《introduction to information retrieval》信息检索学习笔记1 布尔检索
第1章 布尔检索
- 信息检索的定义:信息检索(IR)是从大型集合(通常存储在计算机上)中寻找满足信息需求的非结构化性质(通常是文本)的材料(通常是文档)。
1.1一个信息检索的例子
问题描述:确定莎士比亚的作品集中,哪些戏剧包含了词汇Brutus和Caesar而不包含Calpumia。
1.解决办法
(1)最简单的文档检索形式:计算机通过文档进行线性扫描(Unix/Linux中文本扫描grep)
缺点:线性扫描的时间复杂度与文档集大小成正比,不适合大规模文本检索
无法满足以下需求:
1.快速处理大型文档集合
2.更灵活的匹配操作
3.检索结果排序
(2)提前建立索引文档:避免对每个查询进行线性扫描,以词项(term)为横坐标,文档(document)为纵坐标,根据文档中是否出现该词汇建立二进制词汇-文本关联矩阵。

图1.1 词汇-文档关联矩阵,当d列包含t行单词时M(t,d)为1,否则为0
针对本问题,取词汇Brutus和Caesar及Calpumia的行向量做运算(Brutus AND Caesar AND NOT Calpumia),得出问题答案: Antony and Cleopatra和Hamlet.
110100 and 110111 and 101111 = 100100
2.相关概念
- 布尔检索模型(Boolean retrieval model):信息检索的一个模型,布尔检索模型可以提出以布尔表达式的形式表示(结合逻辑运算符and,or,not)的任何查询。该模型将每个文档看作是一组单词。
- 正确率(Precision):评估一个IR系统的有效性的关键统计信息,返回的结果中有多少与信息需求相关.
- 召回率(recall):评估一个IR系统的有效性的关键统计信息,在收集的相关文档中,有多少是由系统返回的.
3.倒排索引(inverted index)
考虑500K*1M的词项-文档关联矩阵:矩阵规模超出计算机内存而难以存储,观察矩阵可以发现其为稀疏矩阵,那么一个更好的方式为只记录1的位置。
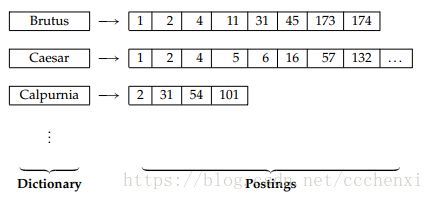
图1.2 倒排索引的两部分,倒排记录表(postings)以文件ID排序
- 词典(Dictionary):存储词项,并有一个指向每个词项的倒排记录表的指针,通常还存储其他的摘要信息,例如,每个词项的文档频率等
- 倒排记录表(Postings):存储词项出现的文档列表,并可能存储其他信息,如词项频率(每个文档中每个词项的频率)或每个文档中词项的位置等。
(概念辨析:√倒排记录(posting):词项对应的list中的每一个元素;√倒排表(posting list/inverted list):一个词项对应的整个list;√倒排记录表(Postings):所有词项的倒排表一起构成)
1.2建立倒排索引
1.主要步骤:
(1)收集被索引的文档
(2)标记文本,将每个文档转换为词条(token)
(3)进行语言预处理,生成标准化词条:
(4)通过创建一个倒排索引来索引每一项的文档,包括一个词典和一个倒排记录表。(词典通常保存在内存中,倒排记录表通常保存在磁盘上)
√对每个词项t, 记录所有包含t的文档,建立词条序列<词条,docID>二元组
√对词项、文档排序。对词项按字母排序,对倒排记录表按docID排序
√合并相同词项,并记录文档频率doc.freq(记录所有包含词项t的文档数目)
2. For example:
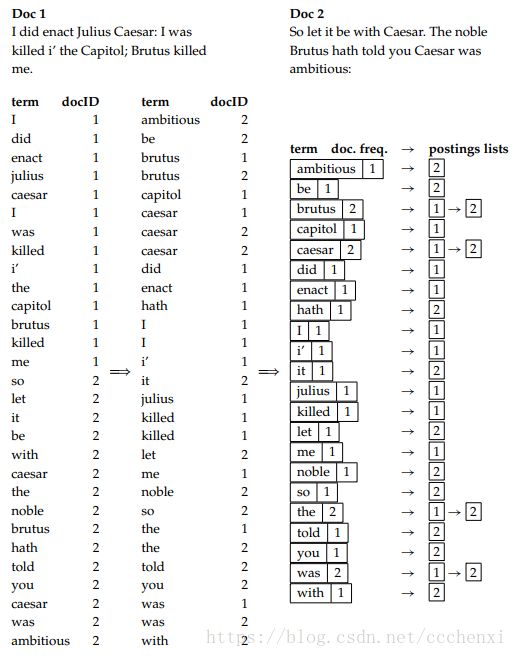
图1.3 通过排序和分组构建索引
1.3 处理布尔查询
1.简单的连接查询:Brutus And Calpurnia
建立Brutus 和 Calpurnia的倒排索引,进行如下操作:
(1)在词典里找到Brutus
(2)检索其倒排记录表
(3)在词典里找到Calpurnia
(4)检索其倒排记录表
(5)合并倒排记录表(合并倒排记录表能够快速找到包含两个词项的文档)

图1.4 合并Brutus和Calpurnia倒排记录表
√合并算法:将指针保持在两个列表中,同时遍历两列表,每一步中比较两个指针指向的检验结果。如果相同则将这个检验放在结果列表中,并同时推进两个指针;否则将指针指向较小的docID。
√复杂度:如果列表的长度是x和y,那么交集就是O(x+y)操作。常数时间复杂度,但在实践中,这个常数是巨大的。要使用这种算法,关键是要按全局统一标准排序列表。

图1.5 两个倒排记录表p1和p2的合并算法
2.扩展交集操作处理更复杂的查询:(Brutus or Caesar) and not Calpurnia
3.查询优化:选择如何组织查询的处理过程,使系统需要完成最少工作。考虑t个词项和的查询,例如:Brutus and Caesar and Calpurnia
√分析:将t个词项中的所有项的倒排记录表进行与运算。标准的启发式算法是根据词项的文档频率递增方向处理,如果从两个最小的倒排记录表开始合并,那么所有的中间结果都不应该比最小的倒排记录表大,因此可能会做最少的总工作。
√调整:在词典中保持词项的频率的第一个调整,允许在访问任何倒排记录表之前基于内存中的数据做出这个排序决定。执行以下查询:
(Calpurnia and Brutus) and Caesar
4.对更一般的查询进行优化
例如:(madding or crowd) and (ignoble or strife) and (killed or slain)
((范式存在定理)任一命题公式都存在着与之等值的析取范式和合取范式,即任何布尔查询逻辑表达式都能转换为合取范式)
√处理步骤:
(1)获得每个词项的doc.freq
(2)通过将词项的doc.freq相加,保守估计每个OR表达式对应的倒排记录表的大小
(3)将每个OR表达式从小到大依次处理
√中间结果列表替换:
对于任意的布尔查询,必须对复杂表达式中中间表达式的答案进行评估和临时存储。在查询是纯连接的情况下,比起将合并倒排记录表作为一个有两个输入和一个输出的函数,更高效的是对每个检索的倒排记录表以当前内存中的中间结果取交集,通过加载最少频率词项的倒排记录表初始化中间结果。算法如图:

图1.6 返回包含输入词项的文档集的连接查询算法
(1)交集运算是不对称的:中间结果列表在内存中,而与之交叉的列表正在从磁盘读取。中间结果列表总是至少和其他列表一样短,而且在许多情况下,它的数量级要短一些。
(2)时间复杂度:当列表长度的差异非常大时,使用替换技术是很有效果的。在中间结果列表中,可以通过破坏性修改或标记无效项来计算交集。或者交集可以作为中间结果列表中每个倒排记录表中的一个二进制搜索序列。另一种可能是将长倒排记录表存储为哈希表,可以在常量时间内计算中间结果项。
(3)这种替代技术很难与排序列表压缩相结合。当查询的两个词项都很常见时,标准的倒排记录表的交集操作仍然必要。
1.4 扩展的布尔模型与排名检索
-
排名检索模型:如向量空间模型,主要为自由文本查询,只要输入一个或多个单词而非精确的语言与运营商建立查询表达式,由系统决定哪些文档最满足查询。
-
扩展的布尔检索模型:系统通过合并额外的操作符来实现,例如,词项接近操作符。
-
近距离操作符:一种指定操作符查询中的两个词项必须在文档中彼此接近的方法,通过限制插入词的允许数量或引用一个句子或段落等结构单元来衡量亲密度。
Eg. 商业布尔查询:Westlaw
语法: 空格 - 分割 ;& - AND ; /s,/p和/k - 相同句子、相同段落或k个单词中的匹配 ; “” - 字符串 ; ! - 通配符查询(如liab!表示匹配所有以liab开头的单词) ; work-site 匹配worksite、work site、worksite;
√布尔查询优缺点:
优点:精确,文档要么匹配查询,要么不匹配。这为用户提供了更大的控制和对所检索到的内容的透明性。
缺点:使用和操作符往往会产生高精度但低的回忆搜索,而使用或操作符则提供低精度但高的回忆搜索
√对非结构化信息进行临时搜索的基本技术的产生:
更多需求:
(1)希望能更好地确定字典中的一组词项,并提供对拼写错误和用词不一致的检索
(2)希望做一些接近于微软的近距离查询。要回答这样的查询,必须增加索引以捕获文档中词项的近端。
(3)一个布尔模型只记录词项的存在或缺失,但通常希望积累证据,对那些有一个词项的文档给予更多的权重,而不是只包含一次的文档。为了做到这一点,需要在倒排记录表中使用词项频率信息(一个词项在文档中出现的次数)
(4)布尔查询只是检索一组匹配的文档,希望有一个有效的方法来订购(或排名)返回的结果。这需要有一种机制来确定文档的分数,它封装了一个文档对查询的匹配程度。