贤者之路, Caffe转TensorRT
【引】将Caffe转TensorRT的时候,有很多自己设计的接口TensorRT库本身不支持。我们需要自己创建Plugin,本文介绍TensorRT的创建,如何自定义Plugin,和快速书写cuda函数。
【结构】
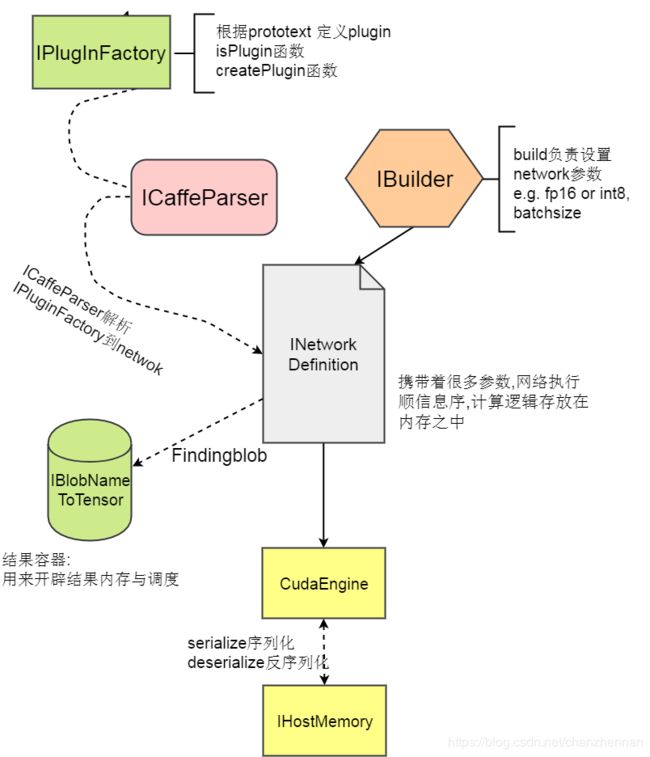
将Caffe转TensorRT的时候,有很多自己设计的接口TensorRT库本身不支持。我们需要继承TensorRT里面的IPlugin类来创建自己的Plugin。然后ICaffeParser对象会通过IPluginFacotry 解析Prototext里的网络结构,参数等信息,并将解析的信息放在内存中以便之后的计算。同时IBuilder负责设置网络数据类型(int8 FP16)batchSzie等一些通用信息。这样一个网络就被建立,网络的结构,参数都被创建在内存之中被INetworkDefinition对象所管理
【重载plugin】
class UpsampleLayer : public IPlugin
{
public:
UpsampleLayer(){}
//serilize constructure
UpsampleLayer(size_t stride):stride_(stride)
{
}
//deserilize constructure
UpsampleLayer(const void* buffer,size_t sz, size_t stride):stride_(stride)
{
/* 反序列化, 将连续放置的内存,读取到成员变量里面 */
const int* d = reinterpret_cast(buffer);
channel_=d[0];
w_=d[1];
h_=d[2];
}
// get output size infomation
inline int getNbOutputs() const override { return 1; };
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) override
{
channel_=inputs[0].d[0];
w_=inputs[0].d[1];
h_=inputs[0].d[2];
return DimsCHW(inputs[0].d[0], inputs[0].d[1]*stride_, inputs[0].d[2]*stride_);
}
int initialize() override {return 0;}
inline void terminate() override{}
inline size_t getWorkspaceSize(int) const override { return 0; }
// inference function, operation logic
int enqueue(int batchSize, const void*const *inputs, void** outputs, void*, cudaStream_t stream) override
{
Forward_gpu((float*)inputs[0],1,channel_, w_, h_, stride_, (float*)outputs[0] );
return 0;
}
//serialization size
size_t getSerializationSize() override
{
return 4*sizeof(int);
}
//serialized buffer addr
void serialize(void* buffer) override
{
int* d = reinterpret_cast(buffer);
d[0] = channel_; d[1] = w_; d[2] = h_;
d[3]=stride_;
}
//run before initialize
void configure(const Dims*inputs, int nbInputs, const Dims* outputs, int nbOutputs, int) override
{
channel_=inputs[0].d[0];
w_=inputs[0].d[1];
h_=inputs[0].d[2];
}
protected:
int stride_;
int channel_;
int w_;
int h_;
}; 模块
上面函数是一个plugin的写法,也是tensorrt引擎理解prototxt,运行运算的接口。
IPlugin类 ──── ┐───── 理解prototxt
|
└───── enqeue推理函数
【函数执行顺序】
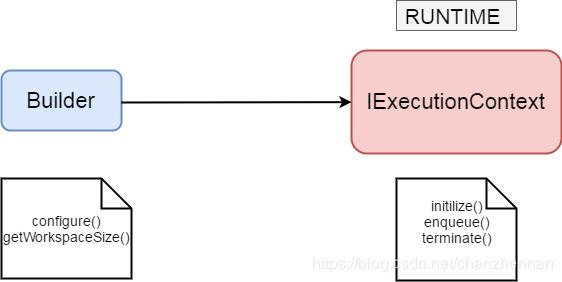
Builder最先创建网络结构,之后IExecutionContext是运行时(runtime)调用子函数。
Builder时函数:
△ Configure()先于initilize调用用来检验Layer的Input数据,又或者选择自定义的算法来处理Input数据,在一些复杂结构中还会用到卷积处理Input,如果需要runtime(实时)处理数据,应该写到plugin,序列化和反序列化函数里面。
△ 当需要存储中间结果时,可以利用共享内存的workspace(为了节省支援)。这个例子不需要用到所以getWorkspaceSize返回0。
IExecutionContext时函数:
△△△ 构造函数有两个,TileLayer()负责序列化 TileLayer(const void* buffer, size_t size)负责反序列化。
△ Initilize和terminate是运行时执行可以用于初始化算法对象如cuDNN, cuBLAS,又或者开辟中间变量内存用于计算。
△ 我们定义的网络,TensorRT需要知道每层网络的输出getNbOutputs()函数返回该层函数的Output数量,getOutputDimensions返回该层网络的Output维度。
△△△△ enqueue,Layer中最重要的运行时函数,需要编写cuda代码用于计算层中的逻辑计算
△△△△ serialization 和 deserialization 也是非常重要的函数,目的是将Layer的成员变量按连续内存方式存储(序列化)或者将一段连续内存(【e.g】 ( void ) *ptr [float0 float1 int char] ===> float a = (float*) ptr[0]; float b = ((float*)ptr + 1)[0] 等)读到类成员变量里面赋值(反序列化)
【创建TensorRT】
void caffeToGIEModel(const std::string& deployFile, // name for caffe prototxt
const std::string& modelFile, // name for model
const std::vector& outputs, // network outputs
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with)
nvcaffeparser1::IPluginFactory* pluginFactory, // factory for plugin layers
IHostMemory *&gieModelStream) // output stream for the GIE model
{
std::cout << "start parsing model..." << std::endl;
//创建build 导入glogger以便查阅日志
IBuilder* builder = createInferBuilder(gLogger);
std::cout << "start1 parsing model..." << std::endl;
//创建network对象&ICaffeParser对象
INetworkDefinition* network = builder->createNetwork();
ICaffeParser* parser = createCaffeParser();
//CafferParser解析plugin
parser->setPluginFactory(pluginFactory);
std::cout << "start2 parsing model..." << std::endl;
//builder设置网络类型
bool fp16 = builder->platformHasFastFp16();
//解析prototxt 写入network内存中
const IBlobNameToTensor* blobNameToTensor = parser->parse( deployFile.c_str(),
modelFile.c_str(),
*network,
fp16 ? DataType::kHALF : DataType::kFLOAT);
std::cout << "start3 parsing model..." << std::endl;
//根据自定义blobname在net中寻找内存地址
for (auto& s : outputs)
network->markOutput(*blobNameToTensor->find(s.c_str()));
std::cout << "start4 parsing model..." << std::endl;
//设置network通用参数
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(10 << 20);
builder->setHalf2Mode(fp16);
ICudaEngine* engine = builder->buildCudaEngine(*network);
assert(engine);
std::cout << "start5 parsing model..." << std::endl;
network->destroy();
parser->destroy();
std::cout << "start6 parsing model..." << std::endl;
//序列化网络
gieModelStream = engine->serialize();
engine->destroy();
builder->destroy();
shutdownProtobufLibrary();
std::cout << "End parsing model.qq.." << std::endl;
}
int main(int argc, char** argv) {
// create a GIE model from the caffe model and serialize it to a stream
PluginFactory pluginFactory;
IHostMemory *gieModelStream{nullptr};
caffeToGIEModel("../model_voc14/deploy.prototxt_attention",
"../model_voc14/infer.caffemodel",std::vector{AD_OUTPUT_BLOB_NAME, AD_OUTPUT_BLOB_NAME1},
1,&pluginFactory, gieModelStream);
pluginFactory.destroyPlugin();
std::cout << "staraaat deserializeCudaEngine model..." << std::endl;
// deserialize the engine
IRuntime *runtime = createInferRuntime(gLogger);
std::cout << "start deserializeCudaEngine model..." << std::endl;
ICudaEngine *engine = runtime->deserializeCudaEngine(gieModelStream->data(), gieModelStream->size(),
&pluginFactory);
std::cout << "end deserializeCudaEngine model..." << std::endl;
IExecutionContext *context = engine->createExecutionContext();
context->setProfiler(&gProfiler);
...
return 1;
} 待更新.....