caffe-python lmdb 读写(转)
lmdb-write
import lmdb
import numpy as np
import cv2
import caffe
from caffe.proto import caffe_pb2
#basic setting
# 这个设置用来存放lmdb数据的目录
lmdb_file = 'lmdb_data'
batch_size = 256
# create the lmdb file
# map_size指的是数据库的最大容量,根据需求设置
lmdb_env = lmdb.open(lmdb_file, map_size=int(1e12))
lmdb_txn = lmdb_env.begin(write=True)
# 因为caffe中经常采用datum这种数据结构存储数据
datum = caffe_pb2.Datum()
item_id = -1
for x in range(1000):
item_id += 1
#prepare the data and label
#data = np.ones((3,64,64), np.uint8) * (item_id%128 + 64) #CxHxW array, uint8 or float
# pic_path设置成图像目录, 0表示读入灰度图
data = cv2.imread(pic_path, 0)
# label 设置图像的label就行
label = item_id%128 + 64
# save in datum
datum = caffe.io.array_to_datum(data, label)
keystr = '{:0>8d}'.format(item_id)
lmdb_txn.put( keystr, datum.SerializeToString() )
# write batch
if(item_id + 1) % batch_size == 0:
lmdb_txn.commit()
lmdb_txn = lmdb_env.begin(write=True)
print (item_id + 1)
# write last batch
if (item_id+1) % batch_size != 0:
lmdb_txn.commit()
print 'last batch'
print (item_id + 1)lmdb-read
import caffe
import lmdb
import numpy as np
import cv2
from caffe.proto import caffe_pb2
lmdb_env = lmdb.open('lmdb_data')
lmdb_txn = lmdb_env.begin()
lmdb_cursor = lmdb_txn.cursor()
datum = caffe_pb2.Datum()
for key, value in lmdb_cursor:
datum.ParseFromString(value)
label = datum.label
data = caffe.io.datum_to_array(datum)
#CxHxW to HxWxC in cv2
image = np.transpose(data, (1,2,0))
cv2.imshow('cv2', image)
cv2.waitKey(1)
print('{},{}'.format(key, label))lmdb数据库
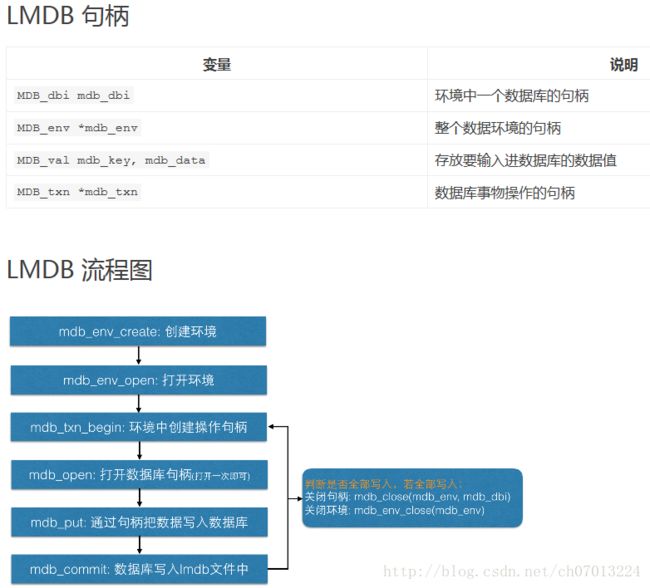
LMDB 的全称是 Lighting Memory-Mapped Database(闪电般的内存映射数据库) 。它文件结构简单,一个文件夹,里面一个数据文件,一个锁文件。数据随意复制,随意传输。它的访问简单,不需要运行单独的数据管理进程。只要在访问的代码里引用 LMDB 库,访问时给文件路径即可。
Caffe 中使用的数据较为很简单,就是大量的矩阵/向量平铺开来。数据之间没有什么关联,数据内没有复杂的对象结构,就是向量和矩阵。既然数据并不复杂,Caffe 就选择了 LMDB 这个简单的数据库来存放数据。
Caffe 中 Datum 数据结构
Caffe 并不是把向量和矩阵直接放进数据库的,而是将数据通过 caffe.proto 里定义的一个 datum 类来封装的。数据库里存放的是一个个 datum 序列化成的字符串。Datum 的定义如下:
message Datum {
optional int32 channels = 1;
optional int32 height = 2;
optional int32 width = 3;
// the actual image data, in bytes
optional bytes data = 4;
optional int32 label = 5;
// Optionally, the datum could also hold float data.
repeated float float_data = 6;
// If true data contains an encoded image that need to be decoded
optional bool encoded = 7 [default = false];
}一个 Datum 有三个维度,channnels、height、width,可以看作是少了 num 维度的 Blob。 存放数据的地方有两个:bytes data、float_data,分别存放整数型和浮点型数据。图像数据一般是整形,放在 bytes data 中,特征向量一般是浮点型,存放在 float_data 中。 label 里存放的是类别标签,是整数型。encoded 标识数据是否需要被解码,因为里面可能存放的是 JPEG 或者 PNG 之类经过编码的数据。Datum 这个数据结构将数据和标签封装在一起,兼容整形和浮点型数据。经过 protobuf 编译后,可以在 Python 和 C++ 中都提供高效的访问。 同时protobuf 还为它提供了序列化、反序列化的功能。存放进 LMDB 的就是 Datum 序列化生成的字符串。
下面通过代码来说明吧,这段代码是一个大牛写的教程:《A Practical Introduction to Deep Learning with Caffe and Python》,写的很清晰。
import os
import glob
import random
import numpy as np
import cv2
import caffe
from caffe.proto import caffe_pb2
import lmdb
#Size of images
IMAGE_WIDTH = 227
IMAGE_HEIGHT = 227
# train_lmdb、validation_lmdb 路径
train_lmdb = '/home/chenxp/Documents/vehicleID/val/train_lmdb'
validation_lmdb = '/home/chenxp/Documents/vehicleID/val/validation_lmdb'
# 如果存在了这个文件夹, 先删除
os.system('rm -rf ' + train_lmdb)
os.system('rm -rf ' + validation_lmdb)
# 读取图像
train_data = [img for img in glob.glob("/home/chenxp/Documents/vehicleID/val/query/*jpg")]
test_data = [img for img in glob.glob("/home/chenxp/Documents/vehicleID/val/query/*jpg")]
# Shuffle train_data
# 打乱数据的顺序
random.shuffle(train_data)
# 图像的变换, 直方图均衡化, 以及裁剪到 IMAGE_WIDTH x IMAGE_HEIGHT 的大小
def transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT):
#Histogram Equalization
img[:, :, 0] = cv2.equalizeHist(img[:, :, 0])
img[:, :, 1] = cv2.equalizeHist(img[:, :, 1])
img[:, :, 2] = cv2.equalizeHist(img[:, :, 2])
#Image Resizing, 三次插值
img = cv2.resize(img, (img_width, img_height), interpolation = cv2.INTER_CUBIC)
return img
def make_datum(img, label):
#image is numpy.ndarray format. BGR instead of RGB
return caffe_pb2.Datum(
channels=3,
width=IMAGE_WIDTH,
height=IMAGE_HEIGHT,
label=label,
data=np.rollaxis(img, 2).tobytes()) # or .tostring() if numpy < 1.9
# 打开 lmdb 环境, 生成一个数据文件,定义最大空间, 1e12 = 1000000000000.0
in_db = lmdb.open(train_lmdb, map_size=int(1e12))
with in_db.begin(write=True) as in_txn: # 创建操作数据库句柄
for in_idx, img_path in enumerate(train_data):
if in_idx % 6 == 0: # 只处理 5/6 的数据作为训练集
continue # 留下 1/6 的数据用作验证集
# 读取图像. 做直方图均衡化、裁剪操作
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
if 'cat' in img_path: # 组织 label, 这里是如果文件名称中有 'cat', 标签就是 0
label = 0 # 如果图像名称中没有 'cat', 有的是 'dog', 标签则为 1
else: # 这里方, label 需要自己去组织
label = 1 # 每次情况可能不一样, 灵活点
datum = make_datum(img, label)
# '{:0>5d}'.format(in_idx):
# lmdb的每一个数据都是由键值对构成的,
# 因此生成一个用递增顺序排列的定长唯一的key
in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString()) #调用句柄,写入内存
print '{:0>5d}'.format(in_idx) + ':' + img_path
# 结束后记住释放资源,否则下次用的时候打不开。。。
in_db.close()
# 创建验证集 lmdb 格式文件
print '\nCreating validation_lmdb'
in_db = lmdb.open(validation_lmdb, map_size=int(1e12))
with in_db.begin(write=True) as in_txn:
for in_idx, img_path in enumerate(train_data):
if in_idx % 6 != 0:
continue
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
if 'cat' in img_path:
label = 0
else:
label = 1
datum = make_datum(img, label)
in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString())
print '{:0>5d}'.format(in_idx) + ':' + img_path
in_db.close()
print '\nFinished processing all images'再展示一段生成 lmdb 的代码,来源自:http://deepdish.io/2015/04/28/creating-lmdb-in-python/
这段代码并没有用真实的图像数据来生成,二是用 numpy 中的 np.zeros() 生成了图像格式的数据:
import numpy as np
import lmdb
import caffe
N = 1000
# Let's pretend this is interesting data
X = np.zeros((N, 3, 32, 32), dtype=np.uint8)
y = np.zeros(N, dtype=np.int64)
# We need to prepare the database for the size. We'll set it 10 times
# greater than what we theoretically need. There is little drawback to
# setting this too big. If you still run into problem after raising
# this, you might want to try saving fewer entries in a single
# transaction.
map_size = X.nbytes * 10
env = lmdb.open('mylmdb', map_size=map_size)
with env.begin(write=True) as txn:
# txn is a Transaction object
for i in range(N):
datum = caffe.proto.caffe_pb2.Datum()
datum.channels = X.shape[1]
datum.height = X.shape[2]
datum.width = X.shape[3]
datum.data = X[i].tobytes() # or .tostring() if numpy < 1.9
datum.label = int(y[i])
str_id = '{:08}'.format(i)
# The encode is only essential in Python 3
txn.put(str_id.encode('ascii'), datum.SerializeToString())下面就是从生成好的 lmdb 中读取数据了:
import caffe
from caffe.proto import caffe_pb2
import lmdb
import cv2
import numpy as np
lmdb_env = lmdb.open('mylmdb', readonly=True) # 打开数据文件
lmdb_txn = lmdb_env.begin() # 生成处理句柄
lmdb_cursor = lmdb_txn.cursor() # 生成迭代器指针
datum = caffe_pb2.Datum() # caffe 定义的数据类型
for key, value in lmdb_cursor: # 循环获取数据
datum.ParseFromString(value) # 从 value 中读取 datum 数据
label = datum.label
data = caffe.io.datum_to_array(datum)
print data.shape
print datum.channels
image = data.transpose(1, 2, 0)
cv2.imshow('cv2.png', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
lmdb_env.close()转载自:
http://blog.csdn.net/u010167269/article/details/51915512?locationNum=5
https://www.cnblogs.com/zhonghuasong/p/7469750.html