TensorFlow实战4:实现简单的多层神经网络案例
这篇文章记录一下使用TensorFlow实现卷积神经网络的过程,数据集采用的还是MNIST数据集,使用了两层的卷积来进行计算,整个过程在jupyter notebook中完成,具体步骤和代码展示如下:
1.环境设定
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time1.数据准备
#使用tensorflow自带的工具加载MNIST手写数字集合
mnist = input_data.read_data_sets('./data/mnist', one_hot=True) 可以先对下载的数据信息进行一个初步的了解,有利于后面的使用
#查看一下训练数据维度
mnist.train.images.shape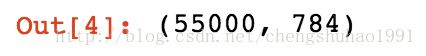
#查看target维度
mnist.train.labels.shape
2.准备好placeholder
此处先不指定每次输入数据的大小,在后面根据需要再进行指定和调整。
X = tf.placeholder(tf.float32, [None, 784], name='X_placeholder')
Y = tf.placeholder(tf.int32, [None, 10], name='Y_placeholder')3.准备好参数/权重
# 网络参数
n_hidden_1 = 256 # 第1个隐层 ,节点个数为256
n_hidden_2 = 256 # 第2个隐层
n_input = 784 # MNIST 数据输入(28*28*1=784)
n_classes = 10 # MNIST 总共10个手写数字类别
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1]), name='W1'),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]), name='W2'),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]), name='W')
}
#偏置在隐层的时候和节点个数一致,在输出层和输出类别个数一致
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1]), name='b1'),
'b2': tf.Variable(tf.random_normal([n_hidden_2]), name='b2'),
'out': tf.Variable(tf.random_normal([n_classes]), name='bias')
}4.构建网络计算graph
#此函数是用来构建计算的神经网络,得出预测类别的得分
def multilayer_perceptron(x, weights, biases):
# 第1个隐层,使用relu激活函数
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'], name='fc_1')
layer_1 = tf.nn.relu(layer_1, name='relu_1')
# 第2个隐层,使用relu激活函数
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'], name='fc_2')
layer_2 = tf.nn.relu(layer_2, name='relu_2')
# 输出层
out_layer = tf.add(tf.matmul(layer_2, weights['out']), biases['out'], name='fc_3')
return out_layer5.拿到预测类别score
pred = multilayer_perceptron(X, weights, biases)6.计算损失函数值并初始化optimizer
learning_rate = 0.001
loss_all = tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=Y, name='cross_entropy_loss')
loss = tf.reduce_mean(loss_all, name='avg_loss')
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)7.初始化变量
init = tf.global_variables_initializer()8.在session中执行graph定义的运算
#训练总轮数
training_epochs = 30
#一批数据大小
batch_size = 128
#信息展示的频度
display_step = 5
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('./graphs/MLP_DNN', sess.graph)
# 训练
for epoch in range(training_epochs):
avg_loss = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# 遍历所有的batches
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# 使用optimizer进行优化
_, l = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y})
# 求平均的损失
avg_loss += l / total_batch
# 每一步都展示信息
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", \
"{:.9f}".format(avg_loss))
print("Optimization Finished!")
# 在测试集上评估
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(Y, 1))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuracy:", accuracy.eval({X: mnist.test.images, Y: mnist.test.labels})) #此处accuracy是Tensor,在运行计算时需要用到eval()
# print("Accuracy:", sess.run(accuracy,feed_dict = {X: mnist.test.images, Y: mnist.test.labels})) #也可以用sess.run()
writer.close()最后得出的训练结果如下图所示:

以上就是用两层的神经网络来对MNIST数据集进行的分类,调整学习率以及循环次数等参数,可能会进一步提高分类的准确率。