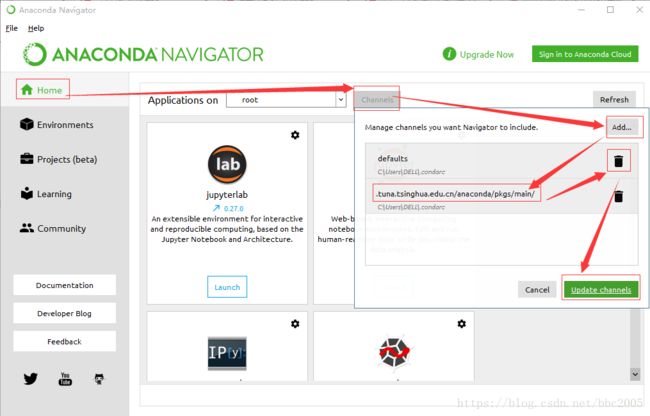
1:在Anaconda Navigator设置:
添加一个清华的镜像https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/,删除默认的:
在安装,提示这个镜像源没有要安装的第三方库,并提示了两个镜像源:
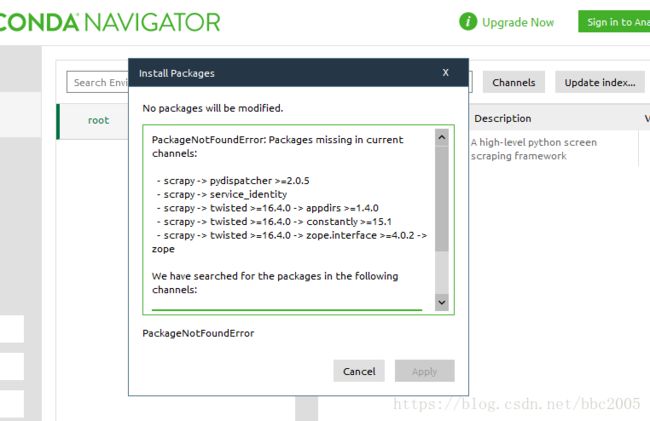
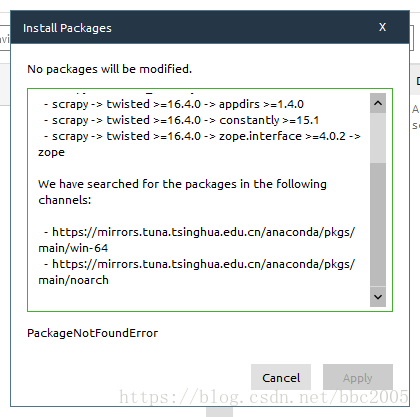
添加这两个镜像源
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/noarch
时校验失败,找了一个中科大的镜像https://mirrors.ustc.edu.cn/anaconda/pkgs/free/可以用并安装成功。
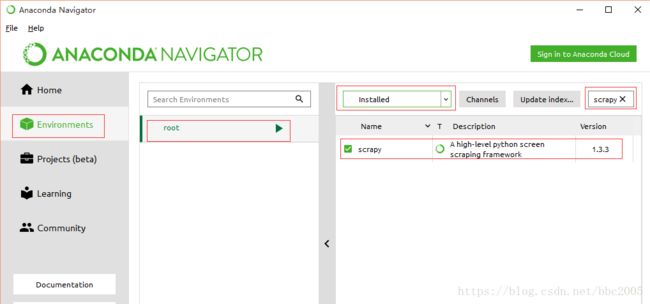
命令行conda list:
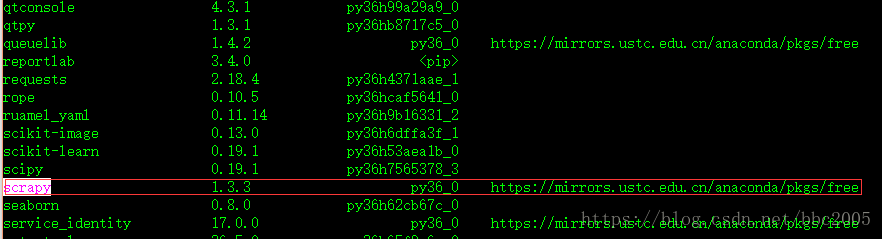
命令行pip list:

2:通过conda config 命令配置:
为了演示先把.condarc文件的配置恢复成默认的:
channels:
- defaults
ssl_verify: true.condarc以点开头,一般表示 conda 应用程序的配置文件,在用户的家目录(windows:C:\\users\\username\\,linux:/home/username/)。但对于.condarc配置文件,是一种可选的(optional)运行期配置文件,其默认情况下是不存在的,但当用户第一次运行 conda config命令时,将会在用户的家目录创建该文件。
在命令行或Anaconda Prompt中,输入conda info,查看默认配置的镜像源 (channel URLs对应的)和配置文件路径(config file):
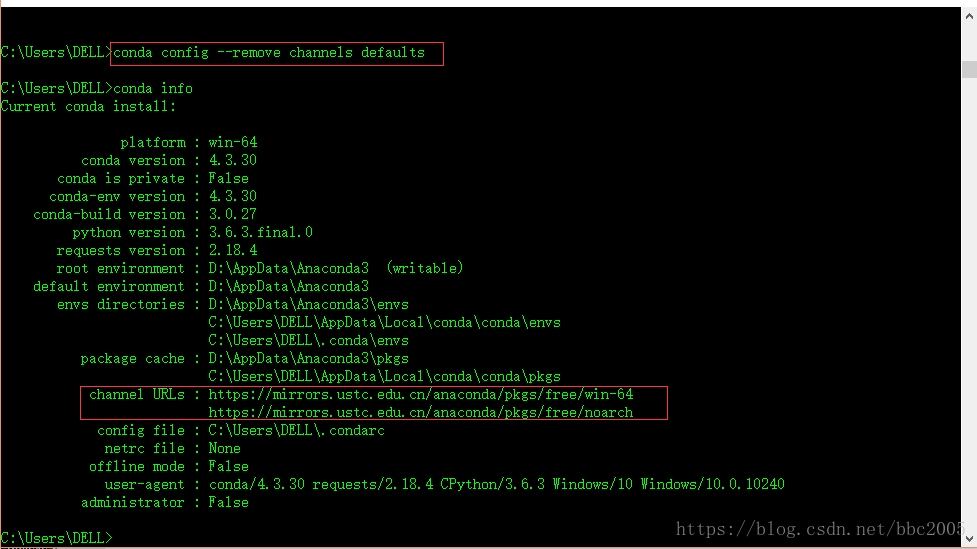
C:\Users\DELL>conda info
Current conda install:
platform : win-64
conda version : 4.3.30
conda is private : False
conda-env version : 4.3.30
conda-build version : 3.0.27
python version : 3.6.3.final.0
requests version : 2.18.4
root environment : D:\AppData\Anaconda3 (writable)
default environment : D:\AppData\Anaconda3
envs directories : D:\AppData\Anaconda3\envs
C:\Users\DELL\AppData\Local\conda\conda\envs
C:\Users\DELL\.conda\envs
package cache : D:\AppData\Anaconda3\pkgs
C:\Users\DELL\AppData\Local\conda\conda\pkgs
channel URLs : https://repo.continuum.io/pkgs/main/win-64
https://repo.continuum.io/pkgs/main/noarch
https://repo.continuum.io/pkgs/free/win-64
https://repo.continuum.io/pkgs/free/noarch
https://repo.continuum.io/pkgs/r/win-64
https://repo.continuum.io/pkgs/r/noarch
https://repo.continuum.io/pkgs/pro/win-64
https://repo.continuum.io/pkgs/pro/noarch
https://repo.continuum.io/pkgs/msys2/win-64
https://repo.continuum.io/pkgs/msys2/noarch
config file : C:\Users\DELL\.condarc
netrc file : None
offline mode : False
user-agent : conda/4.3.30 requests/2.18.4 CPython/3.6.3 Windows/10 Windows/10.0.10240
administrator : False
C:\Users\DELL>
直接配置中科大的镜像https://mirrors.ustc.edu.cn/anaconda/pkgs/free:
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes再查看配置的镜像源:
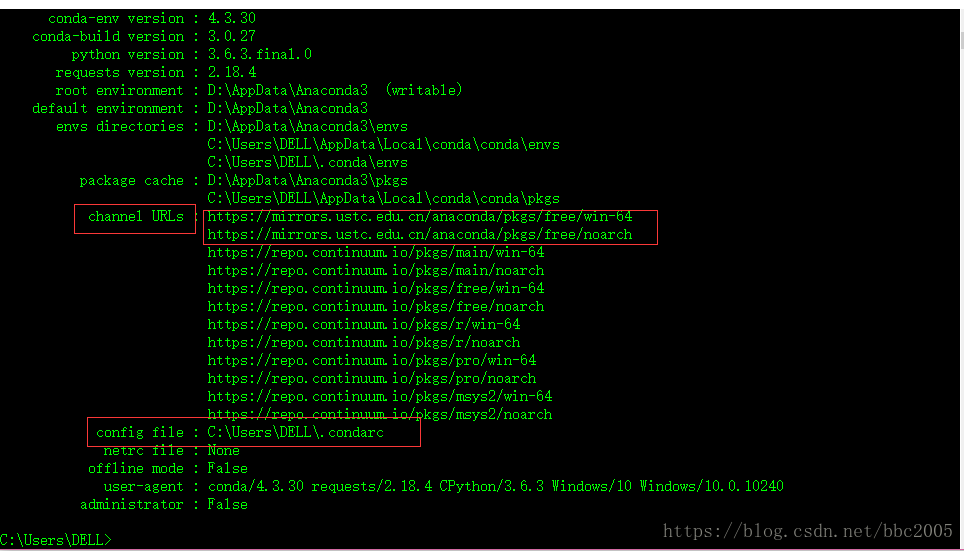
下载安装,还是失败:
删除默认的镜像源后,重试成功:
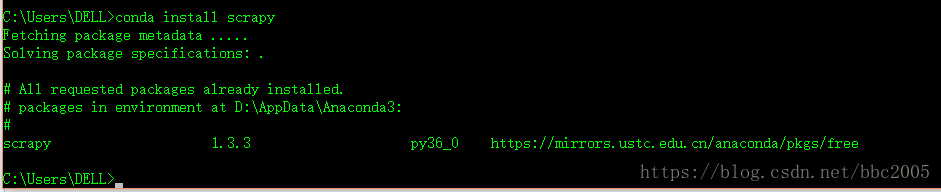
以上方法二选一。