Keras构建深度学习模型
学的东西有点儿杂,决心把keras好好的过一遍,根据《深度学习:基于Keras的Python实践》,完成小代码,以求更加了解Keras,其实应该先去学Tensorflow,但因为刚好有书,就先看这个吧
1. 建模过程
通过Keras构建深度学习模型的步骤如下:
- 定义模型:创建一个序贯模型(Sequential)并添加配置层。
这个小实践中用add函数添加层,全连接网络层用Dense类定义,需要设置网络层的神经元数量和激活函数,是一个简单的感知器。 - 编译模型:指定损失函数和优化器,并调用模型的compile()函数,完成编译。
compile函数要设置loss函数,optimizer优化器以及merics 度量模型的标准 - 训练模型:用模型的fit()函数进行训练
参数为输入数据,输出标签,迭代次数和mini_batch的大小 - 执行模型: 用模型的evaluate()或predict()等函数对新函数进行预测。
这里只是介绍步骤,所以直接用了测试集来预测,实际上应该分为验证集和测试机来进行测试。
2 简单的代码
第一个小实践是:印第安人糖尿病检测,只是为了熟悉建立模型的过程。
数据下载:https://gist.github.com/ktisha/c21e73a1bd1700294ef790c56c8aec1f#file-pima-indians-diabetes-csv
这个模型根据keras建模步骤进行了简单的实现,下面会借着聊一下模型评估的方法
# -*- coding: utf-8 -*-
"""
Created on Wed Jun 27 21:19:12 2018
@author: chili
"""
from keras import Sequential
from keras.layers import Dense
import numpy as np
np.random.seed(7) #设置随机数种子,使每次的随机数相同
#导入数据
data = np.loadtxt('./database\pima-indians-diabetes.csv',delimiter= ',') #用逗号分隔
#数据集分为输入和输出
x_ori = data[:, : -1]
y_ori = data[:, -1]
#设置输入和输出的特征维度
n_x = x_ori.shape[1]
n_y = 1
# 1.定义模型
model = Sequential()
#定义三层神经网络全连接模型,y用Dense类定义,用add函数添加层
model.add(Dense(12, input_dim = n_x, activation= 'relu')) #输入层n_x和输入,第一层有12个神经元,使用relu激活函数
model.add(Dense(8, activation= 'relu'))
model.add(Dense(1, activation= 'sigmoid')) #分类问题输出
#2 。 编译模型
model.compile(loss= 'binary_crossentropy', optimizer= 'adam', metrics= ['accuracy'])
#3. 训练模型 (简单的训练方式,没有考虑测试集)
model.fit(x = x_ori, y = y_ori, epochs= 100, batch_size= 10)
#4. 评估模型
scores = model.evaluate(x = x_ori, y = y_ori)
print ('\n%s :%.2f%%' %(model.metrics_names[1], scores[1] * 100))
结果
训练结果:没有设置验证数据集,所以只有两个错误率参数 loss 和 acc:

训练集的正确率:

3 评估深度学习模型
模型评估方法包括自动评估和手动评估,手动评估又包括手动分离训练集验证集,以及K折交叉验证
自动评估:
Keras可以将数据集的一部分分为验证集,并在每次迭代中用该验证集对模型进行评估。
实现方式是在fit()函数中设置验证分隔参数(validation_split)定义验证集占数据集的百分比来实现keras对验证集的自动选取。如下,只要在fit中加入:
#3 --- 训练升级(1):添加自动评估参数 validation_split (设置评估数据集的占整个数据集的百分比).verbose = 0时不打印详细输出
model.fit(x = x_ori, y = y_ori, epochs= 100, batch_size= 5, validation_split = 0.2,verbose = 0)输结果中还有val_loss 和 val_acc 验证集的损失函数和正确率
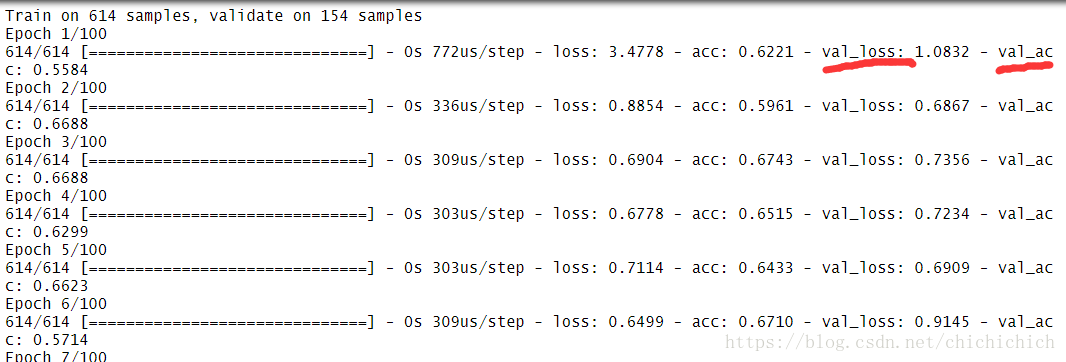
手动评估—–1
用sklearn中的train_test_split 将函数分为训练集和测试集,然后通过评估数据参数传入Keras的fit 中
#3 --- 训练升级(2):手动指定在训练期间进行验证的数据集
from sklearn.model_selection import train_test_split #导入需要的包
x_train,x_validation, y_train, y_validation = train_test_split(x_ori, y_ori, test_size = 0.2, random_state = 7)
model.fit(x_train, y_train, validation_data= (x_validation, y_validation), epochs= 100, batch_size= 10)
手动评估—-2
k折交叉验证:是学习模型评估的黄金标准,提供模型为未知数据性能的可靠估计,其过程是将数据集分为k个子集,每次训练选择其中一个子集作为验证集,其余k-1个子集为训练集,因此共建立了k个模型,用则k个模型的平均值为最终评估结果。
值得注意的是,k折交叉验证不常用于深度学习模型,因为深度学习模型计算开销大(有多好个子集就要评估多少个模型,一个深度学习模型就已经很大了,若再训练k个,会大大增加模型评估的时间开销)
使用sklearn中的StratifiedKFold 类将数据集分为k个子集。设置 fit 中verbose = 0 可以关闭模型fit时的详细输出,在每个模型构建完毕后,进行评估并输出结果,在所有模型评估完毕后,输出模型的均值和标准差。
#前面的数据预处理是一样的,只是这里要用for loop循环遍历所有子集:
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits= 10, random_state = 7, shuffle= True)# 分为10个子集,并随机打乱数据集
cvscore = []
#循环选中k个子集
for train, validation in kfold.split(x_ori, y_ori):
# 创建模型
model = Sequential()
#定义三层神经网络全连接模型,y用Dense类定义,用add函数添加层
model.add(Dense(12, input_dim = n_x, activation= 'relu')) #输入层n_x和输入,第一层有12个神经元,使用relu激活函数
model.add(Dense(8, activation= 'relu'))
model.add(Dense(1, activation= 'sigmoid')) #分类问题输出
#编译模型
model.compile(loss= 'binary_crossentropy', optimizer= 'adam', metrics= ['accuracy'])
#训练模型,传入训练集trian作为其下标
model.fit(x_ori[train], y_ori[train], epochs= 100, batch_size= 10, verbose= 0)
#评估模型
scores = model.evaluate(x_ori[validation], y_ori[validation], verbose=0)
#输出评估结果
print ('\n%s :%.2f%%' %(model.metrics_names[1], scores[1] * 100))
cvscore,append(scores[1] * 100)
#输出均值和标准差
print ('%.2f%% (+/-%.2f%%)'%(np.mean(cvscore), np.std(cvscore)))交叉验证输出结果,前10个是每个模型的输出,最后一个是均值和标准差

这个结果还不如前面的好,回头再找找原因。