Python爬虫框架之Scrapy详解
scrapy爬虫安装:
- 首先,安装Python,pip,然后使用pip安装lxml和scrapy,这样就可以新建scrapy项目了。
- 然后,在命令行使用scrapy startproject xxx命令新建一个名为xxx的scrapy爬虫项目。
scrapy爬虫内部处理流程:
我们在使用scrapy写爬虫,一般要继承scrapy.spiders.Spider类,在这个类中,有个数组类型的变量start_urls,start_urls定义了爬虫开始爬取的那些链接,所以我们会把需要先爬取的页面链接放入start_urls中。然后,scrapy.spiders.Spider会通过调用start_requests()方法,以start_urls中的所有链接的每个链接生成对应的Request对象,该对象设置了默认的回调函数parse()方法。然后,scrapy主流程会用该Request对象发HTTP请求并且获取到相应内容,封装成Response对象,然后这个Response对象会被作为参数传递给Request设置的回调函数,也就是parse()方法。这里要注意,start_requests()方法是Spider提供的,本来就实现好的,一般情况下不需要自己去实现start_requests()方法。
在scrapy封装Response后,会把该Response传递给parse()方法处理。scrapy.spiders.Spider中的parse()方法就是默认提供给用户来实现的。在这个parse方法中,我们可以通过传进来的Response对象,使用scrapy的选择器和xpath()或者css()提取出我们想要的内容,封装成我们在pipeline中定义的Item对象返回。或者,如果有下一页的数据或者其他页面的数据,在parse()方法中解析出来这样的链接之后,我们也可以用这些链接生成Request对象返回。parse()方法可以返回一个Item对象、dict、Request对象,或者是一个包括这三个者的可迭代对象。或者我们也可以在生成Request的时候指定自定义的回调函数,不使用parse()方法。
如果parse()方法或回调函数返回的是一个Request对象,那么scrapy.spiders.Spider会将这个Request对象交给scrapy主流程处理,发出HTTP请求,获取响应,之后又生成Response对象, 传递给Request中设置的回调函数进行处理。也就是不断地执行第二步和第三步。
如果parse()方法或回调函数返回的是Item对象,那scrapy.spiders.Spider会把这个返回的Item传递给scrapy中的Item Pipeline处理。所以,在实现爬虫的时候,一般都要定义一个ItemPipeline来处理我们在回调函数中返回的Item。在pipeline中,我们可以把Item输出,持久化到数据库或者文件中。
scrapy.spiders.Spider :
scrapy.spiders.Spider是scrapy中最简单的spider。一般要爬取的操作都定义在Spider类中。重写Spider的parse方法来处理获取到的网页内容。
Spider主要属性和方法如下:
name:爬虫的名字,必选参数,scrapy crawl命令将查找这个name来确定要执行的爬虫是哪一个。
allowed_domains:列表,可选参数,定义了允许爬取的网页的域名列表,不在此列表内的域名的链接不会被爬取。
start_urls:列表,包含了scrapy开始爬取的所有链接,基本等于scrapy爬取的网页的入口页面。
custom_settings:dict,可选,定制化参数设置,在爬虫爬取的过程中,scrapy会使用这个参数中的内容替换scrapy运行时的配置,一般不需要设置该参数。
logger:日志记录对象。
from_crawler():scrapy用于创建爬虫的方法。这个方法会自动设置crawler和settings。
settings:爬虫运行的配置,是Settings的实例。
crawler:在类初始化后由from_crawler设置,链接到绑定的spider的Crawler类。
start_requests():scrapy开始爬取并且用于创建Request的方法。在爬虫开始运行后,scrapy会调用start_requests(),其内部会调用make_requests_from_url()方法从start_urls列表中对每一个链接生成Request。我们只需要把要开始爬取的链接放入start_urls中即可,也可以不定义start_urls,重新实现start_requests,生成自定义的Request对象,如FormRequest,然后获取到Response后传递给自定义的回调函数处理。start_requests在整个爬虫运行过程中只会执行一次。
make_requests_from_url(url):这个方法接收一个链接,返回一个Request对象。
parse(response):scrapy默认的回调函数。当通过Request获取到Response后,如果Request没有指定自定义的回调函数,那么会使用该函数作为回调函数。如果没有自定义start_requests()方法,那么必须实现这个函数,并且在里面定义网页数据的提取操作。
log(message[, level, component]):与logger类似,用于日志记录。
closed(reason):爬虫关闭时调用的方法。官方使用示例:
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
def start_requests(self):
yield scrapy.Request('http://www.example.com/1.html', self.parse)
yield scrapy.Request('http://www.example.com/2.html', self.parse)
yield scrapy.Request('http://www.example.com/3.html', self.parse)
def parse(self, response):
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)scrapy.spiders.CrawlSpider:
CrawlSpider继承自Spider,是一个适用于爬取很规则的网站的爬虫。其定义了提取链接的规则,能够很方便的从Response中提取到想要的链接并且继续跟进这些链接。
CrawlSpider主要属性如下:
rules:列表,定义了从Response提取符合要求的链接的Rule对象。
parse_start_url:CrawlSpider默认的回调函数,我们在使用CrawlSpider时,不应该覆盖parse方法,而应
该覆盖这个方法。因为CrawlSpider使用了parse函数来处理自己的逻辑,所以我们不能覆盖parse方法。其中,Rule有以下几个参数:
link_extractor:LinkExtractor对象,用于定义需要提取的链接。Link Extractors是链接提取器,一类用来从返回网页中提取符合要求的链接的对象。
callback:回调函数,当link_extractor获取到符合条件的链接时,就会使用这个参数的函数作为回调函数。注意不能使用parse作为回调函数、
follow:bool值,指定了根据link_extractor规则从response提取的链接是否需要跟进。callback为空是,follow默认为true,否则就是false。
process_links:函数或者函数名,用于过滤link_extractor提取到的链接。
process_request:函数或者函数名,用于过滤Rule中提取到的request。
其中LinkExtractor对象主要有以下几个参数:
allow:字符串或元组,满足括号中所有的正则表达式的那些值会被提取,如果为空,则全部匹配。
deny:字符串或元组,满足括号中所有的正则表达式的那些值一定不会被提取。优先于allow参数。
allow_domains:字符串或元组,会被提取的链接的域名列表。
deny_domains:字符串或元组,一定不会被提取链接的域名列表。
restrict_xpaths:字符串或元组,xpath表达式列表,使用xpath语法和allow参数一起提取链接。
restrict_css:字符串或元素,css表达式列表,使用css语法和allow参数一起提取链接。最常用的LinkExtractor:LxmlLinkExtractor,使用了lxml中的HTMLParser来提取HTML内容。
class LxmlLinkExtractor(FilteringLinkExtractor):
def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),
tags=('a', 'area'), attrs=('href',), canonicalize=True,
unique=True, process_value=None, deny_extensions=None, restrict_css=()):
tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))
tag_func = lambda x: x in tags
attr_func = lambda x: x in attrs
lx = LxmlParserLinkExtractor(tag=tag_func, attr=attr_func,
unique=unique, process=process_value)
super(LxmlLinkExtractor, self).__init__(lx, allow=allow, deny=deny,
allow_domains=allow_domains, deny_domains=deny_domains,
restrict_xpaths=restrict_xpaths, restrict_css=restrict_css,
canonicalize=canonicalize, deny_extensions=deny_extensions)
def extract_links(self, response):
base_url = get_base_url(response)
if self.restrict_xpaths:
docs = [subdoc
for x in self.restrict_xpaths
for subdoc in response.xpath(x)]
else:
docs = [response.selector]
all_links = []
for doc in docs:
links = self._extract_links(doc, response.url, response.encoding, base_url)
all_links.extend(self._process_links(links))
return unique_list(all_links)CrawlSpider使用示例:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return itemSpider.start_requests()方法:
由上面得知,scrapy.spiders.Spider会通过调用start_requests()方法,以start_urls中的所有链接的每个链接生成对应的Request对象,该对象设置了默认的回调函数parse()方法。start_requests()方法的默认实现如下:
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)我们如果要自定义先爬取的页面时,或者要自己定义先生成的Request时,或者某些需要网站需要登录才能访问时,我们就会自己来实现start_request()方法,我们在实现该方法的时候,一般会参考它的默认实现,然后把start_requests()方法实现为一个包含yield的生成器。我们把想要先爬取的链接全部存放在start_urls列表中,然后对于这个列表中的每一个url来说,start_requests()方法只会调用一次,然后就会生成Request,获取Response,将Response传递给Request中的回调函数处理。但这不是说在整个爬虫项目的爬取过程中start_request()方法只会调用一次,而是说,对于start_urls中的每一个链接,start_requests()方法只会调用一次)。
所以如果我们实现了start_requests()方法,那么我们会把它实现为生成器的形式,即,在start_requests()实现中,使用yield中通过make_requests_from_url(url)方法产生默认的Request对象或者我们自定义的Request对象。如,
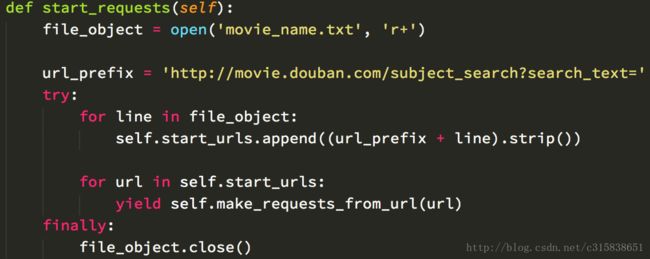
start_requests()方法默认会取start_urls中所有的链接来生成Request对象。既然我们可以自定义实现start_requests()方法,我们在start_requests()中也可以不使用start_urls,使用我们自定义的url生成Request就行,同时,我们还能给Request随意指定我们想要的回调函数。
Request构造方法如下,可以看到,必备的参数只有url,其他都是可选参数,如,
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None):对于需要登录或者需要验证cookie才能访问的网页,我们也可以使用scrapy来模拟登录,获取到cookie。这个时候,就不要使用默认的Request了,而是用FormRequest。从名字能够看出,FormRequest天生就是为了在请求中模拟网页上的表单而存在的。
FormRequest继承了Request类,FormRequest只比Request多了一个候选参数formdata,其他参数和Request一样。所以我们在创建FormRequest时,可以设置formdata参数来模拟出表单数据。
创建FormRequest的方法如下:
classmethod from_response(response[, formname=None, formnumber=0, formdata=None, formxpath=None, clickdata=None, dont_click=False, ...])
#参数解释如下:
#response:Response对象,一般表示想要被提取出表单信息的那个Response对象。即,如果有页面需要登录,那么这个response就代表了获取这个登录页面的那个Request返回的Response。
#formname:字符串,可选参数,如果设置了formname参数,则FormRequest中form表单的name属性值会设置成这个formname参数的值。
#formxpath:字符串,可选参数,这个参数表示在response表示的那个页面中,定位到第一个form表单的xpath表达式。
#formnumber:数字,可选参数,要提交的form表单的索引位置。如果response表示的那个页面中,包含多个form表单,那么formnumber参数就表示我们要使用的是里面的第几个form表单。默认值是0,表示使用网页中的第一个form表单。
#formdata:dict对象,可选参数,表示我们要覆盖的form表单的值,我们也可以在这里面新增form表单域。
#clickdata:dict对象,可选参数,查找控制点击的属性如()。默认使用web表单第一个可以点击元素。
#dont_click:bool值,可选参数, 假如这个web表单使用js控制,输入完自动提交,不需要点击,那么设置为false。这是FormRequest类的一个静态方法。
scrapy官方给出的FormRequest使用示例如下:
import scrapy
"""
Example to use FormRequest
"""
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': 'john', 'password': 'secret'},
callback=self.after_login
)
def after_login(self, response):
# check login succeed before going on
if "authentication failed" in response.body:
self.log("Login failed", level=scrapy.log.ERROR)
return
# continue scraping with authenticated session...另外一个FormRequest模拟登录的示例:
import scrapy
"""
Example to use FormRequest
"""
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def start_requests(self):
return Request("https://www.zhihu.com/login", callback = self.login)
#FormRequeset
def login(self, response):
xsrf = response.xpath('//input[@name="_xsrf"]/@value').extract()[0]
return FormRequest.from_response(response,
formdata = {
'_xsrf': xsrf,
'email': 'xxx',
'password': 'xxx'
},
callback = self.after_login
)喜欢的可以关注微信公众号:

参考
- http://www.jianshu.com/p/f36460267ac2
- 我自己的头条号:Python爬虫框架之Scrapy详解