Spark下的K-Means算法
Spark下的K-Means算法
引言
1.1背景
由于本人刚刚开始学习Spark平台,希望通过学习基础的Spark机器学习算法的使用来对Spark平台以及Scala语言进行一个简单的了解和使用。在这里我首先以最常见的机器学习的K-Means聚类算法。
1.2编写目的
在学习过程中,发现了有许多介绍K-Means算法原理博客和文章,也有许多关于K-Means的代码(其中包括有C、C++、Java、Scala等等),但是从项目的构建,数据的选取到最后的聚类结果,很少有对整个运行过程有一个系统的介绍。在这里我避开K-Means原理的介绍,重点阐述一下整个Spark环境上如何运行Scala的K-Means算法。
1.3参考资料
在这篇博客的编写过程中,主要参考了《kmeans算法详解与spark实战》,感谢bitcarmanlee前辈。
在项目的运行中,采用的也是博客中推荐的数据集《Wholesale customers Data Set 》
K-Means实现简介
2.1完整代码
我们采用上述注明的参考博客中的代码进行运行,具体的代码如下所示:
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
object KmeansTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("K-Means Clustering")
val sc = new SparkContext(conf)
val rawTrainingData = sc.textFile("/Users/august/Desktop/data/Kmeans/data_training")
val parsedTrainingData =
rawTrainingData.filter(!isColumnNameLine(_)).map(line => {
Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
}).cache()
val numClusters = 8
val numIterations = 30
val runTimes = 3
var clusterIndex: Int = 0
val clusters: KMeansModel =
KMeans.train(parsedTrainingData, numClusters, numIterations, runTimes)
println("Cluster Number:" + clusters.clusterCenters.length)
println("Cluster Centers Information Overview:")
clusters.clusterCenters.foreach(
x => {
println("Center Point of Cluster " + clusterIndex + ":")
println(x)
clusterIndex += 1
})
val rawTestData = sc.textFile("/Users/august/Desktop/data/Kmeans/data_training")
val parsedTestData = rawTestData.map(line => {
Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
})
parsedTestData.collect().foreach(testDataLine => {
val predictedClusterIndex:
Int = clusters.predict(testDataLine)
println("The data " + testDataLine.toString + " belongs to cluster " +
predictedClusterIndex)
})
println("Spark MLlib K-means clustering test finished.")
}
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Channel")) true
else false
}
}根据上述的代码,我们对整体运行分析如下:
2.2依赖分析
在上述代码中,程序的依赖如下所示:
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors其中调用不同的库的作用分别如下:
(1)SparkContext是Spark Driver的核心,用于连接Spark集群,创建RDD、累加器、广播变量等等。
(2)SparkConf为SparkContext的组件,是SparkContext的配置类,配置信息以键值对的形式存在。
(3)mllib.clustering是Spark Mlib库中提供的用于做聚类的依赖。
(4)mllib.linalg.Vectors是分别用来保存MLlib的本地向量的,其中包含Dense和Sparse两种分别用力来保存稠密向量和稀疏向量。
2.3属性设置
val conf = new SparkConf().setAppName("K-Means Clustering")
val sc = new SparkContext(conf)在上述代码中,我们通过SparkConf()设置程序的参数,并传递到SparkContext中。
2.4读取并分析数据
sc.textFile("/Users/august/Desktop/data/Kmeans/data_training")
val parsedTrainingData =
rawTrainingData.filter(!isColumnNameLine(_)).map(line => { Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
}).cache()在上述代码,中我们通过textFile读取聚类文件中的数据,并将数据处理转化成double类型,在数据集中数据之间通过‘,’隔开。
由于我们在UCI上下载到的数据集合中第一列是每一行属性代表的含义,我们通过isColumnNameLine(_)来进行判断。判断代码如下:
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Channel")) true
else false
}如果在该行中存在“Channel”子串,我们则不对该行进行处理。
2.5进行聚类训练
val numClusters = 8
val numIterations = 30
val runTimes = 3
var clusterIndex: Int = 0
val clusters: KMeansModel =KMeans.train(parsedTrainingData, numClusters, numIterations, runTimes)
println("Cluster Number:" + clusters.clusterCenters.length)
println("Cluster Centers Information Overview:")
clusters.clusterCenters.foreach(
x => {
println("Center Point of Cluster " + clusterIndex + ":")
println(x)
clusterIndex += 1
})根据上述代码可知,首先我们设置具体的聚类参数:
val numClusters = 8
val numIterations = 30
val runTimes = 3
var clusterIndex: Int = 0其中:numClusters = 8表示一共聚成了多少个簇,val numIterations = 30表示迭代的次数,val runTimes = 3表示运行的时间,var clusterIndex: Int = 0用来记录簇的索引。
在设置完聚类参数后,我们通过具体的代码利用KMeans.train()传入参数对数据进行聚类分析,并返回聚类模型,输出每一个簇的中心点。
val clusters: KMeansModel =KMeans.train(parsedTrainingData, numClusters, numIterations, runTimes)
println("Cluster Number:" + clusters.clusterCenters.length)
println("Cluster Centers Information Overview:")
clusters.clusterCenters.foreach(
x => {
println("Center Point of Cluster " + clusterIndex + ":")
println(x)
clusterIndex += 1
})2.6结果显示
在聚类完成后,我们再次读取数据集合中的数据信息,通过数据集合中的数据信息,并通过predict来预测每一个数据对象所属的簇。具体的代码如下所示:
val rawTestData = sc.textFile("/Users/august/Desktop/data/Kmeans/data_training")
val parsedTestData = rawTestData.map(line => {
Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
})
parsedTestData.collect().foreach(testDataLine => {
val predictedClusterIndex:
Int = clusters.predict(testDataLine)
println("The data " + testDataLine.toString + " belongs to cluster " +
predictedClusterIndex)
})数据集来源
我们通过前面引言部分给出的链接下载UCI数据集。
数据集合如下图示:
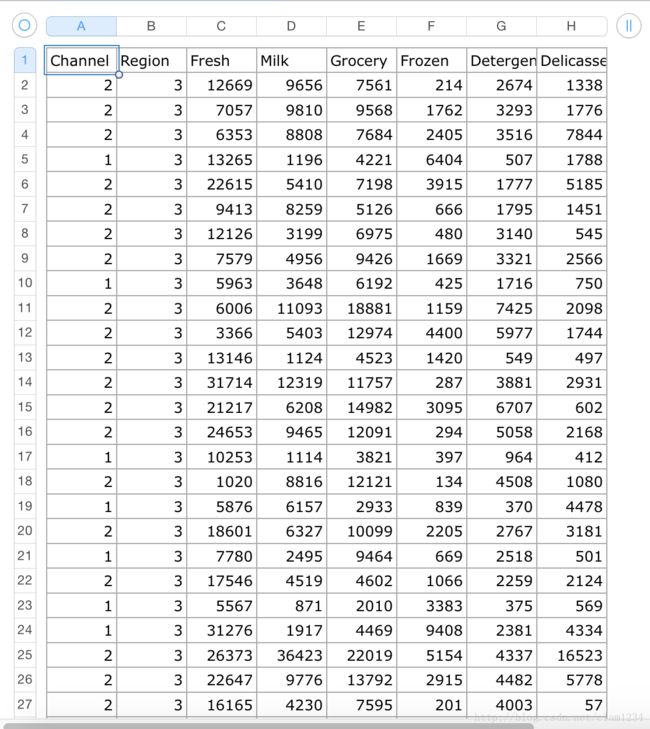
根据UCI上对数据的介绍和上图可以知道,该数据集合为8维的数据集,其中对应的不同属性分别为:
Fresh:表示在新鲜产品的年度支出上。
Milk:表示一年内在奶制产品上的消费。
GROCERY:表示一年在零食上的消费。
FROZEN:表示一年在冷冻食品上的消费
DETERGENTS_PAPER:表示一年在洗涤用品和纸上的消费。
DELICATESSEN:表示一年在熟食上的消费。
CHANNEL:表示购买的渠道:分别为团购和零售购买。
REGION:表示顾客所属的地区,分别为Lisnon, Oporto or Other
注意:在运行过程中,下载的文件为.csv文件,我们只需要把后缀名去掉,则文件中每一个数据对象的属性之间用‘,’隔开。
项目构建
4.1目录结构
我们通过find .在根目录下输出整个目录的结构如下所示:

4.2.sbt文件建立
我们在工程的根目录下建立.sbt文件,命名为simple.sbt.一般命名为build.sbt

4.3依赖文件获取
我们在程序中有对MLib机器学习库的依赖,我们通过libraryDependencies在sbt文件中注明这些依赖。
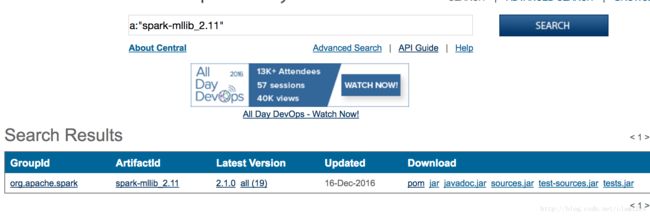
在这里我们通过:The Central Repository查询libraryDependencies的值。查询过程如下所示:
(1)输入我们依赖的库mllib,并查询得到查询结果如下所示:

(2)点击我们依赖的查询结果进入如下页面:
(3)点击Latest Version中的2.1.0进入如下界面找到Scala sbt
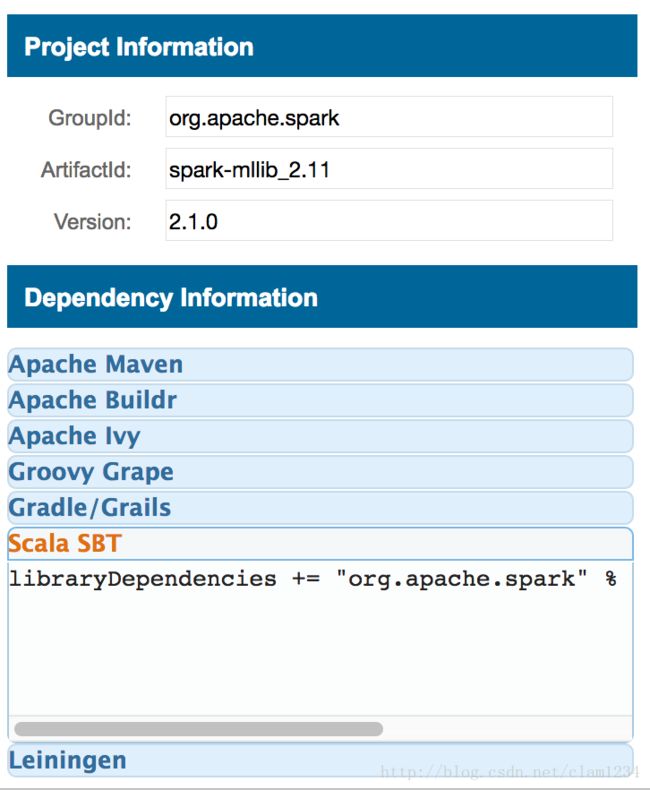
将得到的结果拷贝到sbt文件中即可。
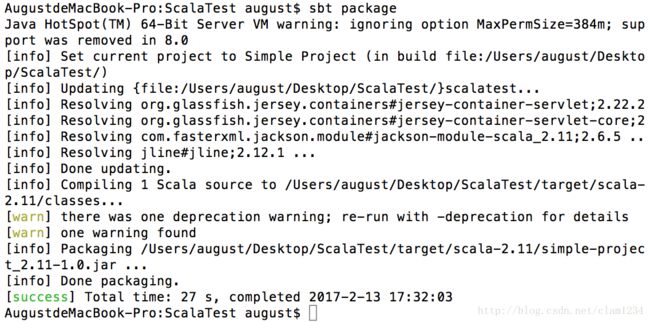
(4)然后我们在根目录通过sbt package将工程打包成jar包。可以在target目录中找到。打包后的jar包,利用spark进行运行。
测试运行
我们通过运行spark-submit提价到spark上进行运行。整个运行过程如下所示:
运行的结果如下所示:
(1)输出中心点

(2)输出每一个数据对象所属的簇

ps:在运行的时候注意数据文件所放置的位置。
点击下载对应资料。