机器学习概念
“种一棵树最好的时间是十年前,其次是现在”
1 机器学习的定义及关注点
机器学习致力于研究如何通过计算的手段,利用经验来改善系统本身的性能。
经验 — 数据
计算 — 机器学习算法
有了机器学习算法,把经验数据提供给它,得到模型。
权威定义:
假设用P来评估计算机程序在某任务T上的性能,若一个程序通过经验E在任务T上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。
2 术语
样本
特征
特征值
假设(假设空间)
真值 (ground-truth)
训练样本 & 测试样本
分类 & 回归 & 聚类
有监督学习 & 无监督学习
泛化能力:关注一个学得的机器学习模型在未见过的“测试样本上的性能”。泛化性能越好,模型普适性越好。
前提条件:我们获取的训练样本只是样本空间中很少的一部分,但是我们又希望最终学得的模型在整个样本空间上都具有较好的性能,能够实现这样的目的是基于一个假设 – 独立同分布(iid),即样本空间中的所有样本都符合同样的分布且相互之间独立,这样即便只给了你很小的一部分样本做训练集,但只要你能找到内部运行的规律,你就可以对整个样本空间进行较好的建模,也就取得了具有较好泛化能力的模型。iid这个假设太强了,很多情况下由于获得的训练数据集有限,可能我们只是偏安于一隅,并没有看到这个世界的全貌。
假设空间 & 版本空间:所有可能的情况组成假设空间,比如一个西瓜分类问题,可以通过logistic regression解决,也可以通过决策树、SVM等解决,每个算法又可以有N多种参数组合,虽然这些模型有对的,有不对的,但这些假设都是有可能的,那么他们就都属于假设空间。也就是说假设要大胆。但一味的大胆就是莽夫了,我们下一步要怎样,要小心求证,怎么做,首先要从假设空间中删除掉那些和实际情况不符的假设,实际情况指什么,指的就是我们手头已经拿到的训练数据,把这些与现实不符的假设删除掉之后,剩下的都是比较可靠的假设了,这些假设组成版本空间。
归纳偏好: 机器学习算法在学习过程中对某种类型假设的偏好。任何一个机器学习算法都有其偏好。归纳偏好可以认为是学习算法自身在一个可能很庞大的版本空间中对假设进行选择的启发式或“价值观”,是一种先验信息。奥卡姆剃刀是常用的原则,即认为“如果存在多个模型和观察到的训练样本一致,选择最简单的那个”。奥卡姆剃刀不是唯一的归纳偏好原则,即便是奥卡姆剃刀中提到的“简单”,也可以有多种解释。因此在具体的算法实现中,算法的归纳偏好与问题本身是否匹配,直接决定了算法能否取得良好的性能。
天下没有免费的午餐:没有任何一个算法比另一个算法在所有任务上性能都更好,脱离实际的问题,空谈那个算法更好是没有意义的。进行算法性能比较的时候,一定要针对具体的问题进行分析。学习算法本身的归纳偏好与问题是否匹配,往往可以起到决定性的作用。
3 模型评估与选择
3.1 经验误差与过拟合
所学得的模型预测结果与真实结果之间的偏差称为误差。
关于训练数据的预测误差称为“训练误差”或“经验误差”;关于新样本的预测误差称为“泛化误差”。
最终目的是得到泛化误差小的模型。但是模型训练过程中,并不知道新样本什么样子,只能在训练样本集上发力,努力得到一个在训练样本集上误差小的模型。当然,可能会有疑问,在训练样本集上表现好就一定能在新样本上表现的好吗?后面我们会看到证明过程,在训练样本集上的误差和泛化误差之间差值很小的概率很大,也就是说一个模型训练误差小的话,其大概率在新样本上也会表现的不错。但是如果在训练样本集上表现的太好了,事出反常必有妖,那么往往在新样本集上表现的不是很好。
如果形象化的表示下上述概念的话,我们希望模型在学习过程中,能够学习到训练数据集背后的“普遍规律”,但是训练集独有的、比较个性的东西,还是希望我们的模型能够忽视它们。要求还是挺高哈,要求我们的模型有智慧,能够看懂大道,又不被小伎俩迷惑,人工智能嘛!
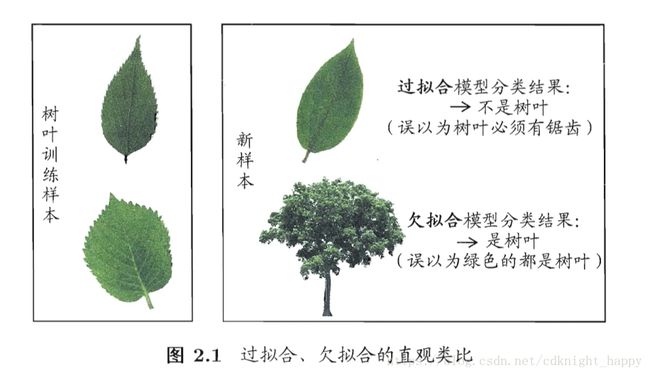
专业术语表示这个问题,就是“欠拟合”“过拟合”。“欠拟合”就是模型学习能力不足,没有学到训练集背后的普遍规律;“过拟合”就是模型学习能力太强了,把训练集的个性也当成了普遍规律。过拟合是机器学习的难点,过拟合无法避免,只能缓解。办法有正则化、dropout等等。
3.2 评估方法
通常,我们在基于训练集学习得到模型后,需要基于测试样本测试模型的性能,将测试误差作为泛化误差的近似。需要注意的是,测试样本一定是在训练样本集中从未出现过的样本,否则我们会得到过于“理想化”的测试结果。
然而我们在训练一个模型之初,能够拿到的也只有一份训练数据集,如何使用这份数据既要训练,又要测试呢?正确的方法是将训练数据集划分为训练集和测试集两部分,常见的划分方法有下面几种。
3.2.1 留出法
留出法的思想是将训练集的划分为两个不相交的子集,一部分用作训练,一部分用作测试。一般使用原数据集的70%作为训练集,剩下的30%作为测试集。
留出法需要注意的事项有:
分层采样:训练/测试集划分时要尽可能保持原有样本分布的一致性,避免采样过程引入偏差。例如原始数据集中包含500个正样本,500个负样本,那么在训练/测试样本划分时,应该保证训练集中含有350个正样本,350个负样本,而测试集中应包含150个正样本和150个负样本,这样做就避免了数据划分过程引入新的偏差。
重复计算:按照上面的例子,将500个正样本中的350个作为训练集,有 C350500 C 500 350 种选择方式,不同的训练样本集对最终的测试结果是存在一定的影响的。通常的做法是采用多次随机筛选、重复实验后取均值作为留出法的最终结果。
留出法也有一定的问题,如果训练集保留了原始数据集大部分的样本,则训练出的模型更接近于使用完整数据集训练出的模型,但此时测试集规模太小,性能评估的方差较大;而假如减小训练集样本占原始数据集样本的比例,则会造成使用该训练集和使用原始数据集训练的模型偏差较大。这个问题没有完整的解决方案,一般选择原始数据集的 23到45 2 3 到 4 5 用于训练,其余的作为测试集。
3.2.2 交叉验证
交叉验证是将数据集分为K等份,相互之间互斥且尽可能保持数据划分的一致性(各数据子集都通过分层采样方式获得)。每次选取(K-1)份数据作为训练集,剩下的那份数据作为测试集,从而可进行K次的训练和测试过程,最终返回这K次测试结果的均值作为单次交叉验证的结果,一般称其为K折交叉验证。K的常见取值为10。
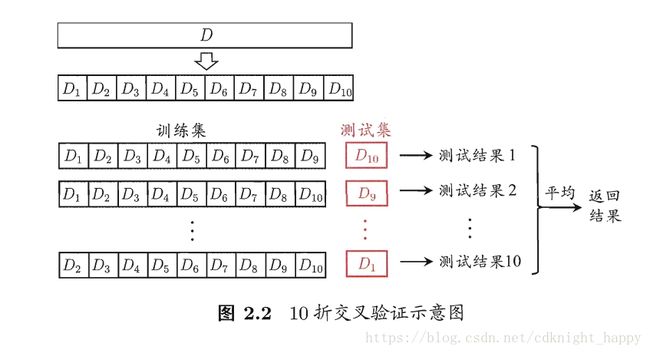
同样为了减小数据选择对最终性能的影响,很多时候还会进行多次的K折交叉验证,比如进行20次10折交叉验证,最终的测试结果为这200个测试结果的均值。
留一法:当选择K=m时,则每次只保留一个样本作为测试集,这样每次训练模型的测试集和原始数据集很接近,性能评估也比较准确,当然性能评估的波动性也比较大。留一法的优点是准确,缺点是假设m值很大时,需要训练很多个模型,计算开销比较大。
3.2.3 自助法
自助法是有放回采样,即从原始数据集中随机选取m个样本样本放入训练集中,这样原始数据集中的样本有的在训练集中多次出现,有的从而出现,将未在训练集中出现的样本作为测试集。这样做大约 23 2 3 的原始样本作为训练集使用,其余样本作为测试集。
自助法在原始数据集较小、难以有效划分训练集/测试集时较有效。但是,自助法会改变数据的原始分布,会引入额外的偏差。所以一般在样本数量较充足时经常用留出法和交叉验证法进行模型的评估。
3.2.4 验证集
机器学习任务通常包含大量的可调整的参数,即模型选择的过程除了选择机器学习算法外,还需要选择各算法最理想的参数。一般会将原始数据集中分出一部分作为验证集,基于我们自己选择的不同算法及参数在验证集上的性能进行算法和参数的选择,在确定这两者之后,再在完整的数据集上重新进行训练得到最终的机器学习模型。
一般会将数据集分出一部分作为测试集,将测试误差作为泛化误差的近似;而将剩下的数据集分为训练集和验证集两部分,基于在验证集上的性能进行模型选择和调参。
机器学习模型参数众多,取值范围很多都是实数范围,全部遍历调参不现实。合适的做法是按照固定步长选择候选值,例如某参数的取值范围为 [0,0.2] [ 0 , 0.2 ] ,以0.05为步长则有5个候选参数。这样做虽然取不到最理想的参数,但往往是计算开销和性能评估的折中,通过这个折中,学习过程才变得可行。
3.3 性能度量
性能度量是衡量模型泛化能力的标准。往往是依据预测结果 f(x) f ( x ) 与真实label y y 之间的区别进行性能度量。
3.3.1 回归任务
回归任务往往使用预测值与真实值之间的均方误差的大小作为性能度量标准。
更一般的,基于数据分布 D D 和概率密度函数 p(.) p ( . ) ,定义均方误差为:
3.3.2 分类任务
3.3.2.1 错误率/精度
错误率:
精度 = 1 - 错误率
3.3.2.2 查准率、查全率、F1
混淆矩阵
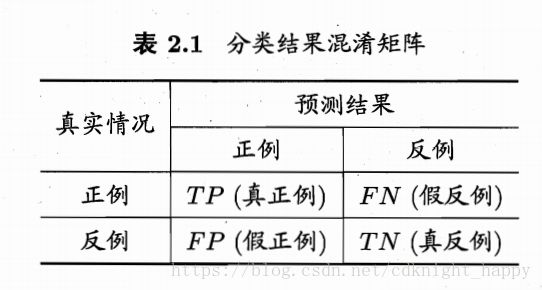
记忆技巧:两个字母,后面字母为预测结果(Positive/Negative),前面字母是预测结果是否与实际结果一致(True/False)。
FN-预测结果为Negative,与实际结果不符,因此为FN。
查准率:预测为正例的样本中有多少为真正的正例。
查全率:所有真实的正例中有多少被检索出来了。
查准率和查全率往往是一对比较矛盾的量,查全率高的时候,查准率往往较低;而查准率高的时候,查全率往往较低。以选西瓜的例子来说,如果希望把所有的好瓜都选出来,查全率很高,可以增加选瓜的数量,但此时查准率往往较低;而如果希望选的尽可能准确,则可以谨慎挑选,只选有把握的瓜,此时查准率很高,查全率则很低。
P-R曲线是衡量查准率和查全率关系的图像。P-R曲线背后隐藏了一个阈值,也就是P-R曲线上的每一点背后都隐藏着一个阈值。机器学习的一般模型做分类时,如朴素贝叶斯分类器,大于某个概率阈值则判断为正例,否则为反例。那么在每一个阈值处,都对应一对查准率和查全率。以查全率为横轴,查准率为纵轴,可以得到P-R曲线。
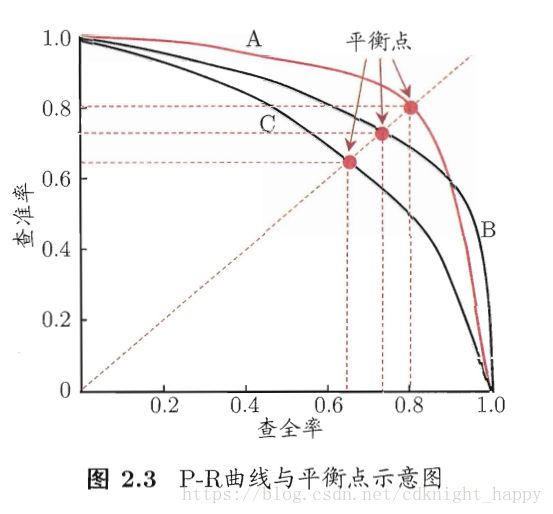
真实的P-R曲线不会像上图这样的单调平滑,现实中的P-R曲线是非单调的、不平滑的,在很多局部上有上下波动。我们自己在画P-R曲线的时候,常将各样本按照预测为正例的概率为依据由大到小进行排序。当选择最大的概率值为阈值时,此时TP=0,因此P和R都为0,即P-R曲线要经过(0,0)点;然后选择阈值为第二大的阈值,则此时第一大阈值对应的样本被预测为正例,若此时该样本的真实类别为正例,则P=1,R增大右移,若该样本的真实类别为反例,则FP=1,TP=0,因此P的取值上限减小。随着阈值的减小,整体上来看,R是在增加的,P是在减小的。因此曲线是逐渐接近(1,0)点,但不应该如上图这样到达(1,0)点,因为只有在负例样本远远大于正例样本的时候才可能到达(1,0)点。
总体而言,P-R曲线的走势是从(0,0)点开始,向上拉升接近(0,1)点,然后逐步接近(1,0)点。
如果一条P-R曲线被另一条P-R曲线完全包裹,则可以说后者的性能优于前者,如上图中的分类器A的性能优于分类器C;而假如两条P-R曲线发生了交叉,则难以断言两者的性能优劣。总体来说,P-R曲线越靠近右上角越好,但由于P-R曲线的下包面积不易计算,因此转而使用“平衡点”为标准比较两个分类器的优劣。
“平衡点”(Break-Event Point,BEP)是查准率等于查全率时值的大小,BEP的值越大,则分类器的性能越好。上图中,分类器A的BEP大小为0.8,B的BEP大小为0.72,因此认为A的性能优于B。
使用sklearn可以画P-R曲线,可以参考:http://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html#sphx-glr-auto-examples-model-selection-plot-precision-recall-py
使用平衡点度量分类器的性能还是有点简单了,常见的是使用F1为标准进行度量。F1是P和R的调和平均,越大越好,即:
有很多应用场景下,对查准率和查全率的重视程度不同,例如商品推荐系统中,需要查准率越高越好;而逃犯筛查系统中,希望查全率越高越好。因此使用F1的一般形式 Fβ F β 表达对查准率和查全率的不同的偏好,定义:
β>0 β > 0 度量了查全率对查准率的相对重要性, β>1 β > 1 查全率有更大影响, β<1 β < 1 全准率有更大影响, β=1 β = 1 是变为标准的F1。
很多时候,通过多次的训练/测试,或者在多个数据上进行训练/测试,或者执行多分类任务时,任意两个类别都得到了一个混淆矩阵,因此就得到了多个混淆矩阵。那么如何基于这n个混淆矩阵对分类器的性能进行评估呢?方法是下面的宏与微:
宏查准率、宏查全率、宏F1:
计算各分类器的查准率/查全率/F1,取其均值作为最终的结果。
微查准率、微查全率、微F1:
计算各分类器的TP、FP、FN、TN,取其均值,得到 TP¯¯¯¯¯¯¯ T P ¯ 、 FP¯¯¯¯¯¯¯¯ F P ¯ 、 FN¯¯¯¯¯¯¯¯ F N ¯ 、 TN¯¯¯¯¯¯¯¯ T N ¯ ,基于这些值计算得到微查准率/微查全率/微F1.
3.3.2.3 ROC、AUC
ROC曲线与P-R曲线相同,计算在各概率阈值下的查准率/查全率。ROC度量的是整体排序质量的好坏,体现了综合考虑学习器在不同任务下“期望泛化性能的好坏”。
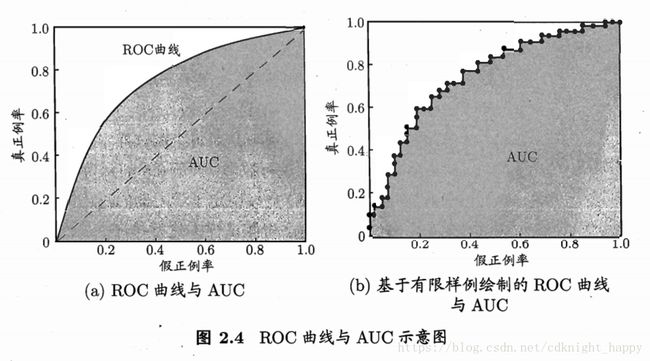
ROC曲线全称叫做“受试工作者特征”,以FPR为横轴,TPR为纵轴可以得到ROC曲线。
TPR真正例率,真正的正例样本中有多少被预测为正例;
FPR假正例率,真正的反例样本中有多少被预测为正例。
ROC曲线的画法:假设数据集中包含 m+ m + 个正例和 m− m − 个反例,基于模型对样本类别进行预测之后,将测试样本按照分类结果的置信度由高到低进行排序,首先选取最高置信度值作为阈值,此时,所有样本都为反例,TPR=FPR=0;降低阈值为第二大置信度值,此时第一大置信度阈值对应的样本被预测为正例,若该样本的真实类别为正例,则移动曲线点到 (0,1m+) ( 0 , 1 m + ) ,若该样本的真实类别为反例,则移动曲线点到 (1m−,0) ( 1 m − , 0 ) 。依次类推,得到各阈值条件下的TPR和FPR,连接各点得到ROC曲线。ROC曲线最终止于(1,1)点。
基于有限样本绘制的ROC曲线同样是不光滑的。
绘制ROC曲线:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
上左图中虚线表示随机猜测的分类器的ROC曲线,因为随机猜测时,将正例判别为反例与将反例判别为正例的几率是一致的,因此TPR约等于FPR,呈现到ROC曲线是就是(0,0)点到(1,1)点之间的对角线。如果一个分类器的ROC曲线位于对角线的左上方,表示该分类器性能优于随机猜测,如果一个分类器的ROC曲线位于对角线的右下方,表示该分类器的性能尚不如随机猜测。
ROC曲线越靠近左上角越好。最理想的状况是经过(0,1)点,此时所有的正例全部判断为正例,所有的反例无一被判断为正例,完美分类器。
与P-R曲线类似,要说一个分类器的性能优于另一个分类器,需要该分类器的ROC曲线完全包裹另一个分类器的ROC曲线,若两个分类器的ROC曲线发生交叉,则难以直接判别两者的性能优劣。合适的做法是使用AUC,AUC表示ROC曲线下的面积,AUC越大,对应的分类器性能越好。
AUC的计算公式:
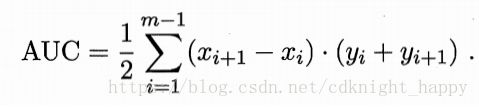
AUC评价的是排序质量的优劣,当前分类器排序造成的损失为:

正例的score小于反例的score,损失为“1”;正例的score等于反例的score,损失为“0”.
lrank l r a n k 对应的是ROC曲线上方的面积,即 lrank=1−AUC l r a n k = 1 − A U C 。
3.3.2.4 P-R曲线与ROC曲线的关系
参考自:https://blog.csdn.net/pipisorry/article/details/51788927
计算ROC的TPR 等于 计算P-R曲线时的R。
ROC曲线越靠近左上角越好,P-R曲线(也可以写成precision recall curve,PRC)越靠近右上角越好。
定理1:对于一个给定的包含正负样本的数据集,ROC空间和PR空间存在一一对应的关系,也就是说,如果recall不等于0,二者包含完全一致的混淆矩阵。我们可以将ROC曲线转化为PR曲线,反之亦然。
ROC 相对于 PRC 的优势:
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
下图是ROC曲线和Precision-Recall曲线的对比:
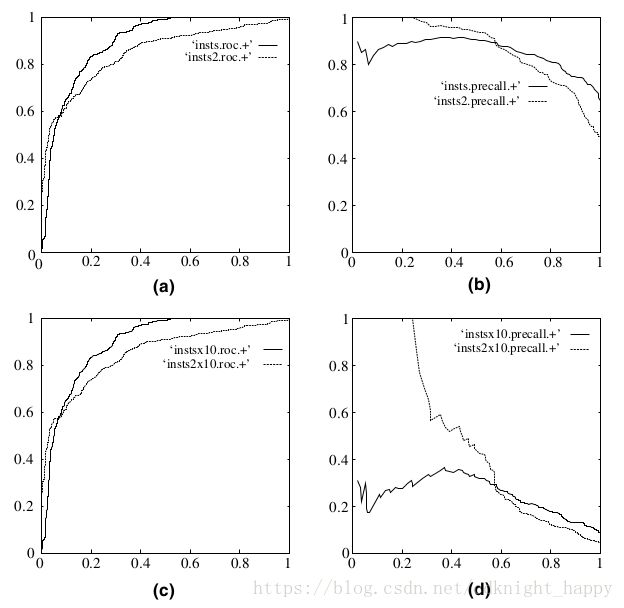
在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
解释下上面的图,ROC曲线的纵轴是TPR,横轴是FPR,当负样本的数量增加为原来的10倍后,TPR的分子、分母都不变,因此TPR不变;而FPR的分母变为原来的10倍,分子FP由于反例样本的数量变成了原来的10倍,那么FP的数量也大约会变为原来的10倍,因此FPR也几乎不变。故ROC曲线几乎保持不变。而对于PR曲线,横轴是R,纵轴是P。反例样本变为原来的10倍后,R的分子、分母都不变,R不变;而P的分子不变,分母由TP+FP变为TP+10*FP,P减小,因此可以观察到PR曲线向下方移动。
结论:ROC用得比较多的一个重要原因是,实际环境中正负样本极不均衡,PR曲线无法很好反映出分类器性能,而ROC受此影响小。
PRC相对于ROC的优势:
在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC比ROC能更有效地反应分类器的好坏。
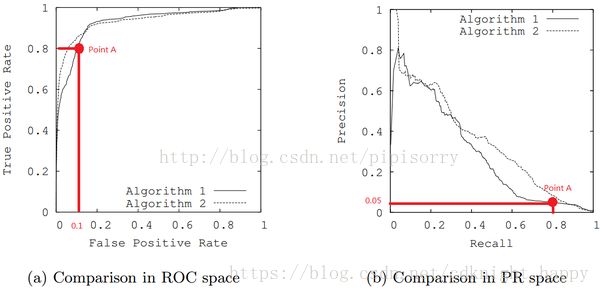
单从图a看,这两个分类器都接近完美(非常接近左上角)。图b对应着相同分类器的PR space。而从图b可以看出,这两个分类器仍有巨大的提升空间。那么原因是什么呢? 通过看Algorithm1的点 A,可以得出一些结论。首先图a和b中的点A是相同的点,只是在不同的空间里。因为TPR=Recall=TP/(TP+FN),换言之,真阳性率(TPR)和召回率(Recall)是同一个东西,只是有不同的名字。所以图a中TPR为0.8的点对应着图b中Recall为0.8的点。
假设数据集有100个positive instances。由图a中的点A,可以得到以下结论:TPR=TP/(TP+FN)=TP/actual positives=TP/100=0.8,所以TP=80。由图b中的点A,可得:Precision=TP/(TP+FP)=80/(80+FP)=0.05,所以FP=1520再由图a中点A,可得:FPR=FP/(FP+TN)=FP/actual negatives=1520/actual negatives=0.1,所以actual negatives是15200。
由此,可以得出原数据集中只有100个positive instances,却有15200个negative instances!这就是极不均匀的数据集。直观地说,在点A处,分类器将1600 (1520+80)个instance分为positive,而其中实际上只有80个是真正的positive。 我们凭直觉来看,其实这个分类器并不好。但由于真正negative instances的数量远远大约positive,ROC的结果却“看上去很美”。所以在这种情况下,PRC更能体现本质。
结论: 在negative instances的数量远远大于positive instances的data set里, PRC更能有效衡量分类器的好坏。
References:Davis, Jesse, and Mark Goadrich. “The relationship between Precision-Recall and ROC curves.” Proceedings of the 23rd International Conference on Machine Learning (ICML). ACM, 2006.
总结:
看完是不是觉得很懵逼?优势可以看成劣势。所以依lz看,如果ROC曲线面积差不多时,当然使用PRC曲线来比较两个分类算法的好坏;反之亦然。如果ROC和PRC都差不多的话那就看测试集上的PRC吧。毕竟PRC和ROC可以相互转化有很大关联的(见前面的“ROC曲线和PR曲线的关系”)。
但是lz建议在样本不均衡时最好使用ROC曲线来评估,更准确也是业内常用的。prc可能也可以,但是绝对不能只使用precision或者recall!
3.3.2.5 代价敏感错误率与代价曲线
很多的机器学习任务中,误分类造成的损失是不同的。例如,医疗中健康人误认为患者,造成的损失是浪费医疗资源,相对损失较小;而把患者误认为健康人,造成的损失是影响治疗,造成的损失较大。因此,很多时候我们要比较各分类器造成的损失的相对大小。
以二分类为例,定义代价矩阵:
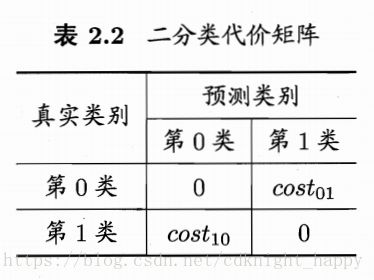
前面关于错误率的介绍都是基于均等代价的假设,因为将正例样本误分类为反例及将反例样本误分类为正例造成的损失都是同样的错误次数加1,而在非均等代价下,我们希望的不再是最小化错误次数,而是最小化错误损失。
将上图中的第0类作为正类,第1类作为负类,令 D+ D + 和 D− D − 分别表示数据集D中的正例子集和反例子集,则代价敏感错误率为:
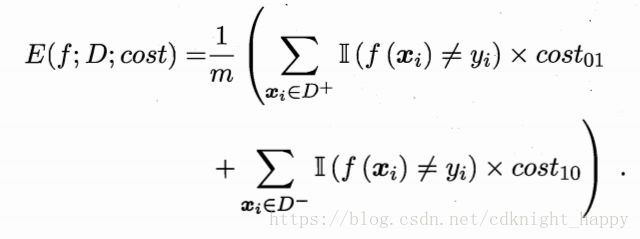
在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而代价曲线可以达到此目的。
代价曲线的横轴是正例概率代价,取值范围[0,1],p表示样本为正例的概率。
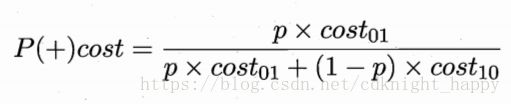
纵轴是取值为[0,1]的归一化代价:
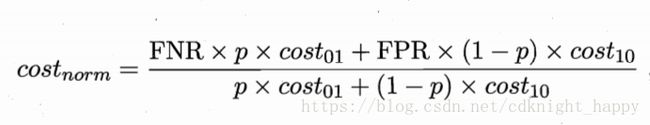
FPR就是绘制ROC曲线时的假正例率,FNR = 1 - TPR为假反例率。
代价曲线的绘制是选取ROC曲线上的每一点,得到次数的FPR、FNR,当p=0时,代价曲线横轴为0,纵轴为FPR;当p=1时,代价曲线横轴为1,纵轴为FNR,即代价曲线为(0,FPR)到(1,FNR)的连线。线段下的面积表示该条件下的期望总体代价。如此将ROC曲线上的所有点转换为代价曲线,取所有线段的下界,所围成的面积即为在所有条件下的期望总体代价。如下图所示:

3.4 比较校验
3.5 偏差与方差分解
偏差与方差分解试图对学习算法的期望泛化错误率进程拆解。
我们已经知道算法在不同测试集上的性能有可能不同,即使这些测试集独立采样自同一分布。对测试样本 x x ,令 yD y D 表示样本 x x 在数据集中的标记, y y 为x的真实标记, f(x;D) f ( x ; D ) 为训练集D上学得的模型对 x x 的预测输出。
以回归任务为例,学习算法的期望预测为:
使用样本数不同的训练集产生的方差为:
噪声为:
假定噪声的期望为0.
期望输出与真实标记之间的偏差为:
对算法的期望泛化误差进行分解:
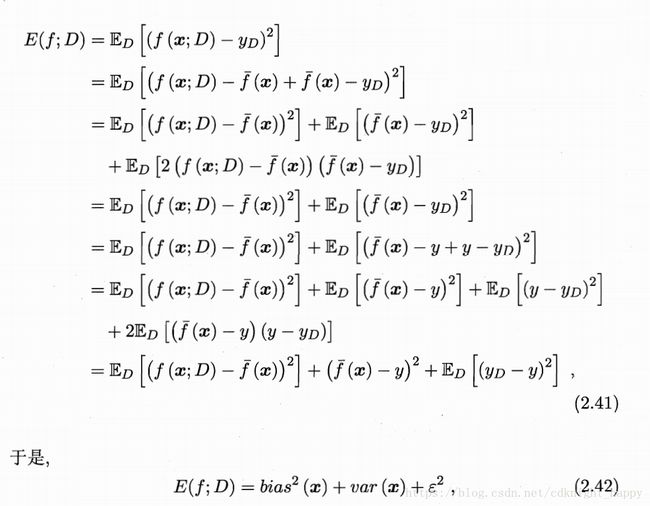
也就是说,泛化误差可以分解为偏差、方差和噪声的和。
偏差度量了学习算法的期望预测与真实结果之间的偏离程度,刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所造成的学习性能的变化,刻画了数据扰动所造成的影响;
噪声则刻画了在当前数据集上任何学习算法所能达到的期望泛化误差的下界,及学习问题本身的难以程度。
偏差-方差分解说明,泛化性能是由算法的能力、数据的充分性和问题的难易程度共同决定的。给定学习任务,为了取得好的泛化性能,需要偏差尽可能小,即算法本身具有足够的表达能力去拟合数据,同时还希望方差尽可能小,即数据扰动造成的影响尽可能小。
但比较尴尬的是,偏差和方差之间是有冲突的。给定学习算法和数据,在训练不充分时,学习器的拟合能力不足,训练数据的扰动不足以是学习器产生显著变化,此时偏差主导了错误率;随着训练程度的加深,学习器的拟合能力逐步增强,训练数据的扰动逐渐被捕捉到,方差逐渐主导了错误率;在训练充足后,学习器的拟合能力非常强,学习数据的轻微扰动都会造成学习器发生显著变化,若训练数据自身的、非全局的特性被学习到,则易于发生过拟合。

理想的状态是训练到泛化误差最小的位置,如上图中的偏差和方差两条曲线的交叉点所对应的训练程度处。
参考
周志华 《机器学习》